
 Technology peripheralsAIAfter Li Feifei's 'spatial intelligence”, Shanghai Jiao Tong University, Zhiyuan University, Peking University, etc. proposed the large spatial model SpatialBot
Technology peripheralsAIAfter Li Feifei's 'spatial intelligence”, Shanghai Jiao Tong University, Zhiyuan University, Peking University, etc. proposed the large spatial model SpatialBot

The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

Paper title: SpatialBot: Precise Depth Understanding with Vision Language Models Paper link: https://arxiv.org/abs/2406.13642 Project homepage: https://github. com/BAAI-DCAI/SpatialBot
 2. Grab the middle teacup
2. Grab the middle teacup 
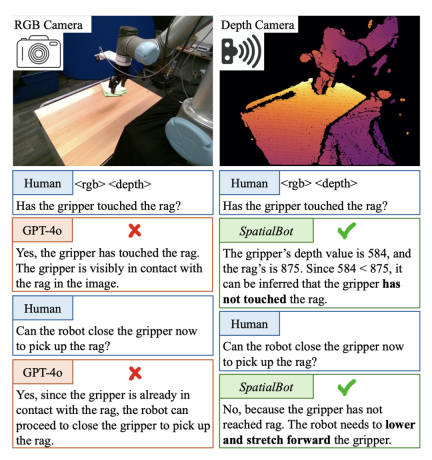
Existing models cannot directly understand the depth map input. For example, the image encoder CLIP/SigLIP is trained on RGB images without ever seeing depth maps. Most of the existing large model data sets can be analyzed and answered using only RGB. Therefore, if the existing data is simply changed to RGBD input, the model will not actively index knowledge into the depth map. Specially designed tasks and QA are required to guide the model to understand the depth map and use depth information.

低レベルでは、深度マップを理解するようにモデルをガイドし、深度マップから直接情報をガイドします。
-
中レベルでは、モデルに深度を RGB に合わせます。 高レベルでの複数の深度の設計関連タスクについては、50,000 個のデータに注釈が付けられ、モデルが深度マップの理解に基づいて深度情報を使用してタスクを完了できるようにします。タスクには、空間的な位置関係、オブジェクトのサイズ、オブジェクトが接触しているかどうか、ロボット シーンの理解などが含まれます。 - What dospatialbot contains? でのダイアログの例
1. モデルの深度マップを入力する: 屋内と屋外のタスクを考慮するために、統合された深度マップのエンコード方法が必要です。屋内のグラブやナビゲーションのタスクでは、ミリメートルレベルの精度が必要な場合があります。屋外のシーンでは、それほど正確である必要はありませんが、100 メートルを超える深度値の範囲が必要な場合があります。 Ordinal Encoding は従来のビジョン タスクのエンコードに使用されますが、Ordinal の値を加算または減算することはできません。すべての深度情報を可能な限り保存するために、SpatialBot は、1 mm から 131 m までの範囲のミリメートル単位の深度を直接使用し、uint24 または 3 チャネル uint8 を使用してこれらの値を保存します。
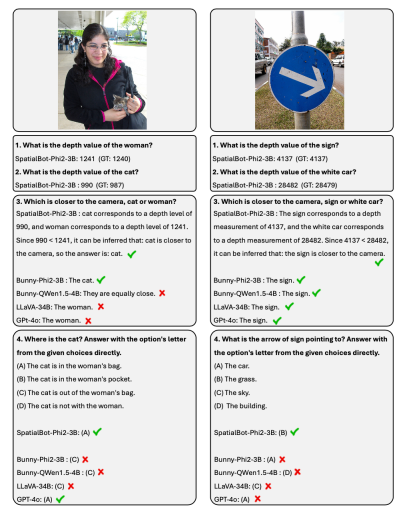
1. SpatialBot は 3B から 8B までの複数のベース LLM に基づいています。 SpatialQA で空間知識を学習することにより、SpatialBot は、一般的に使用される MLLM データセット (MME、MMBench など) でのパフォーマンスの大幅な向上も実証します。
データをマークするにはどうすればよいですか?
- 空間関係の理解と推論;
- ロボット シーンの理解: Open X 実施形態のシーン、含まれるオブジェクト、および考えられるタスクと、この記事で収集したロボット データを説明し、オブジェクトと境界ボックスに手動でラベルを付けます。ロボットの。

The above is the detailed content of After Li Feifei's 'spatial intelligence”, Shanghai Jiao Tong University, Zhiyuan University, Peking University, etc. proposed the large spatial model SpatialBot. For more information, please follow other related articles on the PHP Chinese website!

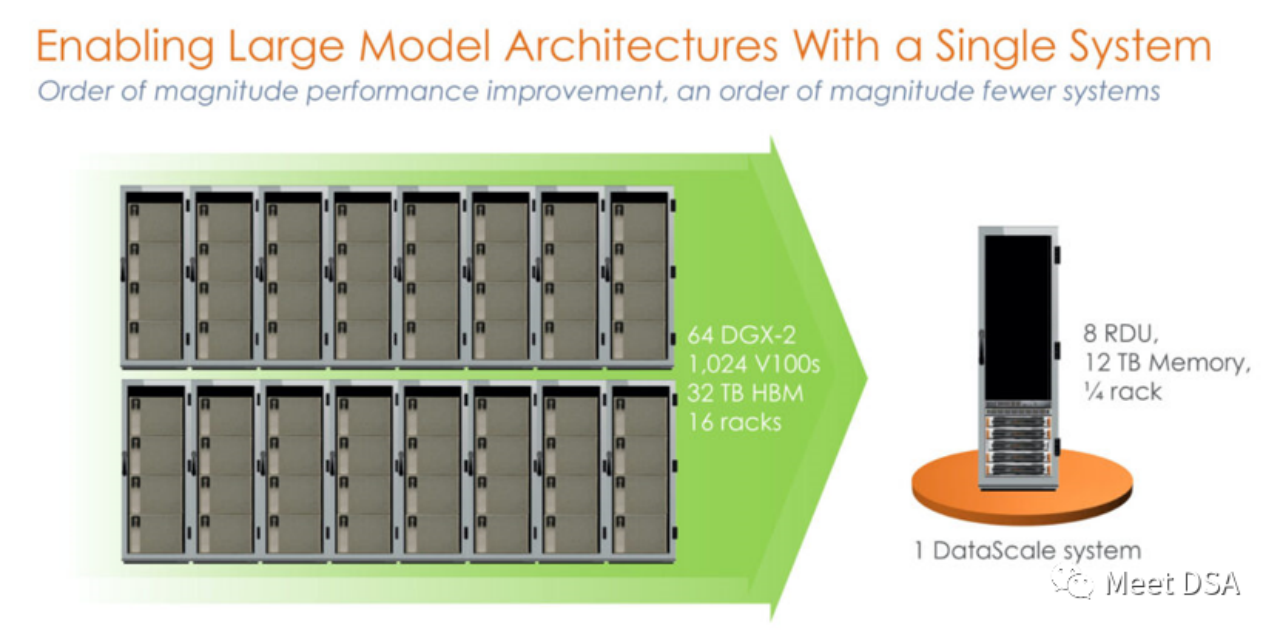 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
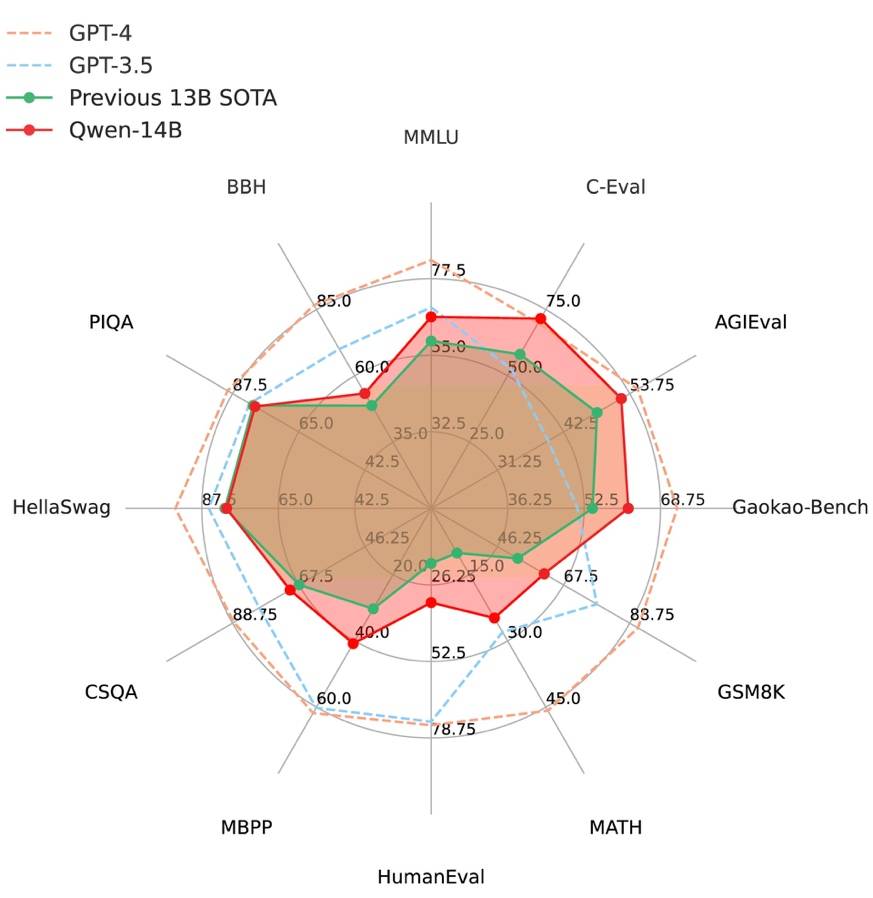 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
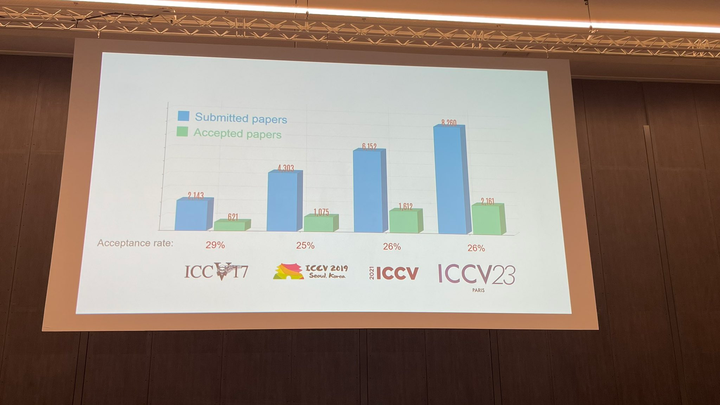 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
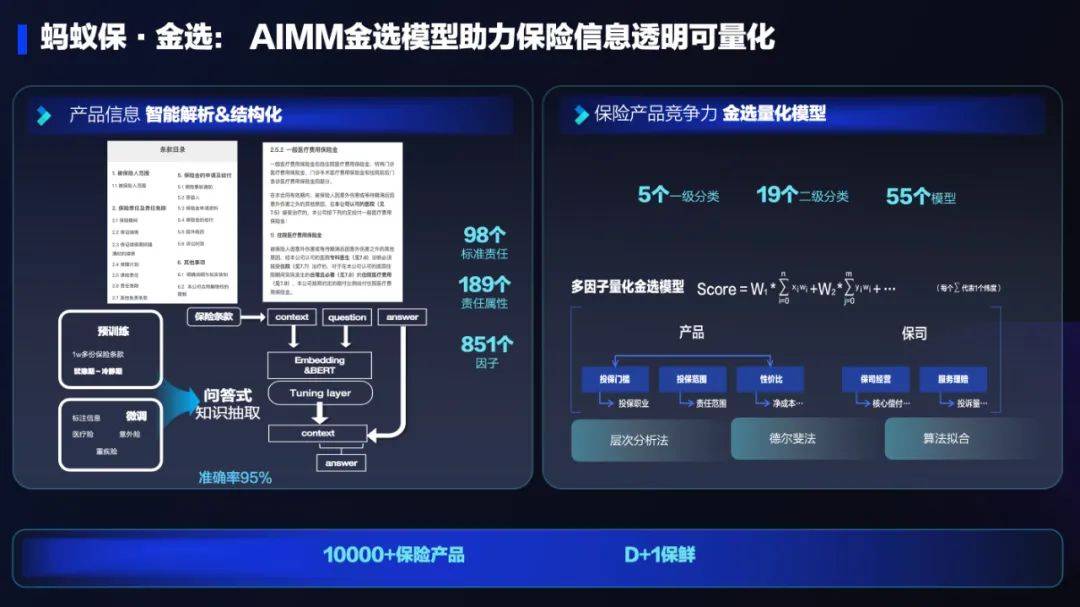 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM
快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM杭州第19届亚运会不仅是国际顶级体育盛会,更是一场精彩绝伦的中国科技盛宴。本届亚运会中,快手StreamLake与杭州电信深度合作,联合打造智慧观赛新体验,在击剑赛事的转播中,全面应用了快手StreamLake六自由度技术,其中“子弹时间”也是首次应用于击剑项目国际顶级赛事。中国电信杭州分公司智能亚运专班组长芮杰表示,依托快手StreamLake自研的4K3D虚拟运镜视频技术和中国电信5G/全光网,通过赛场内部署的4K专业摄像机阵列实时采集的高清竞赛视频,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

