
Home >Backend Development >Python Tutorial >Understanding Your Data: The Essentials of Exploratory Data Analysis
Understanding Your Data: The Essentials of Exploratory Data Analysis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-08-10 07:03:02655browse
Exploratory data analysis is a popular approach to analyse data sets and visually present your findings. It helps provide maximum insights into the data set and structure. This identifies exploratory data analysis as a technique to understand the various aspects of data.
For one to better understand the data one must ensure that the data is clean, has no redundancy, missing values, or even NULL values.
Types of Exploratory Data Analysis
There are three main types:
Univariate: This is where you look at one variable (column) at any single time. It helps one understand more about the variable’s nature and is termed as the easiest type of EDA.
Bivariate: This is where one looks at two variables together. It helps one understand the relationship between variables A and B whether they are independent or correlated.
Multivariate: This involves looking at three or more variables at a time. It is identified as an “advanced” bivariate.
Methods
Graphical: This involves exploring data through visual representations such as graphs and charts. Common visualisations include box plots, bar graphs, scatter plots and heat maps.
Non-graphical: This is done through statistical techniques. Metrics used include mean, median, mode, standard deviation and percentiles.
Exploratory Data Analysis Tools
Some of the most common tools used for EDA include
Python: An object oriented programming language used to connect existing components and identify missing values
R: An open source programming language used in statistical computing
Steps
- Understand the data - See what type of data you are working with; number of columns, rows, and data types.
- Clean the data – this involves working on irregularities like missing values, missing rows, and NULL values.
- Analysis – Analyse the relationship between variables.
Sample EDA using Python
The dataset in use for this example is the Iris data set - available here
- Load the data using the pandas library.
df = pd.read_csv(io.BytesIO(uploaded['Iris.csv'])) df.head()

- Identify data types df.info()
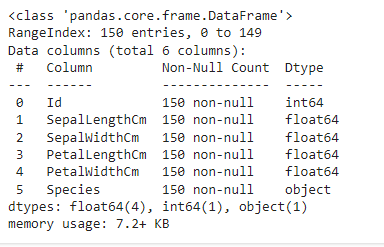
- Clean data e.g. checking for NULL values df.isnull().sum()

- Non-graphical analysis of the data to give variable info df.describe()

- Graphical analysis to show variable correlation or independence
df.plot(kind='scatter', x='SepalLengthCm', y='SepalWidthCm') ; plt.show()

The above is the detailed content of Understanding Your Data: The Essentials of Exploratory Data Analysis. For more information, please follow other related articles on the PHP Chinese website!