
 Technology peripheralsAIThe second 'Conference on Parsimony and Learning (CPAL)' will be held at Stanford University, and the call for papers is in progress.
Technology peripheralsAIThe second 'Conference on Parsimony and Learning (CPAL)' will be held at Stanford University, and the call for papers is in progress.


The first CPAL was successfully held at the University of Hong Kong in January 2024. The conference attracted hundreds of participants from all over the world and contained four days of activities with a colorful agenda. The inaugural conference invited nine invited speakers, 16 Rising Star Award winners, and nearly a hundred accepted papers (dual track) for oral or poster presentations.
CPAL 2025
The second CPAL will be held at Stanford University at the end of March 2025, hosted by the Stanford University School of Data Science.
Vision of the conference:
"Everything should be made as simple as possible, but not any simpler." – Albert Einstein
One of the most basic reasons for the existence of intelligence or science, and even its emergence, is that the world is not perfect Random, but highly structured and predictable. Therefore, a fundamental purpose and function of intelligence or science is to learn parsimonious models (or laws) from large amounts of perceived world data to understand this predictable structure.
Over the past decade, the emergence of machine learning and large-scale computing has dramatically changed the way we process, interpret and predict data in engineering and science. The “traditional” approach to designing algorithms based on parametric models of specific signal and measurement structures (such as sparse and low-rank models), and their associated optimization toolkits, has now been greatly enriched by data-driven learning techniques, among which Large-scale networks are pretrained and then adapted to various specific tasks. However, the success of paradigms, whether modern data-driven or classical model-based, critically relies on correctly identifying the low-dimensional structures present in real data, and we consider the role of learning and compressive data processing algorithms, whether explicit or implicit , such as deep networks) are inseparable.
Recently, the emergence of foundational models has led some to suggest that parsimony and compression themselves are a fundamental part of the learning goals of intelligent systems, which connects with neuroscience's view of compression as a guiding principle in the brain's representation of perceptual data in the world. Overall, these lines of research have so far developed relatively independently, although their foundation and purpose lie in parsimony and learning. Our aim in organizing this conference is to unify the solution and further deepen the research on this problem: we want this conference to become a universal scientific forum for machine learning, applied mathematics, signal processing, optimization, intelligent systems and all related fields of science and engineering Researchers can closely communicate here, share insights, and ultimately move toward modern theoretical and computational frameworks for understanding intelligence and science from the perspective of concise learning.
Key dates:
- November 25, 2024: Conference paper submission deadline
- December 6, 2024: Tutorial proposal deadline
- December 15, 2024: "Academic Rising Star" application Deadline
- January 3-6, 2025: Paper Rebuttal
- January 4, 2025: Tutorial results release
- January 5, 2025: "Recent Focus" Article submission deadline
- 2025 January 30th: Final paper review results released
- March 24-27, 2025: Conference held at Stanford University
All deadlines are 11:00pm UTC-12:00 time zone (anywhere on Earth) 59.
Academic Rising Star "Rising Star" Encouragement Program
In order to encourage and support new forces in academia, CPAL has specially established the "Rising Star" program to discover and commend young researchers who have outstanding performance in the fields of simplicity and learning . We welcome doctoral students, postdocs, and young scholars to submit their research work. Selected “Rising Stars” will have the opportunity to present their results at the conference and gain valuable opportunities to communicate with top scholars in the field. We hope that through this program, we can inspire the innovative potential of more new generation researchers and promote the development of simplicity and learning fields.
Paper submission and subject areas
CPAL conference includes two tracks: Proceedings Track and Recent Spotlight Track. For details, please refer to the official website: https://cpal.cc/ tracks/
- "Conference Proceedings" Track (Archived): The submission and review stages are double-blind. The conference uses OpenReview to host papers and allow open discussion. A complete paper can be up to nine pages, with unlimited pages for references and appendices.
- "Recent Highlights" track (non-archived): Submit a conference-style paper (up to nine pages, with additional pages for references) describing the work. Please upload a short (250 words) abstract on OpenReview. Reviews will be conducted in a single-blind manner (authors are not required to submit anonymously).
Important innovation in the review mechanism: Each paper has a Program Chair responsible for guiding it. For each accepted paper, the names of its responsible Area Chair and Program Chair will be publicly posted on its OpenReview page to ensure accountability. For each rejected paper (excluding retractions), only the name of the responsible Program Chair is displayed. Reviewers will be rated and selected dynamically.
CPAL welcomes submissions related to the following areas of interest, including but not limited to:
- Theory and Fundamentals: Sparse coding, structured sparsity, subspace learning, low-dimensional manifolds and the theory of general low-dimensional structures. Dictionary learning and representation learning of low-dimensional structures, and their connection to deep learning theory. Equivariance and invariance modeling. Foundations of theoretical neuroscience and cognitive science, and biologically inspired computational mechanisms.
- Optimization and Algorithms: Optimization, robustness and generalization methods for learning compact and structured representations. Interpretable and efficient deep architectures (such as those based on unfolding optimization). Data-efficient and computationally efficient training and inference methods. Adaptive and robust learning and inference algorithms. Applications of distributed, networked or federated learning in large-scale environments. Other nonlinear dimensionality reduction and representation learning methods.
- Data, Systems and Applications: Domain-specific datasets, benchmarks and evaluation metrics. Learning parsimonious and structured representations from data. Inverse problems benefiting from parsimonious priors. Hardware and system co-design for parsimonious learning algorithms. Parsimonious learning integrating sense-action loops in intelligent systems. Applications in science, engineering, medicine, and social sciences.
CPAL 2025 Conference Team
General Chairs:
- Emmanuel Candès (Stanford University)
- Ma Yi (University of Hong Kong & University of California, Berkeley)
Conference Program Chair ( Program Chairs):
- Bedi Chen (Carnegie Mellon University)
- Mert Pilanci (Stanford University)
- Jeremias Sulam (Johns Hopkins University)
- Wang Yuxiang (University of California, San Diego)
Conference Advisor (Senior Advisors to Program Chairs):
- Wang Zhangyang (University of Texas at Austin)
- Qu Qing (University of Michigan)
Local Chairs (Local Chairs):
- Chen Yubei (California University of Davis)
- Sara Fridovich-Keil (Stanford University/Georgia Tech)
- Liu Sheng (Stanford University)
Publication Chairs (Publication Chairs)
- Su Weijie (University of Pennsylvania)
- Zhu Zhihui ( Ohio State University) Industry Liaison Chairs
Babak EhteShami Bejnordi Panel Chairs (Panel Chairs)
- Saiprasad Ravishankar Lei Qi (New York University)
- Liu Shiwei (Oxford University)
- William T. Redman (University of California, Santa Barbara)
Rising Stars Award Chairs (Rising Stars Award Chairs)
- Shen Liyue ( University of Michigan)
Web Chairs (Web Chairs)
- Sam Buchanan (Toyota Institute of Technology, University of Chicago)
We sincerely invite researchers in all related fields to contribute, share your research results, and promote simplicity and the development of areas of study.
The above is the detailed content of The second 'Conference on Parsimony and Learning (CPAL)' will be held at Stanford University, and the call for papers is in progress.. For more information, please follow other related articles on the PHP Chinese website!

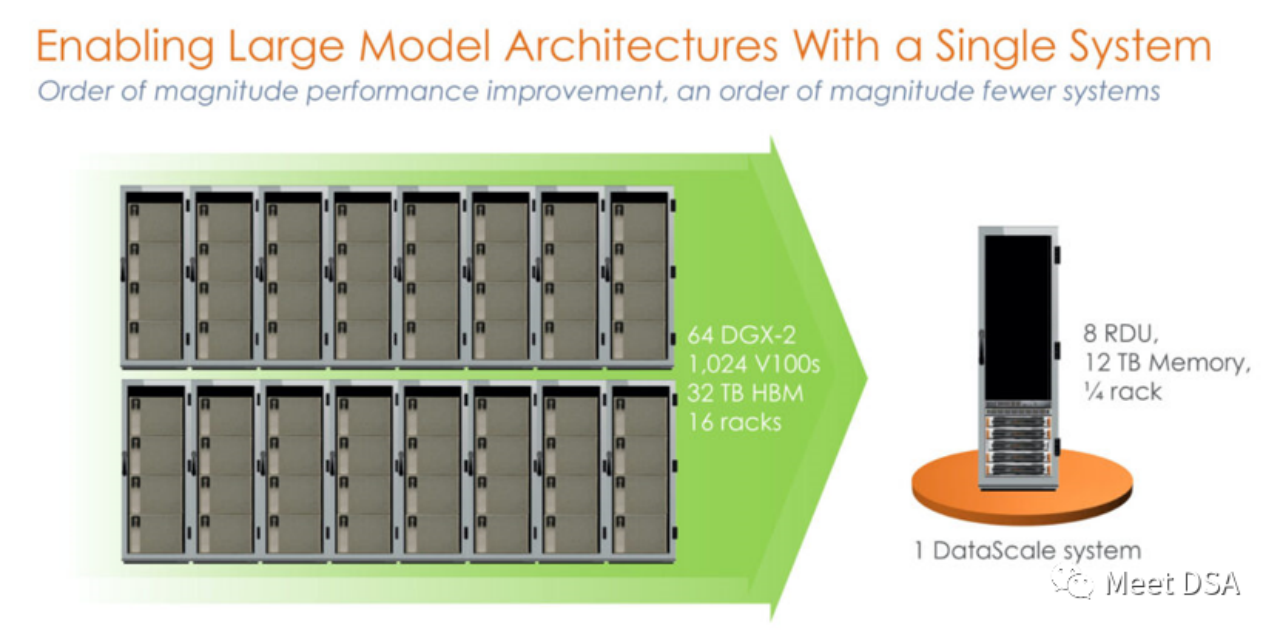 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
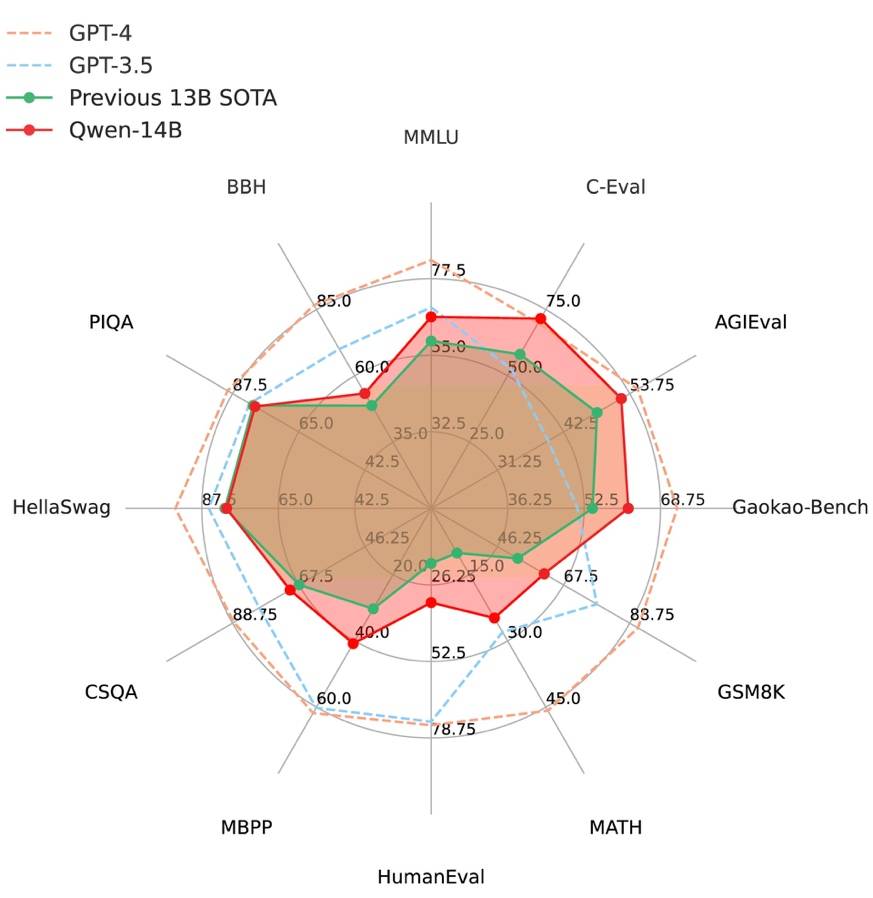 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
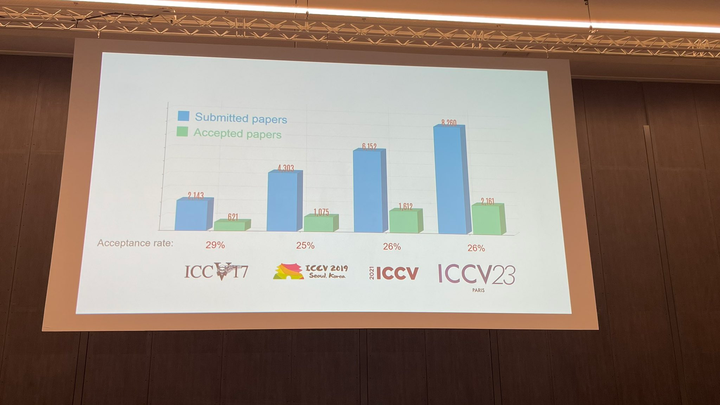 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
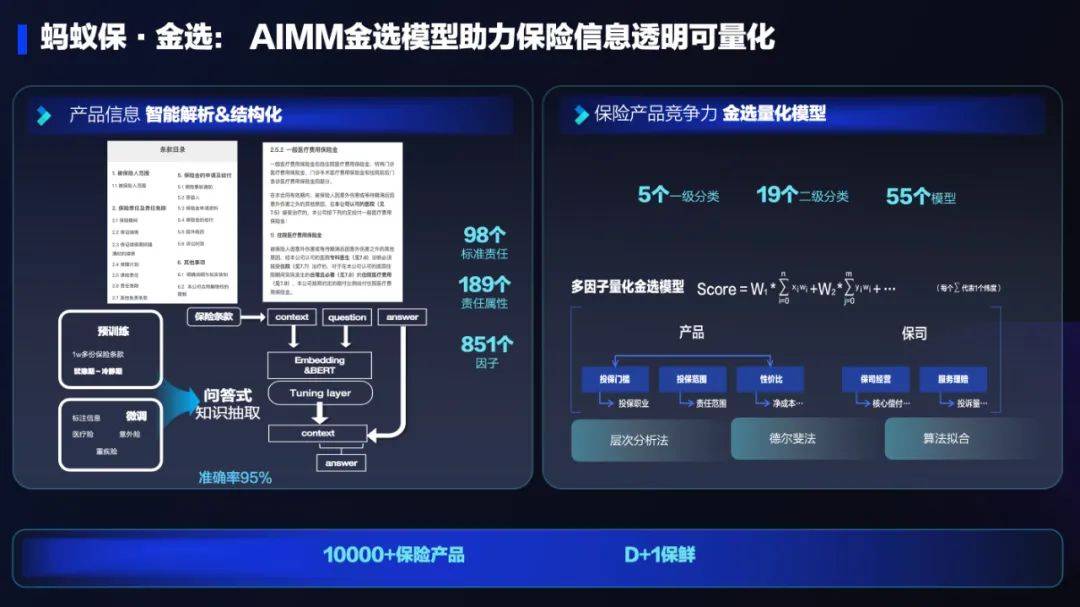 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM
快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM杭州第19届亚运会不仅是国际顶级体育盛会,更是一场精彩绝伦的中国科技盛宴。本届亚运会中,快手StreamLake与杭州电信深度合作,联合打造智慧观赛新体验,在击剑赛事的转播中,全面应用了快手StreamLake六自由度技术,其中“子弹时间”也是首次应用于击剑项目国际顶级赛事。中国电信杭州分公司智能亚运专班组长芮杰表示,依托快手StreamLake自研的4K3D虚拟运镜视频技术和中国电信5G/全光网,通过赛场内部署的4K专业摄像机阵列实时采集的高清竞赛视频,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SublimeText3 Mac version
God-level code editing software (SublimeText3)

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

