
 Technology peripheralsAI7B's most powerful long video model! LongVA video understanding exceeds 1,000 frames, dominating multiple lists
Technology peripheralsAI7B's most powerful long video model! LongVA video understanding exceeds 1,000 frames, dominating multiple lists7B's most powerful long video model! LongVA video understanding exceeds 1,000 frames, dominating multiple lists


The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
The main authors of this article are from the LMMs-Lab team and Nanyang Technological University, Singapore. In the joint work, Zhang Peiyuan is a research assistant at Nanyang Technological University, Zhang Kaichen is a fourth-year undergraduate student at Nanyang Technological University, and Li Bo is a third-year doctoral student at Nanyang Technological University. The supervisor is Professor Liu Ziwei from MMLab@NTU. LMMs-Lab is a team composed of students, researchers and teachers, dedicated to the research of multi-modal models. The main research directions include the training and comprehensive evaluation of multi-modal models. Previous work includes the multi-modal evaluation framework lmms- eval etc.
Why is it said that understanding long videos is as difficult as “finding a needle in a haystack”?
A major challenge faced by existing LMMs when processing long videos is the excessive number of visual tokens. For example, LLaVA-1.6 can generate 576 to 2880 visual tokens for a single image. The more frames the video has, the greater the number of tokens. Although BLIP2, LLaMA-VID, Chat-UniVI and other work reduce the number of visual tokens by changing the connection layer between ViT and language model, they still cannot handle a particularly large number of frames.
In addition, the lack of high-quality long video data sets is also a major bottleneck. Existing training datasets are mostly short videos within 1 minute, and even if there are long videos, the annotated text pairs are limited to a few frames of the video, lacking dense supervision signals.
Recently, research teams from LMMs-Lab, Nanyang Technological University and other institutions launched the LongVA long video model, which can understand more than a thousand frames of video data, surpassing the performance of current open source video multi-modal models!

Paper link: https://arxiv.org/abs/2406.16852
Demo address: https://longva-demo.lmms-lab.com/
Code address: https ://github.com/EvolvingLMMs-Lab/LongVA
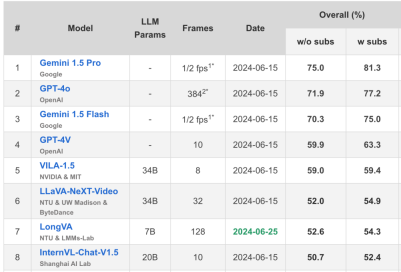
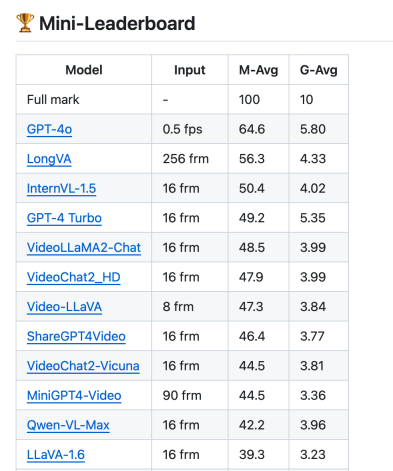
The author team proposed Long Context Transfer (Long Context Transfer) for the first time in the multi-modal field. This technology enables multi-modal large models (LMMs) to be processed without In the case of long video training, process and understand extremely long videos. Their new model LongVA can process 2000 frames or more than 200,000 visual tokens, achieving a 7B scale SoTA on the video understanding list Video-MME. In the latest long video MLVU list, LongVA is the strongest model after GPT4-o!
The author of LongVA summarized the picture below. It can be seen that the current multi-modal large model is not satisfactory in understanding long videos. The number of frames that can be processed limits the processing and understanding of long videos. In order to process more frames, work such as LLaMA-VID has to drastically compress the number of tokens corresponding to a single frame.
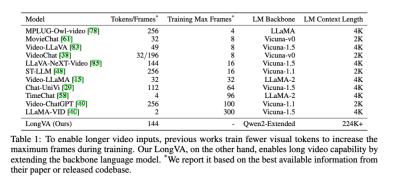
Long context migration
In response to the challenges faced in processing long videos, the research team proposed a new idea of "long context migration". They believe that the current multi-frame bottleneck of large long video models is not in how to extract compressed features from Vision Encoder (Figure (a) below), but in the long context capabilities of the extended model.
They found that by simply extending the context length of the language model on text, they could successfully transfer this ability to the visual modality without any long video training. The specific approach is to first train the language model through long text data, and then use short image data for modal alignment. They found that the model trained in this way can directly understand multi-frame videos during testing, eliminating the need for long video training.
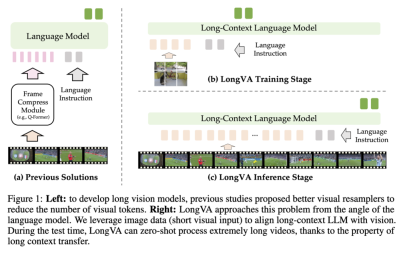
During the long language model training process, the author team used Qwen2-7B-Instruct as the base and extended its text context length to 224K through long context training. During the training process, various optimization strategies such as FlashAttention-2, Ring Attention, activation checkpoint and parameter offload are used to improve training efficiency and memory utilization.
モーダル調整の段階で、著者は画像とビデオを同時に処理するための「UniRes」と呼ばれる統一エンコード方式を設計しました。 UniRes スキームは、LLaVA-1.6 の AnyRes エンコード スキームに似ていますが、ベース画像部分が削除され、各グリッドは 1 次元であり、各グリッド内で 2x2 の特徴プーリングが実行されます。このアプローチにより、画像データをビデオに拡張するときに一貫した表現が維持されます。
LongVA は、「短いコンテキスト トレーニング、長いコンテキスト テスト」の戦略を採用しています。これは、モデルがモーダル アライメント段階でのトレーニングに画像テキスト データのみを使用し、テスト中の処理とテストに長いビデオを直接使用することを意味します。この戦略は、長いコンテキスト転送の現象を効果的に実証し、モデルが長いビデオ トレーニングなしで長いビデオを理解して処理できるようにします。
LongVA のスーパーパフォーマンス
現在、長いビデオの LMM の視覚的なコンテキストの長さを評価するベンチマークはありません。この問題を解決するために、LongVA チームは干し草の中の針テストをテキストからビジュアルに拡張し、Visual Needle-In-A-Haystack (V-NIAH) ベンチマークを提案しました。
V-NIAH テストでは、チームは 5 つの画像の質問と回答の質問を設計し、各質問を 1 つのフレームとして数時間の映画に挿入し、視覚入力として 1 フレーム/秒の頻度でビデオをサンプリングしました。これらの「針」の画像は、モデルが言語知識だけでは質問に回答できないことを保証するために、既存の視覚的な質問回答データセットまたは AI 生成画像から派生しています。各質問には、正しいシステムまたは人間がビデオから「ピン」フレームを見つけて質問に答えることを可能にする「ローカリゼーション ヒント」が含まれています。
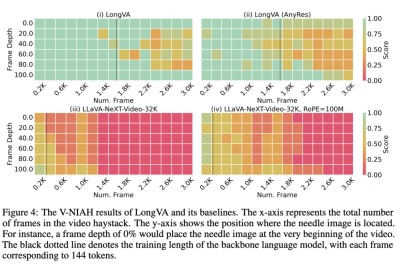
V-NIAH テストの結果は、LongVA の視覚的な干し草の山に針を刺すテストが 2000 フレーム (フレームあたり 144 トークン) 以内でほぼ正確であり、3000 フレームのスケールでも良好な精度率を維持していることを示しています。興味深いことに、言語モデルと同様に、LongVA にも V-NIAH である程度の Lost-In-The-Middle 現象があることがわかりました。
Tencent、中国科学技術大学、その他の機関が提案した最近のビデオ MME リストでは、LongVA が 7 位にランクされ、7B モデルの SoTA に到達しました。 /https://video-mme.github.io/home_page.html#leaderboard
著者チームは、論文にいくつかの効果のデモンストレーションも添付しました。
The above is the detailed content of 7B's most powerful long video model! LongVA video understanding exceeds 1,000 frames, dominating multiple lists. For more information, please follow other related articles on the PHP Chinese website!

 The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AM
The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AMThe term "AI-ready workforce" is frequently used, but what does it truly mean in the supply chain industry? According to Abe Eshkenazi, CEO of the Association for Supply Chain Management (ASCM), it signifies professionals capable of critic
 How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AM
How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AMThe decentralized AI revolution is quietly gaining momentum. This Friday in Austin, Texas, the Bittensor Endgame Summit marks a pivotal moment, transitioning decentralized AI (DeAI) from theory to practical application. Unlike the glitzy commercial
 Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AM
Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AMEnterprise AI faces data integration challenges The application of enterprise AI faces a major challenge: building systems that can maintain accuracy and practicality by continuously learning business data. NeMo microservices solve this problem by creating what Nvidia describes as "data flywheel", allowing AI systems to remain relevant through continuous exposure to enterprise information and user interaction. This newly launched toolkit contains five key microservices: NeMo Customizer handles fine-tuning of large language models with higher training throughput. NeMo Evaluator provides simplified evaluation of AI models for custom benchmarks. NeMo Guardrails implements security controls to maintain compliance and appropriateness
 AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AM
AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AMAI: The Future of Art and Design Artificial intelligence (AI) is changing the field of art and design in unprecedented ways, and its impact is no longer limited to amateurs, but more profoundly affecting professionals. Artwork and design schemes generated by AI are rapidly replacing traditional material images and designers in many transactional design activities such as advertising, social media image generation and web design. However, professional artists and designers also find the practical value of AI. They use AI as an auxiliary tool to explore new aesthetic possibilities, blend different styles, and create novel visual effects. AI helps artists and designers automate repetitive tasks, propose different design elements and provide creative input. AI supports style transfer, which is to apply a style of image
 How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AM
How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AMZoom, initially known for its video conferencing platform, is leading a workplace revolution with its innovative use of agentic AI. A recent conversation with Zoom's CTO, XD Huang, revealed the company's ambitious vision. Defining Agentic AI Huang d
 The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AM
The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AMWill AI revolutionize education? This question is prompting serious reflection among educators and stakeholders. The integration of AI into education presents both opportunities and challenges. As Matthew Lynch of The Tech Edvocate notes, universit
 The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AM
The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AMThe development of scientific research and technology in the United States may face challenges, perhaps due to budget cuts. According to Nature, the number of American scientists applying for overseas jobs increased by 32% from January to March 2025 compared with the same period in 2024. A previous poll showed that 75% of the researchers surveyed were considering searching for jobs in Europe and Canada. Hundreds of NIH and NSF grants have been terminated in the past few months, with NIH’s new grants down by about $2.3 billion this year, a drop of nearly one-third. The leaked budget proposal shows that the Trump administration is considering sharply cutting budgets for scientific institutions, with a possible reduction of up to 50%. The turmoil in the field of basic research has also affected one of the major advantages of the United States: attracting overseas talents. 35
 All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AM
All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI unveils the powerful GPT-4.1 series: a family of three advanced language models designed for real-world applications. This significant leap forward offers faster response times, enhanced comprehension, and drastically reduced costs compared t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

WebStorm Mac version
Useful JavaScript development tools

