
 Technology peripheralsAIIntegrating more than 200 related studies, the latest review of the large model 'lifelong learning' is here
Technology peripheralsAIIntegrating more than 200 related studies, the latest review of the large model 'lifelong learning' is hereIntegrating more than 200 related studies, the latest review of the large model 'lifelong learning' is here


The AIxiv column is a column for publishing academic and technical content on this site. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

Paper title: Towards Lifelong Learning of Large Language Models: A Survey Institution: South China University of Technology University Paper address: https://arxiv.org/abs/2406.06391 Project address: https://github.com/ qianlima-lab/awesome-lifelong-learning-methods-for-llm
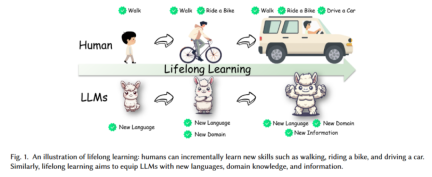
Novel classification: introduction A detailed structured framework was developed that divided the extensive literature on lifelong learning into 12 scenarios; Universal techniques: Common techniques for all lifelong learning situations were identified and present There is literature divided into different technical groups in each scenario; Future directions: Emphasis on some emerging technologies such as model extension and data selection, which were less explored in the pre-LLM era .
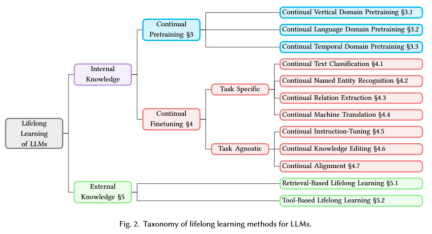
Internal knowledge refers to the absorption of new knowledge into model parameters through full or partial training, including continuous pre-training and continuous fine-tuning. -
External knowledge refers to incorporating new knowledge from external resources such as Wikipedia or application program interfaces into the model without updating the model parameters, including retrieval-based lifelong learning and Tools for lifelong learning.
Continual Vertical Domain Pretraining: for specific vertical fields (such as finance, medical etc.). Continual Language Domain Pretraining: Continuous pretraining for natural language and code language. Continual Temporal Domain Pretraining: Continuous pretraining for time-related data (such as time series data).
Task Specific:
Continuous Text Classification: For text classification tasks Continuous fine-tuning. Continual Named Entity Recognition: Continuous fine-tuning for named entity recognition tasks. Continuous Relation Extraction: Continuous fine-tuning for relation extraction tasks. Continuous Machine Translation: Continuous fine-tuning for machine translation tasks.
Task Agnostic:
Continuous Instruction-Tuning: Continuous learning of the model is achieved through instruction fine-tuning. Continuous Knowledge Editing: Continuous learning for knowledge updating. Continuous Alignment: Continuous learning to align the model with new tasks.
Overall Measurement: including Average accuracy (AA) and average incremental accuracy (AIA). AA refers to the average performance of the model after learning all tasks, while AIA takes into account the historical changes after learning each task. Stability Measurement: including forgetting measurement (FGT) and backward transfer (BWT). FGT evaluates the average performance degradation of old tasks, while BWT evaluates the average performance change of old tasks. Plasticity Measurement: including forward transfer (FWD), which is the average improvement in the model's performance on new tasks.

Meaning: This method is used when training new tasks Replay data from previous tasks to consolidate the model's memory of old tasks. Usually, the replayed data is stored in a buffer and used for training together with the data of the current task. Mainly include:
– Experience Replay: Reduce forgetting by saving a part of the data samples of old tasks and reusing these data for training when training new tasks. occurrence.
–Generative Replay: Unlike saving old data, this method uses a generative model to create pseudo-samples, thereby introducing knowledge of old tasks into the training of new tasks.
Illustration: Figure 3 shows the process from Task t-1 to Task t. The model is training Task When t, the old data in the buffer (Input t-1 ) is used.
Meaning: This method prevents the model from over-adjusting old task parameters when learning a new task by imposing regularization constraints on the model parameters. Regularization constraints can help the model retain the memory of old tasks. Mainly include:
– Weight Regularization: By imposing additional constraints on model parameters, it limits the modification of important weights when training new tasks, thereby protecting the integrity of old tasks. Knowledge. For example, L2 regularization and Elastic Weight Consolidation (EWC) are common techniques.
–Feature Regularization: Regularization can not only act on weights, but also ensure that the feature distribution between new and old tasks remains stable by limiting the performance of the model in the feature space.
Illustration: Figure 3 shows the process from Task t-1 to Task t. The model is training Task When t, parameter regularization is used to maintain performance on Task t-1.
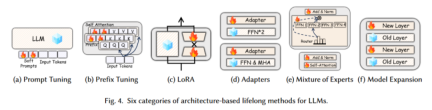
Meaning: This approach focuses on adapting the model structure to seamlessly integrate new tasks while minimizing interference with previously learned knowledge. It mainly includes the six methods in Figure 4:
–(a) Prompt Tuning: By adding "Soft Prompts" before the input of the model , to guide model generation or classification tasks. This method only requires adjusting a small number of parameters (i.e. prompt words) without changing the backbone structure of the model.
–(b) Prefix Tuning: Add trained adjustable parameters to the prefix part of the input sequence. These parameters are inserted into the self-attention mechanism of the Transformer layer to help the model better Capture contextual information.
–(c) Low-Rank Adaptation (LoRA, Low-Rank Adaptation): LoRA adapts to new tasks by adding low-rank matrices at specific levels without changing the main weights of the large model. This approach greatly reduces the number of parameter adjustments while maintaining model performance.
–(d) Adapters: Adapters are trainable modules inserted between different layers of the model. These modules can adapt with a small number of additional parameters without changing the original model weights. New tasks. Usually applied in the FFN (Feed Forward Network) and MHA (Multi-Head Attention) parts.
–(e) Mixture of Experts: Process different inputs by selectively activating certain “expert” modules, which can be specific layers or subnetworks in the model. The Router module is responsible for deciding which expert module needs to be activated.
–(f) Model Expansion: Expand the capacity of the model by adding a new layer (New Layer) while retaining the original layer (Old Layer). This approach allows the model to gradually increase its capacity to accommodate more complex task requirements.
Illustration: Figure 3 shows the process from Task t-1 to Task t. When the model learns a new task, some parameters are Frozen, while the newly added module is used to train new tasks (Trainable).
Meaning: This method transfers the knowledge of the old model to the new model through knowledge distillation. When training a new task, the new model not only learns the data of the current task, but also imitates the output of the old model for the old task, thereby maintaining the knowledge of the old task. Mainly include:
Illustration: Figure 3 shows the transition from Task t-1 to Task t In the process, when the model trains a new task, it maintains the knowledge of the old task by imitating the prediction results of the old model.
Example: CorpusBrain++ uses a backbone-adapter architecture and experience replay strategy to tackle real-world knowledge-intensive language tasks. Example: Med-PaLM introduces instruction prompt tuning in the medical field by using a small number of examples.
Example: ELLE adopts a feature-preserving model expansion strategy to improve the efficiency of knowledge acquisition and integration by flexibly expanding the width and depth of existing pre-trained language models. Example: LLaMA Pro excels in general use, programming and math tasks by extending the Transformer block and fine-tuning it with a new corpus.
-
Example: The strategy proposed by Gupta et al. adjusts the learning rate when introducing new data sets to prevent the learning rate from being too low during long-term training, thereby improving the effect of adapting to new data sets.
Example: RHO-1 is trained with a Selective Language Model (SLM), which prioritizes tokens that have a greater impact on the training process. Example: EcomGPT-CT enhances model performance on domain-specific tasks with semi-structured e-commerce data.
Example: Yadav et al. improve prompt tuning by introducing a teacher forcing mechanism, creating a set of prompts to guide the fine-tuning of the model on new tasks. Example: ModuleFormer and Lifelong-MoE use a mixture of experts (MoE) approach to enhance the efficiency and adaptability of LLM through modularity and dynamically increasing model capacity.
-
Example: The rewarming method proposed by Ibrahim et al. helps the model adapt to new languages faster by temporarily increasing the learning rate when training new data.
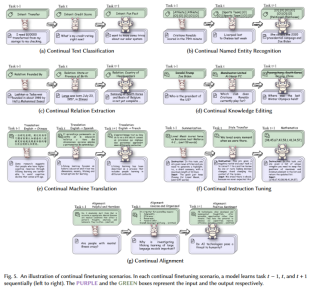
Example: Continuous text classification task trains the model by gradually introducing new classification categories (such as Intent: Transfer -> Intent: Credit Score -> Intent: Fun Fact) so that it can adapt to changing classification needs.
Example : The continuous named entity recognition task shows how to gradually introduce new entity types (such as Athlete -> Sports Team -> Politician) while recognizing specific entities, so that the model can still maintain the recognition of old entities while recognizing new entities. ability.
Example: The continuous relationship extraction task shows how the model gradually expands its relationship extraction capabilities by continuously introducing new relationship types (such as Relation: Founded By -> Relation: State or Province of Birth -> Relation: Country of Headquarters).
Example: The continuous knowledge editing task ensures that it can accurately answer the latest facts by continuously updating the model's knowledge base (such as Who is the president of the US? -> Which club does Cristiano Ronaldo currently play for? -> Where was the last Winter Olympics held?).
Example: The continuous machine translation task demonstrates the model's adaptability in a multilingual environment by gradually expanding the model's translation capabilities into different languages (such as English -> Chinese, English -> Spanish, English -> French).
Example: The continuous instruction fine-tuning task trains the model's performance capabilities in multiple task types by gradually introducing new instruction types (such as Summarization -> Style Transfer -> Mathematics).
Example: Continuous The alignment task demonstrates the model's continuous learning capabilities under different moral and behavioral standards by introducing new alignment goals (such as Helpful and Harmless -> Concise and Organized -> Positive Sentiment).
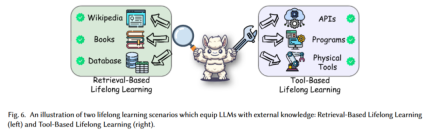
Pengenalan: Dengan peningkatan berterusan maklumat di dunia Meningkat dan berkembang dengan pantas, model statik yang dilatih mengenai data sejarah dengan cepat menjadi lapuk dan tidak dapat memahami atau menjana kandungan tentang perkembangan baharu. Pembelajaran sepanjang hayat berasaskan perolehan menangani keperluan kritikal untuk model bahasa yang besar untuk memperoleh dan mengasimilasikan pengetahuan terkini daripada sumber luar, dan model itu menambah atau mengemas kini pangkalan pengetahuannya dengan mendapatkan semula sumber luaran ini apabila diperlukan. Sumber luaran ini menyediakan pangkalan pengetahuan semasa yang besar, menyediakan aset pelengkap yang penting untuk meningkatkan sifat statik LLM terlatih. Contoh: Sumber luaran dalam rajah ini boleh diakses dan boleh diperoleh semula oleh model. Dengan mengakses sumber maklumat luaran seperti Wikipedia, buku, pangkalan data, dsb., model tersebut dapat mengemas kini pengetahuannya dan menyesuaikan diri apabila menemui maklumat baharu.
Pengenalan: Pembelajaran sepanjang hayat berasaskan alat timbul daripada keperluan untuk melanjutkan fungsinya melangkaui pengetahuan statik dan membolehkannya berinteraksi secara dinamik dengan persekitaran. Dalam aplikasi dunia nyata, model selalunya diperlukan untuk melaksanakan tugas yang melibatkan operasi di luar penjanaan teks langsung atau tafsiran. Contoh: Model dalam rajah menggunakan alatan ini untuk melanjutkan dan mengemas kini keupayaannya sendiri, membolehkan pembelajaran sepanjang hayat melalui interaksi dengan alatan luaran. Sebagai contoh, model boleh mendapatkan data masa nyata melalui antara muka pengaturcaraan aplikasi, atau berinteraksi dengan persekitaran luaran melalui alat fizikal untuk menyelesaikan tugas tertentu atau memperoleh pengetahuan baharu.
Pelupaan Malapetaka: Ini adalah salah satu cabaran teras pembelajaran sepanjang hayat, dan pengenalan maklumat baharu mungkin akan menimpa apa yang telah dipelajari oleh model sebelum ini. Dilema Kestabilan Keplastikan: Sangat penting untuk mencari keseimbangan antara mengekalkan keupayaan pembelajaran dan kestabilan model, yang secara langsung mempengaruhi keupayaan model untuk memperoleh pengetahuan baharu sambil mengekalkannya keupayaan am yang luas. Kos Pengiraan Mahal: Keperluan pengiraan untuk menyempurnakan sepenuhnya model bahasa besar boleh menjadi sangat tinggi. Ketidaksediaan pemberat model atau data pra-latihan: Disebabkan privasi, sekatan proprietari atau lesen komersial, data latihan mentah atau pemberat model selalunya tidak tersedia untuk penambahbaikan selanjutnya.
Daripada tugasan khusus kepada tugasan am: Penyelidikan secara beransur-ansur beralih daripada memfokuskan pada tugasan khusus (seperti klasifikasi teks, pengiktirafan entiti yang dinamakan) kepada pelbagai tugas umum yang lebih luas, seperti penalaan arahan, penyuntingan pengetahuan, dsb. Daripada penalaan halus penuh kepada penalaan halus separa: Memandangkan penggunaan sumber yang tinggi bagi strategi penalaan halus sepenuhnya, separa halus (seperti lapisan Penyesuai, Penalaan segera, LoRA) semakin popular. Dari pengetahuan dalaman kepada pengetahuan luaran: Untuk mengatasi batasan kemas kini dalaman yang kerap, semakin banyak strategi menggunakan sumber pengetahuan luaran, seperti Retrieval-Augmented Generation dan alat Pembelajaran membolehkan model untuk mengakses dan mengeksploitasi data luaran semasa secara dinamik.
Pembelajaran sepanjang hayat pelbagai mod: Mengintegrasikan pelbagai modaliti melangkaui teks (seperti imej, video, audio, data siri masa, graf pengetahuan) ke dalam pembelajaran sepanjang hayat untuk membangunkan model seksual yang lebih komprehensif dan adaptif. Pembelajaran sepanjang hayat yang cekap: Penyelidik sedang berusaha membangunkan strategi yang lebih cekap untuk mengurus keperluan pengiraan latihan dan kemas kini model, seperti pemangkasan model, penggabungan model, pengembangan model dan kaedah lain. Pembelajaran sepanjang hayat sejagat: Matlamat utama adalah untuk membolehkan model bahasa besar memperoleh pengetahuan baharu secara aktif dan belajar melalui interaksi dinamik dengan persekitaran, tidak lagi bergantung semata-mata pada set data statik.
The above is the detailed content of Integrating more than 200 related studies, the latest review of the large model 'lifelong learning' is here. For more information, please follow other related articles on the PHP Chinese website!

 How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AM
How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AMRunning large language models at home with ease: LM Studio User Guide In recent years, advances in software and hardware have made it possible to run large language models (LLMs) on personal computers. LM Studio is an excellent tool to make this process easy and convenient. This article will dive into how to run LLM locally using LM Studio, covering key steps, potential challenges, and the benefits of having LLM locally. Whether you are a tech enthusiast or are curious about the latest AI technologies, this guide will provide valuable insights and practical tips. Let's get started! Overview Understand the basic requirements for running LLM locally. Set up LM Studi on your computer
 Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AM
Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AMGuy Peri is McCormick’s Chief Information and Digital Officer. Though only seven months into his role, Peri is rapidly advancing a comprehensive transformation of the company’s digital capabilities. His career-long focus on data and analytics informs
 What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AM
What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AMIntroduction Artificial intelligence (AI) is evolving to understand not just words, but also emotions, responding with a human touch. This sophisticated interaction is crucial in the rapidly advancing field of AI and natural language processing. Th
 12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AM
12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AMIntroduction In today's data-centric world, leveraging advanced AI technologies is crucial for businesses seeking a competitive edge and enhanced efficiency. A range of powerful tools empowers data scientists, analysts, and developers to build, depl
 AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AM
AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AMThis week's AI landscape exploded with groundbreaking releases from industry giants like OpenAI, Mistral AI, NVIDIA, DeepSeek, and Hugging Face. These new models promise increased power, affordability, and accessibility, fueled by advancements in tr
 Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AM
Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AMBut the company’s Android app, which offers not only search capabilities but also acts as an AI assistant, is riddled with a host of security issues that could expose its users to data theft, account takeovers and impersonation attacks from malicious
 Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AM
Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AMYou can look at what’s happening in conferences and at trade shows. You can ask engineers what they’re doing, or consult with a CEO. Everywhere you look, things are changing at breakneck speed. Engineers, and Non-Engineers What’s the difference be
 Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AM
Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AMSimulate Rocket Launches with RocketPy: A Comprehensive Guide This article guides you through simulating high-power rocket launches using RocketPy, a powerful Python library. We'll cover everything from defining rocket components to analyzing simula


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Dreamweaver Mac version
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

