用來運行 Llama 3 405B 優勢明顯。
最近,Meta 開源了最新的 405B 模型(Llama 3.1 405B),把開源模型的性能拉到了新高度。由於模型參數量很大,許多開發者都關心一個問題:怎麼提高模型的推理速度? 時才每隔兩天,LMSYS Org 團隊就出手了,推出了全新的 SGLang Runtime v0.2。這是一個用於 LLM 和 VLM 的通用服務引擎。在運行 Llama 3.1 405B 時,它的吞吐量和延遲表現都優於 vLLM 和 TensorRT-LLM。 在某些情況下(運行 Llama 系列模型),它的吞吐量甚至能達到 TensorRT-LLM 的 2.1 倍,vLLm 的 3.8 倍。 LMSYS Org 團隊是一個由加州大學柏克萊分校、加州大學聖地牙哥分校、卡內基美隆大學的學生與教職員共同組成的公開性質的研究團體。他們所發展的大模型評測平台 ——Chatbot Arena 已成為檢驗大模型能力的重要平台,也被認為是相對公平的評測方式。 SGLang 是該團隊開發的一個用於大型語言模型和視覺語言模型的快速服務框架,於今年 1 月份正式推出,在 GitHub 上已經收穫了超過 3k 的 star 量。 
Die Wirkung dieses Updates ist erstaunlich. Der bekannte KI-Forscher, Mitbegründer und CEO von Lepton AI, Jia Yangqing, kommentierte: „Ich war immer erstaunt über meine Doktor-Alma Mater, die University of California, Berkeley, weil sie weiterhin Ergebnisse bringt.“ das fortschrittlichste künstliche Intelligenz- und Systemkollaborationsdesign. Wir haben SGLang letztes Jahr in Aktion gesehen und können es kaum erwarten, das neue SGLang in der Produktion auszuprobieren! Entwicklung und Iteration auf SGLang? Sie erwähnten in ihrem Blog: „Wir betreiben die Chatbot Arena-Plattform seit mehr als einem Jahr und stellen Dienste für Millionen von Benutzern bereit. Wir sind uns der Bedeutung effizienter Dienste für Produkte und Forschung im Bereich der künstlichen Intelligenz bewusst. Durch betriebliche Erfahrung und in.“ Nach eingehender Forschung verbessern wir weiterhin das zugrunde liegende Servicesystem, vom fortschrittlichen Multi-Modell-Service-Framework FastChat bis zur effizienten Service-Engine SGLang Runtime (SRT) „“Der Schwerpunkt dieses Artikels liegt auf SGLang Runtime Eine universelle Service-Engine für LLM und VLM. Obwohl bestehende Optionen wie TensorRT-LLM, vLLM, MLC-LLM und Hugging Face TGI ihre Vorzüge haben, fanden wir sie manchmal schwierig zu verwenden, schwierig anzupassen oder leistungsschwach veranlasste uns zur Entwicklung von SGLang v0.2, dessen Ziel es ist, eine Service-Engine zu erstellen, die nicht nur benutzerfreundlich und einfach zu ändern ist, sondern auch eine erstklassige Leistung bietet. Im Vergleich zu TensorRT-LLM und vLLM verarbeitet SGLang Runtime Modelle von Llama -8B bis Llama-405B sowie auf A100, wenn FP8 und FP16 auf H100-GPUs verwendet werden, kann es sowohl im Online- als auch im Offline-Szenario konstant eine hervorragende oder wettbewerbsfähige Leistung liefern. SGLang übertrifft vLLM durchweg und erreicht den bis zu 3,8-fachen Durchsatz von Llama-70B. Außerdem erreicht oder übertrifft es regelmäßig TensorRT-LLM und erreicht den bis zu 2,1-fachen Durchsatz des Llama-405B. Darüber hinaus ist SGLang vollständig Open Source, in reinem Python geschrieben und der Kern-Scheduler ist in weniger als 4 KB Codezeilen implementiert. SGLang ist ein Open-Source-Projekt, das unter der Apache 2.0-Lizenz lizenziert ist. Es wurde von der LMSYS Chatbot Arena verwendet, um einige Modelle, Databricks, mehrere Startups und Forschungseinrichtungen zu unterstützen, Billionen von Token zu generieren und schnellere Iterationen zu ermöglichen. Das Folgende sind die vergleichenden experimentellen Einstellungen und Ergebnisse mehrerer Frameworks. Benchmark-Setup
Die Forscher verglichen Offline- und Online-Anwendungsfälle:
Offline: Sie sendeten 2K- bis 3K-Anfragen gleichzeitig und maßen den Ausgabedurchsatz (Tokens/Sekunde). Das heißt, die Anzahl der ausgegebenen Token geteilt durch die Gesamtdauer. Der synthetische Datensatz, den sie testeten, stammte aus dem ShareGPT-Datensatz. Beispielsweise stellt I-512-O-1024 einen Datensatz mit einer durchschnittlichen Eingabe von 512 Token und einer durchschnittlichen Ausgabe von 1024 Token dar. Die fünf Testdatensätze sind: Datensatz 1: I-243-O-770;
Datensatz 2: I-295-O-770;
Datensatz 3: I-243-O-386; Datensatz 4: I-295-O-386; Datensatz 5: I-221-O-201.
-
Online: Sie senden Anfragen mit einer Rate von 1 bis 16 Anfragen pro Sekunde (RPS), was die mittlere End-to-End-Latenz misst. Sie verwenden den synthetischen Datensatz I-292-O-579.
Sie verwendeten vLLM 0.5.2 (mit Standardparametern) und TensorRT-LLM (mit empfohlenen Parametern und angepasster Batchgröße). Das Präfix-Caching ist für alle Engines deaktiviert. Der Zweck besteht darin, die Grundleistung ohne zusätzliche Funktionen wie spekulative Dekodierung oder Caching zu vergleichen. Sie verglichen SGLang und vLLM mit OpenAI-kompatiblen APIs und TensorRT-LLM mit der Triton-Schnittstelle.
Llama-8B läuft auf einem A100 (bf16)
Die Forscher begannen mit Tests mit einem kleinen Modell Llama-8B. Die folgende Grafik zeigt den maximalen Ausgabedurchsatz, den jede Engine in der Offline-Einstellung für fünf verschiedene Datensätze erreichen kann. Sowohl TensorRT-LLM als auch SGLang können einen Durchsatz von etwa 4000 Token pro Sekunde erreichen, während vLLM etwas dahinter liegt.
Die Online-Benchmark-Grafik unten zeigt ähnliche Trends wie der Offline-Fall. TensorRT-LLM und SGLang weisen eine vergleichbare Leistung auf und können RPS > 10 aufrechterhalten, während die Latenz von vLLM bei höheren Anforderungsraten deutlich zunimmt.Llama-70B running on 8 A100s (bf16) As for the larger Llama-70B model running tensor parallelism on 8 GPUs, the trend is similar to 8B. In the offline benchmarks below, both TensorRT-LLM and SGLang achieve high throughput. In the online results below, TensorRT-LLM shows lower latency thanks to efficient kernel implementation and runtime. Llama-70B running on 8 H100s (fp8) Now to test FP8 performance. Both vLLM and SGLang use CUTLASS’s FP8 kernel. In an offline setting, SGLang's batch scheduler is very efficient and can continue to scale throughput as the batch size increases, achieving the highest throughput in this case. Other systems fail to scale throughput or batch size due to OOM, lack of extensive manual tuning, or other overhead. This is also true online, where SGLang and TensorRT have similar median latencies. Llama-405B running on 8 H100s (fp8) Finally, we benchmarked the performance of various methods on the largest 405B model. Since the model is large, most of the time is spent on the GPU kernels. The gap between different frameworks is reduced. The reason for the poor performance of TensorRT-LLM may be that the 405B model has just come out, and the version used in the figure has not yet integrated some of the latest optimizations. SGLang has the best performance both online and offline. SGLang is a service framework for large-scale language models and visual language models. It is based on and enhances many of the best designs from multiple open source LLM service engines, including LightLLM, vLLM, and Guidance. It leverages high-performance attention CUDA kernels from FlashInfer and integrates torch.compile inspired by gpt-fast. In addition, researchers also introduced some innovative technologies, such as RadixAttention for automatic KV cache reuse and compressed state machine for fast constraint decoding. SGLang is known for its efficient batch scheduler implemented entirely in Python. For a fair comparison, this blog tested the base performance of these service engines with specific scenario or workload optimizations such as prefix caching and speculative decoding turned off. SGLang's speedup is achieved through proper engineering. SGLang's efficient Python-based batch scheduler scales well and is often comparable to or better than closed-source implementations built in C++. Table 1 compares various aspects of SGLang, TensorRT-LLM and vLLM. In terms of performance, both SGLang and TensorRT-LLM are excellent. In terms of usability and customizability, SGLang's lightweight and modular core makes it easy to customize, while TensorRT-LLM's complex C++ technology stack and setup instructions make it more difficult to use and modify. The source code of SGLang is fully open source, while TensorRT-LLM is only partially open source. In comparison, vLLM has higher CPU scheduling overhead. The researchers also said that in the future they will also develop new features such as long context and MoE optimization.You can easily serve the Llama model by following the steps below: 1. Install SGLang using pip, source code or Docker: https://github.com/sgl -project/sglang/tree/main?tab=readme-ov-file#install# Llama 8Bpython -m sglang.launch_server --model-path meta-llama/Meta-Llama-3.1-8B-Instruct# Llama 405Bpython -m sglang.launch_server --model-path meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 --tp 8
3. Use the OpenAI compatible API to send a request: curl http://localhost:30000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "default","prompt": "Say this is a test","max_tokens": 7,"temperature": 0 }' 4. Running the benchmark: python3 -m sglang.bench_serving --backend sglang --num-prompts 1000
Appendix: Detailed benchmark setup Instructions for reproducing the benchmark are located at sglang/benchmark/blog_v0_2. For all benchmarks, the researchers set ignore_eos or min_length/end_id to ensure that each engine outputs the same number of tokens. They tried using vLLM 0.5.3.post1 but it crashed frequently under high load and vLLM 0.5.3.post1 performance seemed to be about the same or worse compared to vLLM 0.5.2 in some benchmarks. Therefore, they report results for vLLM 0.5.2. Although they knew that different server configurations could have a significant impact on service performance, they mainly used the default parameters of each engine to simulate the situation of ordinary users. For the 8B and 70B models, they use meta-llama/Meta-Llama-3-8B-Instruct and meta-llama/Meta-Llama-3-70B-Instruct bf16 checkpoints, as well as neuralmagic/Meta-Llama -3-70B-Instruct-FP8 fp8 checkpoint. For the 405B model, they used dummy weights in all benchmarks. Since TensorRT-LLM latest image r24.06 does not support fbgemm_fp8 quantization in the official meta-llama/Meta-Llama-3.1-405B-FP8 checkpoint, they use per-layer fp8 quantization in all frameworks, and do not support lm_head except fbgemm_fp8 quantization. All layers were quantified. They believe this allows for a fair comparison of all engines. A100 and H100 GPUs are 80GB SXM versions. Reference link: https://lmsys.org/blog/2024-07-25-sglang-llama3/The above is the detailed content of Liked by Jia Yangqing: SGLang with 3K stars is released, accelerating Llama 405B inference and killing vLLM and TensorRT-LLM in seconds. For more information, please follow other related articles on the PHP Chinese website!
Statement
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn

 Technology peripherals
Technology peripherals












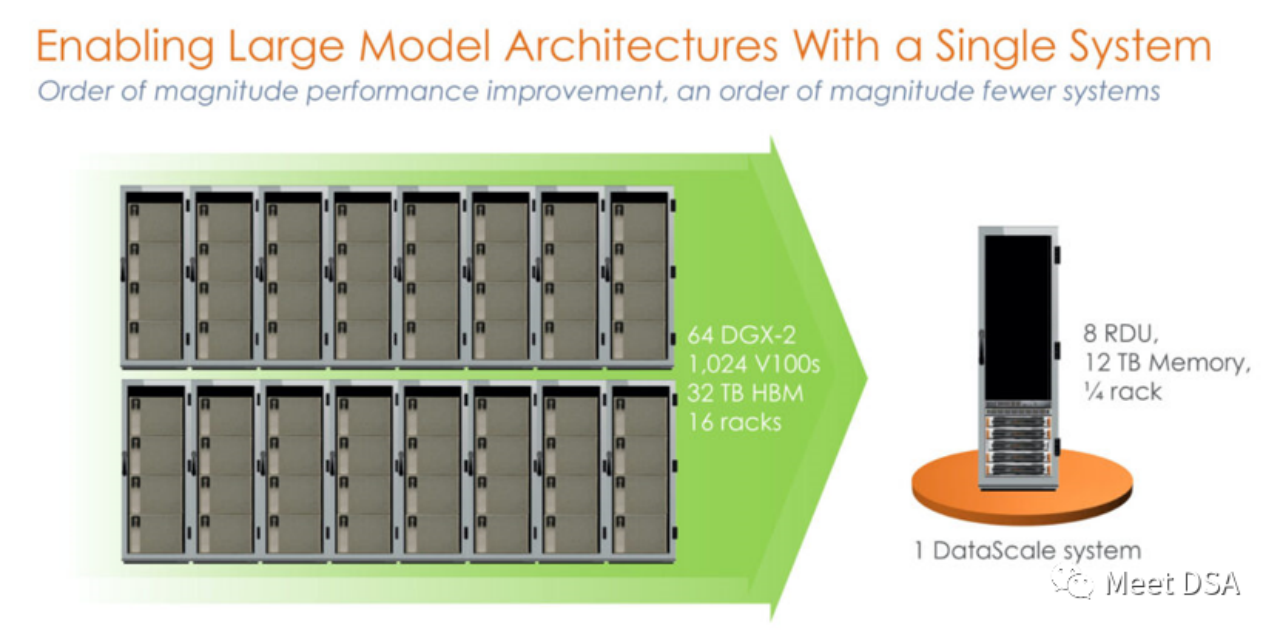 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM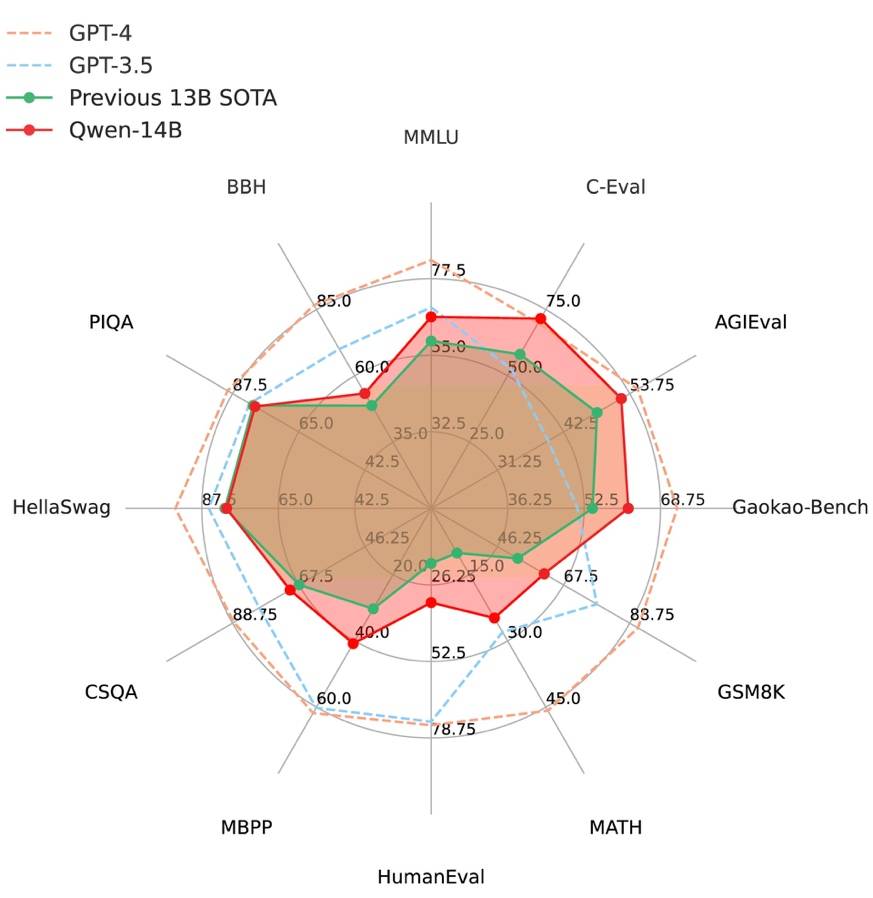 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM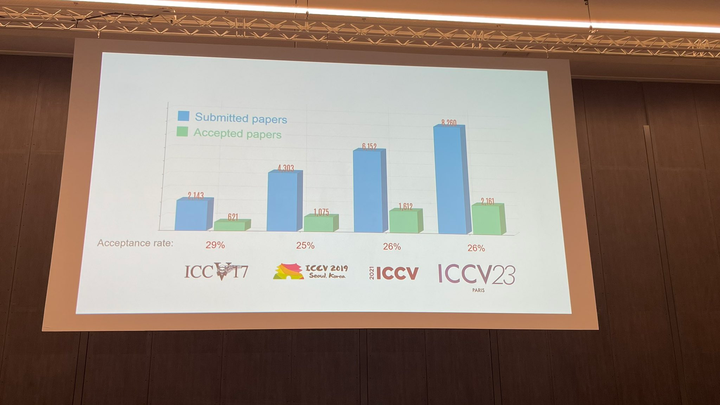 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM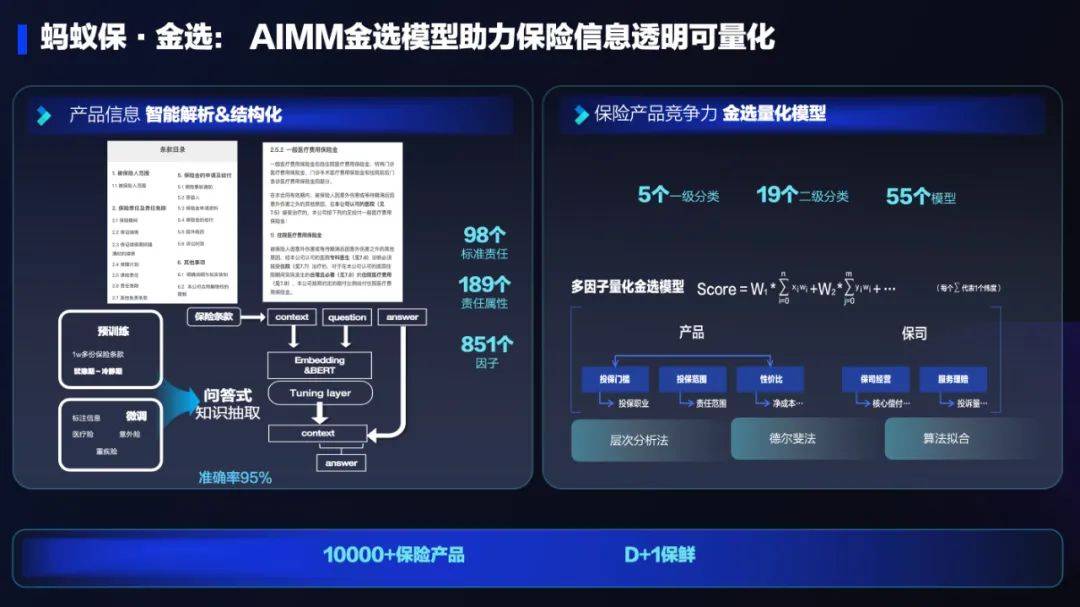 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM 快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM
快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM













