
 Technology peripheralsAIICLR2024 | Harvard FairSeg: The first large-scale medical segmentation dataset to study the fairness of segmentation algorithms
Technology peripheralsAIICLR2024 | Harvard FairSeg: The first large-scale medical segmentation dataset to study the fairness of segmentation algorithms

Author | Tian Yu
In recent years, the issue of fairness of artificial intelligence models has received more and more attention, especially in the medical field, because the fairness of medical models has a negative impact on people's health. Health and life matter. High-quality medical equity datasets are necessary to advance equitable learning research.
Existing medical fairness datasets are all aimed at classification tasks, and there is no fairness dataset available for medical segmentation. However, medical segmentation is a very important medical AI task like classification. In some scenarios, segmentation is even superior to classification because it provides detailed spatial information on organ abnormalities to be evaluated by the clinician.
In the latest research, the Harvard-Ophthalmology-AI-Lab team at Harvard University proposed the first fairness dataset for medical segmentation, called Harvard-FairSeg, containing 10,000 patient samples. Additionally, a fair error bound scaling method is proposed by using the latest Segment Anything Model (SAM) to reweight the loss function based on the upper bound error for each identity group.
To facilitate fair comparisons, the team utilized a novel criterion for assessing fairness in segmentation tasks called equity-scaled segmentation performance. Through comprehensive experiments, the researchers demonstrate that their approach is either superior or comparable in fairness performance to state-of-the-art fairness learning models.
Here, researchers from Harvard University share with you a wave of ICLR 2024 final draft work "Harvard FairSeg: A Large-Scale Medical Image Segmentation Dataset for Fairness Learning Using Segment Anything Model with Fair Error-Bound Scaling".

Code address: https://github.com/Harvard-Ophthalmology-AI-Lab/Harvard-FairSeg
Dataset website: https://ophai.hms.harvard.edu/datasets/harvard-fairseg10k/
Dataset download link: https://drive.google.com/drive/u/1/folders /1tyhEhYHR88gFkVzLkJI4gE1BoOHoHdWZ
Harvard-Ophthalmology-AI-Lab is committed to providing high-quality fairness datasets, and more datasets include fairness classification tasks for three ophthalmic diseases.
Dataset webpage of Harvard-Ophthalmology-AI-Lab: https://ophai.hms.harvard.edu/datasets/
Background
With the increasing application of artificial intelligence in medical imaging diagnosis , it becomes critical to ensure the fairness of these deep learning models and to delve into the hidden biases that may arise in complex real-world situations. Unfortunately, machine learning models may inadvertently include sensitive attributes related to medical images (such as race and gender), which may impact the model's ability to distinguish anomalies. This challenge has spurred numerous efforts in machine learning and computer vision to investigate bias, advocate for fairness, and introduce new datasets.

As of now, only a few public fairness datasets have been proposed for studying fairness classification. The main thing is that most of these datasets are just tabular data, so they are not suitable for developing fairness computer vision that requires imaging data. Model. This lack of fairness in computer vision is of particular concern, especially given the growing influence of deep learning models that rely on such data. In the field of medical imaging, only a few datasets have been used for fair learning.
Most of these datasets are not specifically designed for fairness modeling (the only medical image datasets currently are listed in table 1). They typically contain only a limited range of sensitive attributes such as age, gender, and race, thus limiting the scope for examining fairness across different populations. Furthermore, they also lack a comprehensive benchmarking framework. More importantly, although these previous datasets and methods provide solutions for medical classification, they ignore the more critical area of medical segmentation.
However, creating such a new large dataset for fair learning faces multiple challenges. First, there is a lack of large-scale, high-quality medical data and manual pixel-level annotation, which require a lot of labor and time to collect and annotate. Second, existing methods to improve fairness are mainly designed for medical classification, and their performance remains questionable when adapted to segmentation tasks. It is also uncertain whether the unfairness present in the segmentation task can be effectively mitigated algorithmically. Finally, evaluation metrics for assessing the fairness of medical segmentation models remain elusive. Additionally, there can be challenges in adapting existing fairness metrics designed for classification to segmentation tasks.
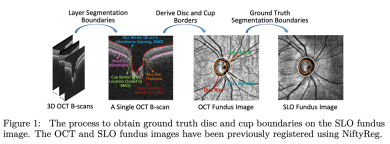
To address these challenges, we propose the first large-scale fairness dataset in the field of medical segmentation, Harvard-FairSeg. This dataset is designed to be used to study fair cup-disc segmentation for diagnosing glaucoma from SLO fundus images, as shown in Figure 1.
Glaucoma is one of the leading causes of irreversible blindness worldwide, with a prevalence of 3.54% in the 40-80 age group, affecting approximately 80 million people. Early glaucoma is often asymptomatic, which emphasizes the need for prompt professional examination. Accurate segmentation of cup-discs is critical for early diagnosis of glaucoma by medical professionals.
Notably, black people have twice the risk of developing glaucoma compared to other groups, yet this group generally has the lowest segmentation accuracy. This motivates us to compile a dataset to study the problem of segmentation fairness. The highlights of our proposed Harvard-FairSeg dataset are as follows:
(1) The first fairness learning dataset in the field of medical segmentation. This dataset provides cup-disc segmentation of SLO fundus imaging data; (2) This dataset is equipped with six sensitive attributes collected from real-life hospital clinical scenarios for studying the fairness learning problem; (3) We Multiple SOTA fairness learning algorithms are evaluated on the proposed new dataset and evaluated using multiple segmentation performance metrics including Dice and IoU.
How to obtain a large number of high-quality segmentation annotations
The subjects tested in this study came from a large academic eye hospital, and the time span was from 2010 to 2021. This study will publish three types of data: (1) SLO fundus scan images; (2) patient demographic information containing six different attributes; (3) automatically annotated by OCT machines and manually rated by professional medical practitioners How to obtain a large number of high-quality segmentation annotations with pixel-level annotation has always been a very important part of medical segmentation.
Our novel method is to first obtain the pixel annotation of the cup and disc areas from the OCT machine, where the disc boundary is divided into Bruch's membrane openings in 3D OCT, which is implemented by the OCT manufacturer software, and the cup boundary is detected as the inner limit membrane ( The intersection between ILM) and the plane that results in the minimum surface area and the intersection of the disc boundary on the plane. Roughly speaking, the cup border can be thought of as the location on the ILM closest to the optic disc border, defined as Bruch’s membrane opening.
Bruch’s membrane opening and inner limiting membrane are easily segmented due to the high contrast between them and the background. So because OCT maker software utilizes 3D information, segmentation of cups and discs using OCT machines is generally reliable.
In contrast, 2Dcup and disc segmentation on fundus photographs can be challenging due to various factors including attenuated imaging signals and vascular occlusion. However, as OCT machines are quite expensive and less common in primary care, we propose to migrate these annotations from 3D OCT to 2D SLO fundus images to have a wider impact in early glaucoma screening in primary care.
Specifically, we first use the NiftyReg tool to align the SLO fundus image with the OCT-derived fundus image (OCT fundus). Subsequently, we apply the affine metric of NiftyReg to the cup-disc mask of the OCT fundus image to align it with the SLO Fundus image alignment. This process effectively produces a large number of high-quality SLO fundus mask annotations, avoiding the labor-intensive manual pixel annotation process.
It is worth noting that this medical registration operation demonstrates quite high accuracy in real-world scenarios, and our empirical observations show that the medical registration success rate is approximately 80%. Following this automated process, the generated masks are rigorously reviewed and manually rated by a panel of five medical professionals to ensure precise annotation of cup-disc regions and exclude misplaced cup or disc masks and registration failures. Condition.
Data Features: Our Harvard-FairSeg dataset contains 10,000 samples from 10,000 subjects. We split the data into a training set of 8,000 samples and a test set of 2,000 samples. The mean age of the data set was 60.3±16.5 years. In this dataset, six sensitive attributes are included for in-depth fairness learning research, including age, gender, race, ethnicity, preferred language, and marital status.
In terms of racial demographics, the dataset includes samples from three main groups: Asians, with 919 samples; Blacks, with 1,473 samples; and Whites, with 7,608 samples. In terms of gender, women comprised 58.5% of the subjects and the remainder were men. The ethnic distribution was 90.6% non-Hispanic, 3.7% Hispanic, and 5.7% unspecified. In terms of preferred language, 92.4% of the subjects preferred English, 1.5% preferred Spanish, 1% preferred other languages, and 5.1% were undecided. From the perspective of marital status, 57.7% were married or partnered, 27.1% were single, 6.8% had experienced divorce, 0.8% were legally separated, 5.2% were widowed, and 2.4% did not specify.
Our approach to improving fairness, Fair Error-Bound Scaling
We assume that sample groups that obtain a smaller overall Dice loss means that the model learns better for that specific group of samples, therefore, these sample groups need to be smaller Small weight. Conversely, sample groups with larger overall Dice loss (i.e., intractable cases) may lead to worse generalization capabilities and induce more algorithm bias, which requires assigning larger learning weights to these sample groups.
Therefore, we propose a new fair error bound scaling method for scaling Dice loss between different population groups during training. We first define the standard Dice loss between predicted pixel scores and ground truth targets as:

To ensure fairness among different attribute groups, we use a novel fair error bound scaling mechanism to enhance the above Dice loss. Loss function:
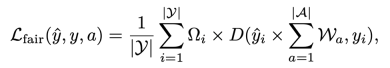
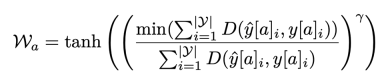
By adjusting the predicted pixel scores with these attribute weights, this loss ensures that different attribute groups contribute to the loss function in a balanced manner during model training, thereby promoting fairness.
Metrics for evaluating fair segmentation accuracy: Traditional segmentation metrics such as Dice and IoU provide insights into segmentation performance, but may not effectively capture fairness across different groups. With this in mind, we aim to propose a new metric that encompasses both segmentation accuracy and fairness across different groups. This results in a comprehensive perspective, ensuring the model is both accurate and fair.
To incorporate group fairness, we need to evaluate group accuracy individually. We first define a segmentation measure accuracy difference Δ as follows:

Here, Δ measures the overall deviation of each population’s accuracy from the overall accuracy. It approaches zero when all groups achieve similar segmentation accuracy.
When we consider fairness across different groups, we need to calculate the relative difference between overall segmentation accuracy and accuracy within each demographic group. Based on this, we define the Equity-Scaled Segmentation Performance (ESSP) metric as defined below:

This formula ensures that ESSP is always less than or equal to I. As Δ decreases (indicating equal segmentation performance among groups), ESSP tends to the traditional segmentation metric. In contrast, a higher Δ indicates greater differences in segmentation performance between groups, resulting in lower ESSP scores.
This approach allows us to evaluate segmentation models not only on accuracy (via Dice, IoU, etc. metrics) but also on fairness across different groups. This makes the ESSP scoring function a key metric to ensure segmentation accuracy and fairness in medical imaging tasks. This metric can be combined with traditional dice IoU to become ES-Dice and ES-IoU.
Experiment
We chose two segmentation networks as backbone. Among them, we chose the recently launched large segmentation model Segment Anything Model (SAM) to experiment with the segmentation accuracy of SOTA, and for the other backbone we chose TransUNet.
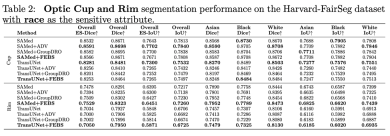
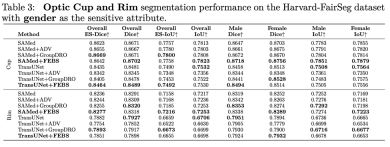
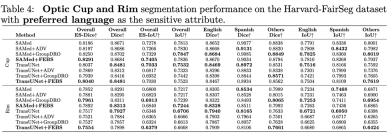
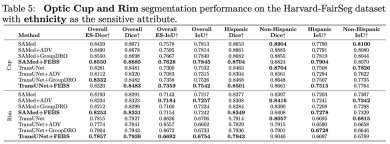
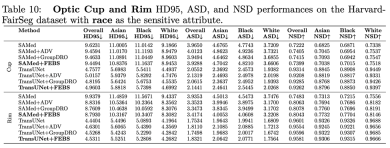
We also used other segmentation metrics such as HD95 ASD and NSD for testing. The following are the results on race:
The above is the detailed content of ICLR2024 | Harvard FairSeg: The first large-scale medical segmentation dataset to study the fairness of segmentation algorithms. For more information, please follow other related articles on the PHP Chinese website!

 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
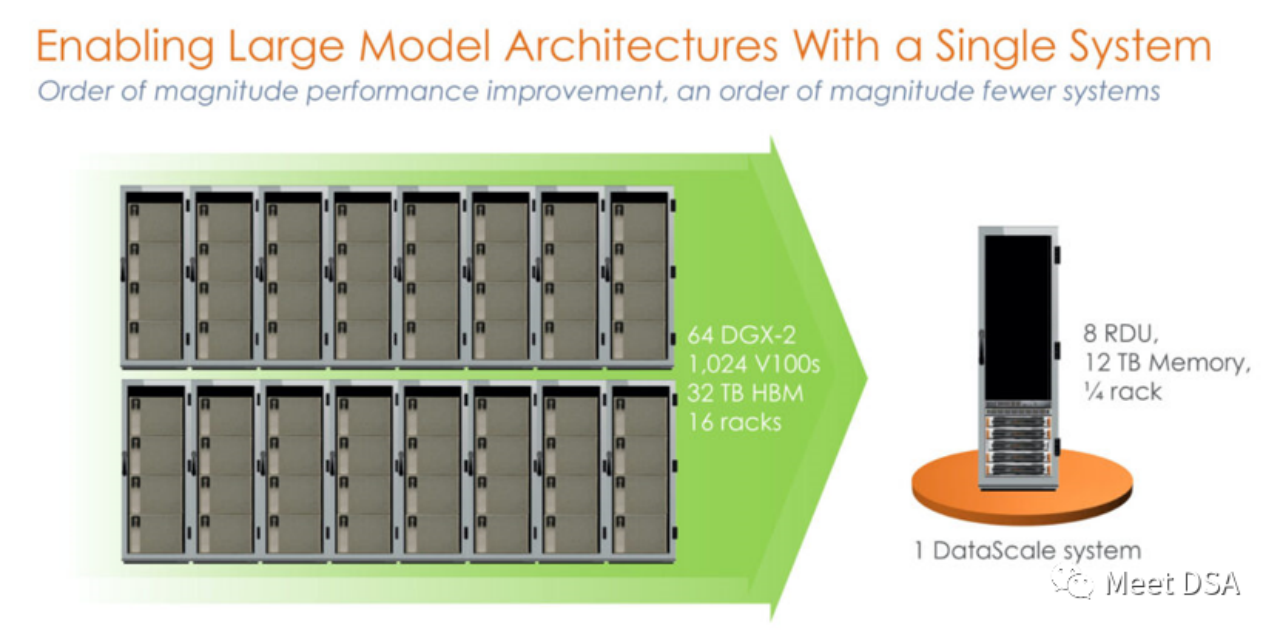
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
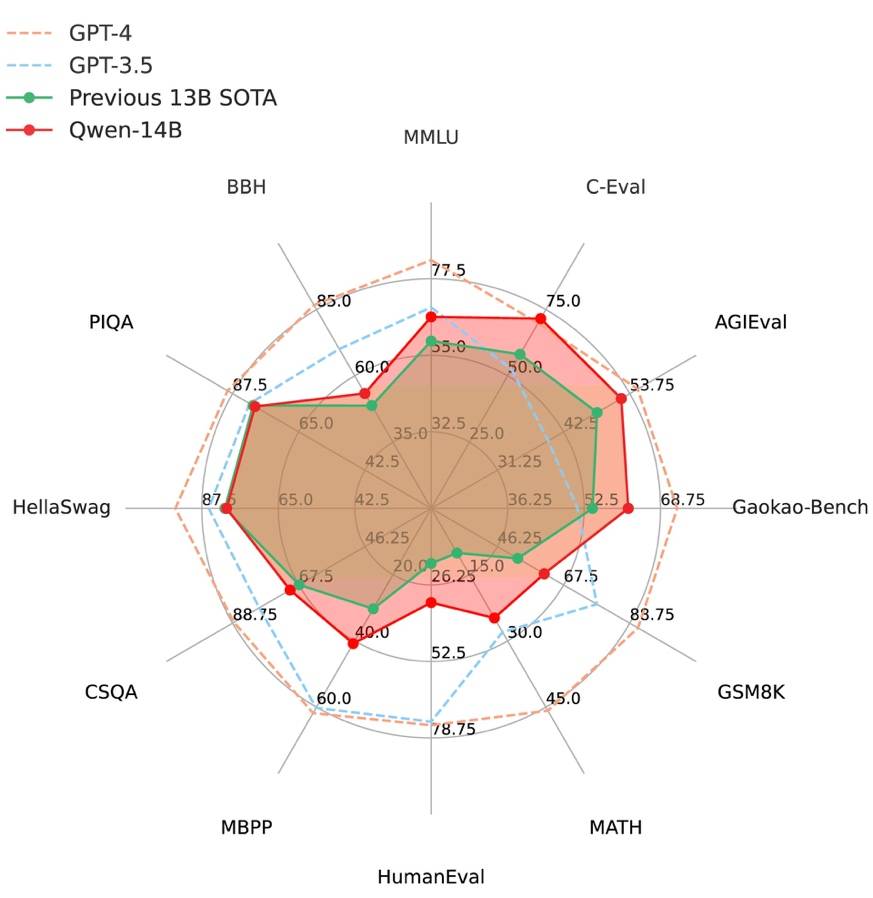
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
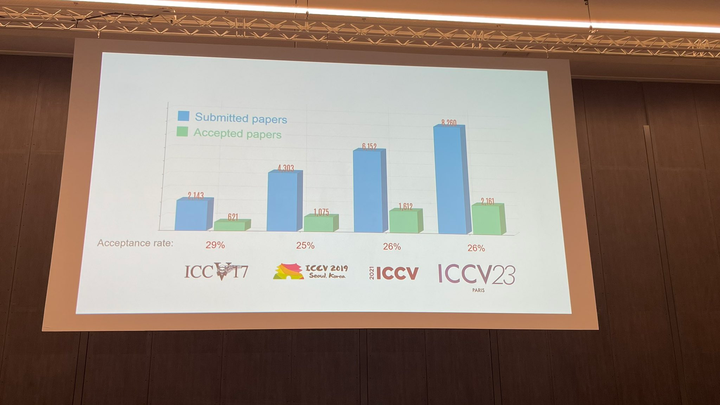
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
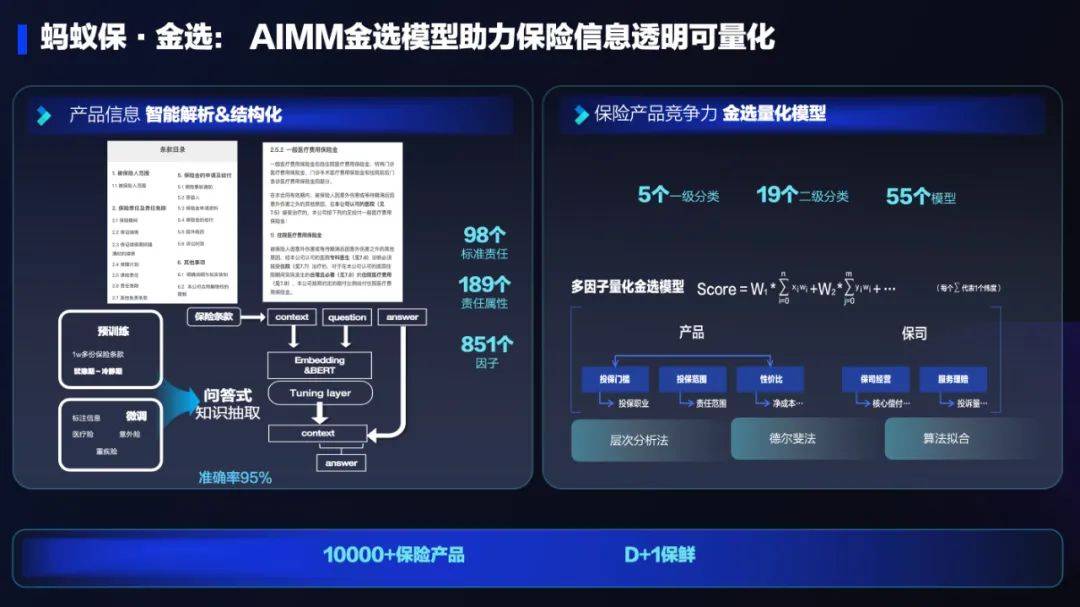
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM
快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM杭州第19届亚运会不仅是国际顶级体育盛会,更是一场精彩绝伦的中国科技盛宴。本届亚运会中,快手StreamLake与杭州电信深度合作,联合打造智慧观赛新体验,在击剑赛事的转播中,全面应用了快手StreamLake六自由度技术,其中“子弹时间”也是首次应用于击剑项目国际顶级赛事。中国电信杭州分公司智能亚运专班组长芮杰表示,依托快手StreamLake自研的4K3D虚拟运镜视频技术和中国电信5G/全光网,通过赛场内部署的4K专业摄像机阵列实时采集的高清竞赛视频,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

SublimeText3 Chinese version
Chinese version, very easy to use

SublimeText3 Linux new version
SublimeText3 Linux latest version

Notepad++7.3.1
Easy-to-use and free code editor

Dreamweaver CS6
Visual web development tools

