
 Technology peripheralsAIRevealed: Step Star trillion MoE+ multi-modal large model matrix unveiled
Technology peripheralsAIRevealed: Step Star trillion MoE+ multi-modal large model matrix unveiled
At the 2024 World Artificial Intelligence Conference, many people lined up in front of a booth just to let the big AI model "arrange" an errand for them in heaven.

- Provide personal photos
- Generate fairyland image photos (referring to the style of "Havoc in Heaven")
- Interactive plot selection and conversation session
- Evaluate MBTI personality type based on choices and answers
- "Arrange" heavenly errands according to personality type
Experience method:
- Queue on site
- Online experience (scan the QR code below)
Big model startup company Stepping Stars announces big move

The AI interactive experience "AI + Havoc in Heaven" in cooperation with Shanghai Film Studio is just an appetizer for Stepping Stars to showcase the charm of large models. During WAIC, they grandly launched the following big move:
- MoE large model with trillions of parameters: Step-2 official version
- Multi-modal large model with hundreds of billions of parameters: Step-1.5V
- Image generation large model: Step-1X
Step-2 trillion parameter large model
After debuting with Step Stars in March, Step-2 has evolved to be fully close to GPT -4 level, with excellent performance in mathematical logic, programming, Chinese knowledge, English knowledge and instruction following.
Step-1.5V multi-modal large model
Based on the Step-2 model, Step Star developed the multi-modal large model Step-1.5V, which not only has powerful perception and video understanding capabilities, but also can Image content for advanced reasoning (such as solving math problems, writing code, composing poetry).
Step-1X large image generation model
The image generation in "AI + Upheaval in Heaven" is completed by the Step-1X model, which is deeply optimized for Chinese elements and has excellent semantic alignment and instruction following ability.
Step Star has established a complete large model matrix covering trillion-parameter MoE large models and multi-modal large models, becoming the first echelon of large model startups. This is due to their persistence in Scaling Law and matching technology and resource strength.
The
Step-2 trillion parameter large model
trained from scratch will significantly improve the model’s reasoning capabilities in fields such as mathematics and programming. Step-2 can solve more complex mathematical logic and programming problems than the 100-billion-level model, and has been quantitatively confirmed by benchmark evaluations. In addition, its Chinese and English capabilities and command following ability have also been significantly improved.
In addition, its Chinese and English capabilities and command following ability have also been significantly improved.
The reason why Step-2 performs so well is, on the one hand, its huge number of parameters, and on the other hand, its training method.
We know that there are two main ways to train MoE models. One is upcycle, which is to further improve model performance in a more efficient and economical way by reusing the intermediate results of the training process or the already trained model. This training method requires low computing power and has high training efficiency, but the trained model often has a lower upper limit. For example, when training a MoE model, if multiple expert models are obtained by copying and fine-tuning the same basic model, there may be a high degree of similarity between these expert models. This homogeneity will limit the performance improvement of the MoE model. space.
Considering these limitations, Step Stars chose another approach - completely independent research and development and training from scratch. Although this method is difficult to train and consumes a lot of computing power, it can achieve a higher model upper limit.
Specifically, they first made some innovations in MoE architecture design, including parameter sharing by some experts, heterogeneous expert design, etc. The former ensures that certain common capabilities are shared among multiple experts, but at the same time each expert still retains its uniqueness. The latter increases the diversity and overall performance of the model by designing different types of expert models so that each expert has unique advantages on specific tasks.
Based on these innovations, Step-2 not only has a total number of parameters reaching the trillion level, but also the number of parameters activated for each training or inference exceeds most dense models on the market.
In addition, training such a trillion-parameter model from scratch is also a big test for the system team. Fortunately, the Step Star System team has rich practical experience in system construction and management, which allowed them to successfully break through key technologies such as 6D parallelism, extreme video memory management, and fully automated operation and maintenance during the training process, and successfully completed Step-2. train. The Step-1.5V multi-modal large model standing on the shoulders of Step-2
Three months ago, Step Star released the Step-1V multi-modal large model. Recently, with the release of the official version of Step-2, this large multi-modal model has also been upgraded to version 1.5.
Step-1.5V mainly focuses on multi-modal understanding capabilities. Compared with previous versions, its perceptual capabilities have been greatly improved. It can understand complex charts and flowcharts, accurately perceive complex geometric positions in physical space, and can also process high-resolution and extreme aspect ratio images.

As mentioned earlier, Step-2 played an indispensable role in the birth of Step-1.5V. This means that during Step-1.5V’s RLHF (reinforcement learning based on human feedback) training process, Step-2 is used as a supervised model, which is equivalent to Step-1.5V having a trillion parameters. Models become teachers. Under the guidance of this teacher, Step-1.5V's reasoning ability has been greatly improved, and it can perform various advanced reasoning tasks based on image content, such as solving math problems, writing code, composing poetry, etc. This is also one of the capabilities recently demonstrated by OpenAI GPT-4o. This capability has made the outside world full of expectations for its application prospects.
The multi-modal generation capability is mainly reflected in the new model Step-1X. Compared with some similar models, it has better semantic alignment and command following capabilities. At the same time, it has been deeply optimized for Chinese elements and is more suitable for the aesthetic style of Chinese people.The AI interactive experience of "Havoc in Heaven" created based on this model integrates image understanding, style transfer, image generation, plot creation and other capabilities, richly and three-dimensionally showing the industry-leading multi-modality of Step Stars level. For example, when generating the initial character, the system will first determine whether the photo uploaded by the user meets the requirements for "face pinching", and then flexibly give feedback in a very "Havoc in Heaven" language style. This reflects the model's picture understanding ability and large language model ability. With the support of large model technology, this game allows players to obtain a completely different interactive experience from traditional online H5 games. Because all interactive questions, user images, and analysis results are generated after the model learns features in real time, the possibility of thousands of people and faces and unlimited plots is truly realized.
 These excellent performances are inseparable from the DiT model architecture developed by Step Star Full Link (OpenAI’s Sora is also a DiT architecture). In order to allow more people to use this model, Step Star has designed three different parameter quantities for Step-1X: 600M, 2B, and 8B to meet the needs of different computing power scenarios.
These excellent performances are inseparable from the DiT model architecture developed by Step Star Full Link (OpenAI’s Sora is also a DiT architecture). In order to allow more people to use this model, Step Star has designed three different parameter quantities for Step-1X: 600M, 2B, and 8B to meet the needs of different computing power scenarios.
- In the first stage, each modality such as language, vision, and sound develops independently, and the model of each modality focuses on learning and characterizing the characteristics of its specific modality.
- In the second stage, different modes begin to merge. However, this integration is not complete, and the understanding and generation tasks are still separated, which results in the model having strong understanding ability but weak generation ability, or vice versa.
- In the third stage, generation and understanding are unified in a model, and then fully integrated with the robot to form embodied intelligence. Next, embodied intelligence actively explores the physical world, and then gradually evolves into a world model, thereby realizing AGI.
This is also the route that Jiang Daxin and others have been adhering to since the beginning of their business. On this road, "Trillions of parameters" and "multi-mode fusion" are indispensable. Step-2, Step-1.5V, and Step-1X are all nodes they have reached on this road.
Moreover, these nodes are linked together. Take OpenAI as an example. The video generation model Sora they released at the beginning of the year used OpenAI's internal tool (most likely GPT-4V) for annotation; and GPT-4V was trained based on GPT-4 related technologies. From the current point of view, the powerful capabilities of single-modal models will lay the foundation for multi-modality; the understanding of multi-modality will lay the foundation for generation. Relying on such a model matrix, OpenAI realizes the left foot stepping on the right foot. And Step Star is confirming this route in China.
We look forward to this company bringing more surprises to the domestic large model field.
The above is the detailed content of Revealed: Step Star trillion MoE+ multi-modal large model matrix unveiled. For more information, please follow other related articles on the PHP Chinese website!

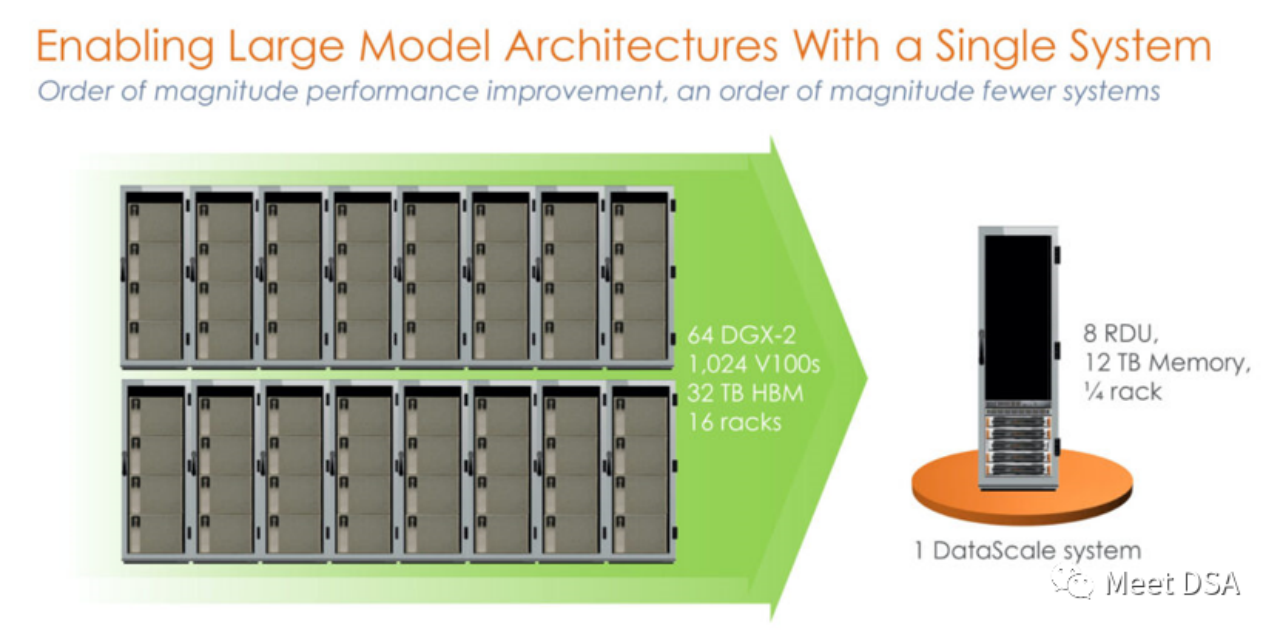 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
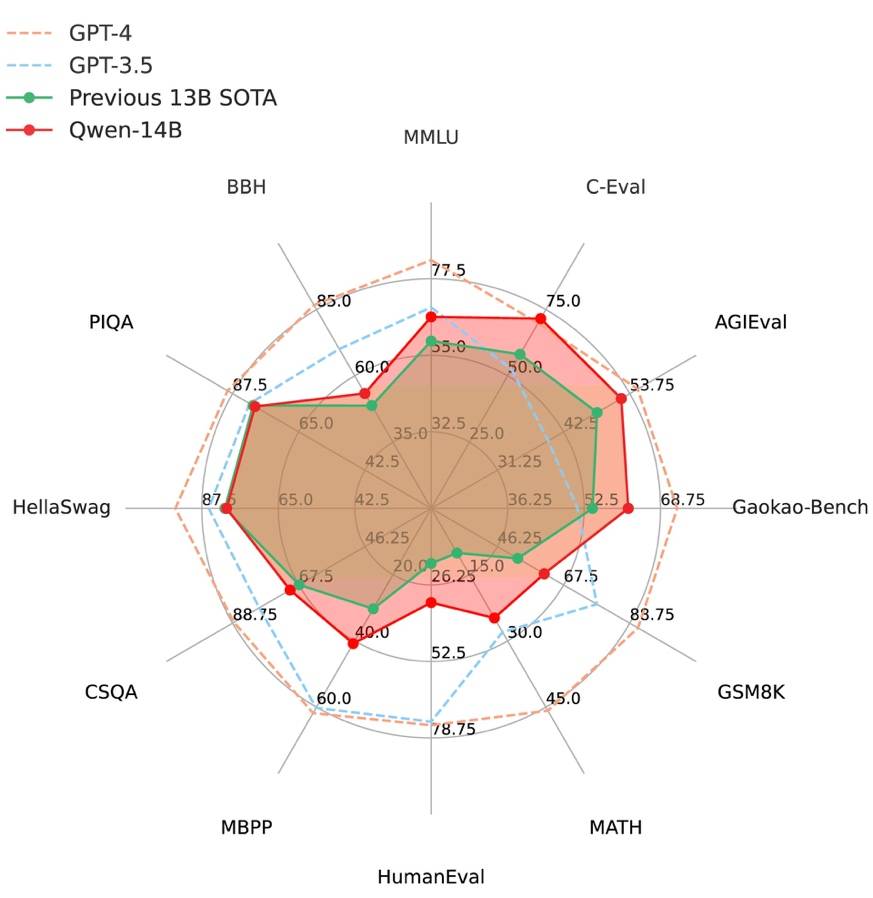 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
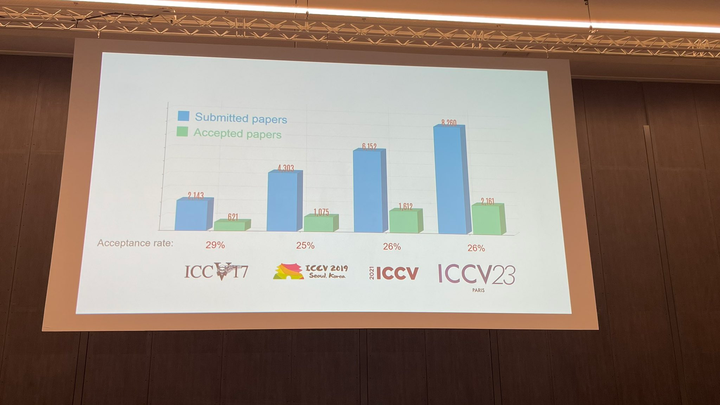 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
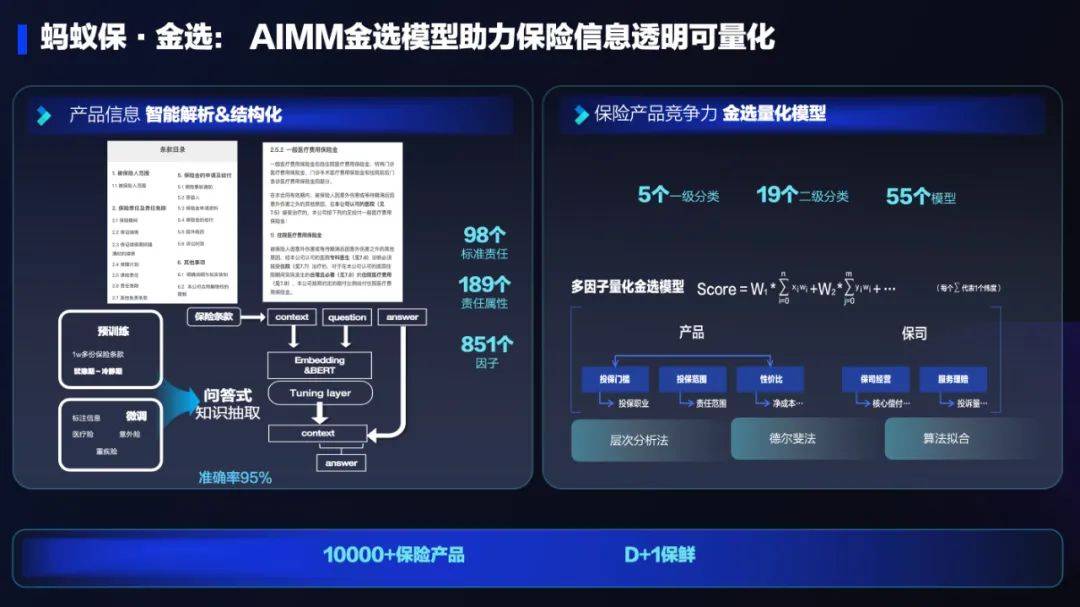 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 腾讯与中国宋庆龄基金会发布“AI编程第一课”,教育部等四部门联合推荐Sep 16, 2023 am 09:29 AM
腾讯与中国宋庆龄基金会发布“AI编程第一课”,教育部等四部门联合推荐Sep 16, 2023 am 09:29 AM腾讯与中国宋庆龄基金会合作,于9月1日发布了名为“AI编程第一课”的公益项目。该项目旨在为全国零基础的青少年提供AI和编程启蒙平台。只需在微信中搜索“腾讯AI编程第一课”,即可通过官方小程序免费体验该项目由北京师范大学任学术指导单位,邀请全球顶尖高校专家联合参研。“AI编程第一课”首批上线内容结合中国航天、未来交通两项国家重大科技议题,原创趣味探索故事,通过剧本式、“玩中学”的方式,让青少年在1小时的学习实践中认识A


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

WebStorm Mac version
Useful JavaScript development tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Atom editor mac version download
The most popular open source editor

