
 Hardware TutorialHardware ReviewWatch a 2 hour movie in 4 seconds! Alibaba releases universal multi-modal large model mPLUG-Owl3
Hardware TutorialHardware ReviewWatch a 2 hour movie in 4 seconds! Alibaba releases universal multi-modal large model mPLUG-Owl3Watch a 2 hour movie in 4 seconds! Alibaba releases universal multi-modal large model mPLUG-Owl3

After watching a 2-hour movie in 4 seconds, the Alibaba team’s new achievement was officially unveiled -
launched the general multi-modal large model mPLUG-Owl3, specially used to understand multiple pictures and long videos.

Specifically, using LLaVA-Next-Interleave as the benchmark, mPLUG-Owl3 reduced the First Token Latency of the model by 6 times, and the number of images that can be modeled by a single A100 increased by 8 times, reaching 400 With just one picture, you can watch a 2-hour movie in just 4 seconds.
In other words, the reasoning efficiency of the model has been greatly improved.
And without sacrificing the accuracy of the model.
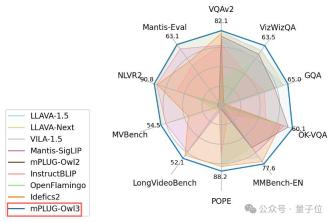
mPLUG-Owl3 also reaches SOTA in various scenarios involving multi-modal large models, including single image, multi-image, and video fields.
The author of the paper is from the Alibaba mPLUG team. They have been deeply involved in multi-modal large model bases. Before this, they also proposed:
Efficient multi-modal base mPLUG series
Modular multi-modal large language model base mPLUG -Owl Series
Document Understanding Base mPLUG-DocOwl Series
Let’s find out what black technology this release of mPLUG-Owl3 brings.
Gameplay Unlock
The team demonstrated several common uses of mPLUG-Owl3.
Multi-modal retrieval enhancement
Generally speaking, it is a common practice to supplement the knowledge that the model has not learned through the retrieval system. This requires the model to accurately understand the incoming multi-modal knowledge and use it to answer questions.
In the following example, mPLUG-Owl3 can not only respond correctly based on the retrieved knowledge, but also provide a judgment based on which piece of knowledge it is based on, and give a detailed basis for the judgment. This is very friendly to downstream R&D personnel for development and debugging.
Retrieval section: Here are several multi-modal knowledge retrieved for you to make a decision.
Question: Based on your observations of the four dog photos above, can you classify the dog in picture 5? Give reasons.
Answer: Based on observations of the four dog photos, the dog in picture 5 can be classified as an Irish Terrier. The dog in picture 1 is described as an Irish Terrier, and the dog in picture 5 has physical characteristics similar to the dog in picture 1...

Multi-picture reasoning
This often happens in life Situation -
Many users do not only have conversations around one picture, but the user may have several materials, and the model needs to be able to correctly understand the relationship between the content in different materials.
In the example below, mPLUG-Owl3 can activate the common sense knowledge of the language model through what it sees in two images, and make inferences around the two images.
Question: Can the animal on the left survive in the environment on the right? Answers and explanations are required.
Answer (the correct answer is marked green): The general idea is that it cannot survive because the environment is too cold.

In another example, mPLUG-Owl3 can not only detect the difference in style between two pictures, but also realize that although the characters in the two pictures have different styles, they are actually the same character.
First time question: What art styles are depicted in the pictures and how are they different?
Answer: The first picture is in pixel style, the second picture is in cartoon style...(give the reason)
Second question: Who appears in both pictures? What are their characteristics?
Answer: In both paintings, a man wearing a cowboy hat appears, and he is depicted in two different styles.

Long video understanding
Watching ultra-long videos is a task that most current models cannot complete end-to-end. If it is based on the Agent framework, it is difficult to guarantee the response speed.
mPLUG-Owl3 can watch a 2-hour movie and start answering user questions in 4 seconds.
Whether users are asking questions about very detailed clips at the beginning, middle and end of the movie, mPLUG-Owl3 can answer them fluently.

How did you do it?
Unlike traditional models, mPLUG-Owl3 does not need to splice the visual sequence into the text sequence of the language model in advance.
In other words, no matter what is input (dozens of pictures or hours of video), it does not occupy the language model sequence capacity, which avoids the huge computing overhead and video memory usage caused by long visual sequences.
Some people may ask, how is visual information integrated into the language model?

To achieve this, the team proposed a lightweight Hyper Attention module, which can extend an existing Transformer Block that can only model text into one that can do both graphic and text feature interaction and text construction. new module of the module.

By sparsely extending 4 Transformer Blocks throughout the entire language model, mPLUG-Owl3 can upgrade LLM to multi-modal LLM at a very small cost.
After the visual features are extracted from the visual encoder, the dimensions are aligned to the dimensions of the language model through a simple linear mapping.
Subsequently, the visual features will only interact with the text in these 4 layers of Transformer Block. Since the visual token has not undergone any compression, fine-grained information can be preserved.
Let’s take a look at how Hyper Attention is designed.
Hyper Attention In order to allow the language model to perceive visual features, a Cross-Attention operation is introduced, using the visual features as Key and Value, and using the hidden state of the language model as Query to extract the visual features.
In recent years, other research has also considered using Cross-Attention for multi-modal fusion, such as Flamingo and IDEFICS, but these works have failed to achieve good performance.
In the technical report of mPLUG-Owl3, the team compared the design of Flamingo to further explain the key technical points of Hyper Attention:
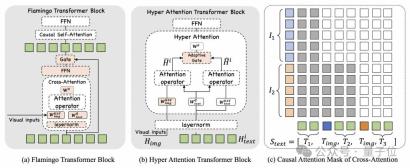
First of all, Hyper Attention does not adopt the design of Cross-Attention and Self-Attention cascades , but embedded within the Self-Attention block.
Its advantage is that it greatly reduces the number of additional new parameters introduced, making the model easier to train, and the training and inference efficiency can be further improved.
Secondly, Hyper Attention chooses LayerNorm that shares the language model, because the distribution output by LayerNorm is exactly the distribution that the Attention layer has been trained to stabilize. Sharing this layer is crucial for stable learning of the newly introduced Cross-Attention.
In fact, Hyper Attention adopts a parallel Cross-Attention and Self-Attention strategy, using a shared Query to interact with visual features, and fusing the two features through an Adaptive Gate.
This allows Query to selectively select visual features related to it based on its own semantics.
The team found that the relative position of the image and the text in the original context is very important for the model to better understand multi-modal input.
In order to model this property, they introduced a multi-modal interleaved rotation position encoding MI-Rope to model position information for the visual Key.
Specifically, they have pre-recorded the position information of each picture in the original text, and will use this position to calculate the corresponding Rope embedding, and each patch of the same picture will share this embedding.
In addition, they also introduced the Attention mask in Cross-Attention, so that the text before the image in the original context cannot see the features corresponding to the subsequent images.
In summary, these design points of Hyper Attention have brought further efficiency improvements to mPLUG-Owl3 and ensured that it can still have first-class multi-modal capabilities.

Experimental results
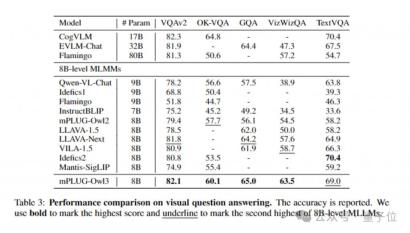
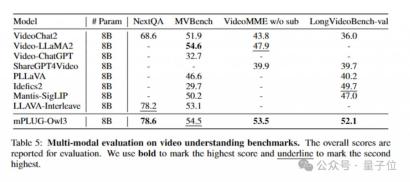
By conducting experiments on a wide range of data sets, mPLUG-Owl3 can achieve SOTA results in most single-image multi-modal Benchmarks, and even surpass those with larger model sizes in many tests. Model.
At the same time, in the multi-image evaluation, mPLUG-Owl3 also surpassed LLAVA-Next-Interleave and Mantis, which are specially optimized for multi-image scenarios.
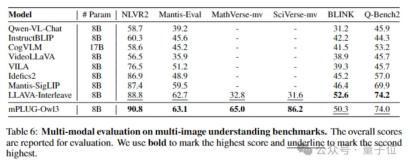
In addition, it surpasses existing models on LongVideoBench (52.1 points), a list that specifically evaluates the model's understanding of long videos.
The R&D team also proposed an interesting long visual sequence evaluation method.
As we all know, in real human-computer interaction scenarios, not all pictures serve user problems. The historical context will be filled with multi-modal content that is irrelevant to the problem. The longer the sequence, the more serious this phenomenon is.
In order to evaluate the model’s anti-interference ability in long visual sequence input, they built a new evaluation data set based on MMBench-dev.
Introduce irrelevant pictures for each MMBench cycle evaluation sample and disrupt the order of the pictures, and then ask questions about the original pictures to see whether the model can respond correctly and stably. (For the same question, 4 samples with different order of options and interference pictures will be constructed, and only one correct answer will be recorded if all answers are correct.)
The experiment is divided into multiple levels according to the number of input pictures.
It can be seen that models without multi-graph training such as Qwen-VL and mPLUG-Owl2 quickly failed.
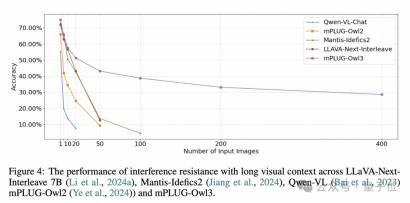
LLAVA-Next-Interleave and Mantis, which have been trained on multiple images, can maintain a similar decay curve to mPLUG-Owl3 at the beginning, but as the number of images reaches the level of 50, these models can no longer Answered correctly.
And mPLUG-Owl3 can maintain an accuracy of 40% even with 400 pictures.
However, there is one thing to say. Although mPLUG-Owl3 surpasses existing models, its accuracy is far from an excellent level. It can only be said that this evaluation method reveals the anti-interference ability of all models under long sequences that needs to be further improved in the future. .
For more details, please refer to the paper and code.
Paper: https://arxiv.org/abs/2408.04840
Code: https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl3
demo (hug face) : https://huggingface.co/spaces/mPLUG/mPLUG-Owl3
demo (Magic Community): https://modelscope.cn/studios/iic/mPLUG-Owl3
7B model (hugging face): https://huggingface.co/mPLUG/mPLUG-Owl3-7B-240728
7B model (Magic Community) https://modelscope.cn/models/iic/mPLUG-Owl3-7B-240728
— End—
Please send an email to:
ai@qbitai.com
Indicate the title and tell us:
Who are you, where are you from, the content of your submission
Attach the link to the paper/project homepage, and contact information
We will reply to you in time (try our best)
Click here to follow me and remember to star~
"Share", "Like" and "Watch" with three clicks
See you every day on the cutting-edge progress of science and technology ~
The above is the detailed content of Watch a 2 hour movie in 4 seconds! Alibaba releases universal multi-modal large model mPLUG-Owl3. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SublimeText3 Chinese version
Chinese version, very easy to use

Dreamweaver CS6
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

WebStorm Mac version
Useful JavaScript development tools

