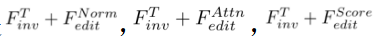The AIxiv column is a column where academic and technical content is published on this site. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Shuai Xincheng, the first author of this article, is currently studying for a PhD in the FVL Laboratory of Fudan University and graduated from Shanghai Jiao Tong University with a bachelor's degree. His main research interests include image and video editing and multimodal learning.
This article proposes a unified framework for solving general editing tasks! Recently, researchers from the FVL Laboratory of Fudan University and Nanyang Technological University summarized and reviewed multi-modal guided image editing algorithms based on Vincentian graph large models. The review covers more than 300 relevant studies, and the latest model investigated is as of June this year! This review extends the discussion of control conditions (natural language, images, user interfaces) and editing tasks (object/attribute manipulation, spatial transformation, inpainting, style transfer, image translation, subject/attribute customization) to more novel and a comprehensive discussion of editing methods from a more general perspective. Furthermore, this review proposes a unified framework that represents the editing process as a combination of different algorithm families, and illustrates the characteristics of various combinations as well as adaptation scenarios through comprehensive qualitative and quantitative experiments. The framework provides a friendly design space to meet the different needs of users and provides a certain reference for researchers to develop new algorithms. Image editing is designed to edit a given synthetic or real image as per the specific needs of the user. As a promising and challenging area in the field of artificial intelligence generated content (AIGC), image editing has been extensively studied. Recently, the large-scale image-to-infrared (T2I) diffusion model has driven the development of image editing technology. These models generate images based on text prompts, demonstrating amazing generative capabilities and becoming a common tool for image editing. The T2I-based image editing method significantly improves editing performance and provides users with an interface for content modification using multi-modal condition guidance. We provide a comprehensive review of multimodal-guided image editing techniques based on T2I diffusion models. First, we define the scope of image editing tasks from a more general perspective and describe various control signals and editing scenarios in detail. We then propose a unified framework to formalize the editing process, representing it as a combination of two algorithm families. This framework provides users with a design space to achieve specific goals. Next, we conducted an in-depth analysis of each component within the framework, studying the characteristics and applicable scenarios of different combinations. Since training-based methods directly learn to map source images to target images, we discuss these methods separately and introduce source image injection schemes under different scenarios. Additionally, we review the application of 2D techniques in video editing, focusing on resolving inter-frame inconsistencies. Finally, we also discuss open challenges in the field and propose potential future research directions. 
- Paper title: A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
- Publication unit: Fudan University FVL Laboratory, Nanyang Technological University
- Paper address: https://arxiv .org/abs/2406.14555
- Project address: https://github.com/xinchengshuai/Awesome-Image-Editing
1.1. In real life, people have an increasing demand for controllable, high-quality intelligent image editing tools. Therefore, it is necessary to systematically summarize and compare the methods and technical characteristics in this direction. 1.2, the current editing algorithms and related reviews limit the editing scenario to retaining most of the low-level semantic information in the image that is not related to editing. For this reason, it is necessary to expand the scope of the editing task and discuss editing from a more general perspective. Task. 1.3, Due to the diversity of requirements and scenarios, it is necessary to formalize the editing process into a unified framework and provide users with a design space to adapt to different editing goals. 2. How do the review highlights differ from the current editorial review? 2.1 The definition and scope of discussion about editing tasks. Compared with existing algorithms and previous editing reviews, this paper defines the image editing task more broadly. Specifically, this article divides editing tasks into content-aware and content-free scene groups. The scenes in the content-aware group are the main tasks discussed in the previous literature. Their commonality is to retain some low-level semantic features in the image, such as editing the pixel content of irrelevant areas, or the image structure. In addition, we pioneered the inclusion of customization tasks into the content-free scenario group, using this type of task that retains high-level semantics (such as subject identity information, or other fine-grained attributes) as an addition to regular editing scenarios. Replenish. V Figure 1. The various editing scenes discussed by Survey
2.2 The unified framework of general editing algorithms. Due to the diversity of editing scenarios, existing algorithms cannot solve all needs well. We therefore formalize the existing editing process into a unified framework, expressed as a combination of two algorithm families. In addition, we also analyzed the characteristics and adaptation scenarios of different combinations through qualitative and quantitative experiments, providing users with a good design space to adapt to different editing goals. At the same time, this framework also provides researchers with a better reference to design algorithms with better performance.
2.3 Comprehensiveness of discussion. We researched more than 300 related papers and systematically and comprehensively explained the application of various modes of control signals in different scenarios. For training-based editing methods, this article also provides strategies for injecting source images into T2I models in various scenarios. In addition, we also discussed the application of image editing technology in the video field, allowing readers to quickly understand the connection between editing algorithms in different fields. 3. A unified framework for general editing algorithms
辑 Figure 2. The unified framework of the general editing algorithm
The framework of the two algorithms Inversion algorithm
and the Editing algorithm .
3.1 Inversion algorithm. The Inversion algorithm
encodes the source image set into a specific feature or parameter space, obtains the corresponding representation
(inversion clue), and uses the corresponding source text description as the identifier of the source image. Including two types of inversion algorithms: tuning-based and forward-based. It can be formalized as: Tuning-based inversionThe source image set is implanted into the generation distribution of the diffusion model through the original diffusion training process. The formalization process is:
where is the introduced learnable parameter, and
.
Forward-based inversion
is used to restore the noise in a certain forward path () in the reverse process (
) of the diffusion model. The formalization process is: where is the parameter introduced in the method, used to minimize , where . 3.2.Editing algorithm. The Editing algorithm generates the final editing result based on and the multi-modal guidance set . Editing algorithms including attention-based, blending-based, score-based and optimization-based. It can be formalized as:
In particular, for each step of the reverse process, performs the following operations:
where the operations in represent the intervention of the editing algorithm in the diffusion model sampling process , used to ensure the consistency between the edited image and the source image collection , and to reflect the visual transformation specified by the guidance conditions in . Specifically, we treat the intervention-free editing process as a normal version of the editing algorithm. It is formalized as:
The formal process of
Attention-based editing: The formal process of
Blending-based editing: The formal process of
Score-based editing:
Optimization-based editing The formalization process of :
3.3 Training-Based editing method. Unlike training-free methods, training-based algorithms directly learn the mapping of source image sets to edited images in task-specific datasets. This type of algorithm can be seen as an extension of tuning-based inversion, which encodes the source image into a generative distribution through additional introduced parameters. In this type of algorithm, the most important thing is how to inject the source image into the T2I model. The following are injection schemes for different editing scenarios. Content-aware task injection scheme:
. Content-free task injection solution: Figure 3. Injection scheme of Content-free tasks
4. Application of unified framework in multi-modal editing tasks
This article illustrates the application of each combination in multi-modal editing tasks through qualitative experiments: Figure 4. About attention-based editing Application of algorithm combination of
Application of algorithm combination
Figure 6. Application of algorithm combination for score-based editing
Please refer to the original paper for detailed analysis. 5. Comparison of different combinations in text-guided editing scenarios
For common text-guided editing tasks, this article designed multiple challenging qualitative experiments to illustrate the editing scenarios suitable for different combinations. In addition, this paper also collects high-quality and difficult data sets accordingly to quantitatively illustrate the performance of advanced algorithms in various combinations in different scenarios. For content-aware tasks, we mainly consider object operations (add/deletion/replacement), attribute changes, and style migration. In particular, we consider challenging experimental settings: 1. Multi-objective editing. 2. Use cases that have a greater impact on the semantic layout of images. We also collect high-quality images of these complex scenes and perform a comprehensive quantitative comparison of state-of-the-art algorithms in different combinations. En Figure 8. The qualitative comparison of each combination in theContent-AWARE mission. From left to right, the results of the results are analyzed and more experimental results, please refer to the original papers.
For content-free tasks, we mainly consider subject-driven customized tasks. And considers a variety of scenarios, such as changing backgrounds, interacting with objects, behavior changes, and style changes. We also defined a large number of text guidance templates and conducted a quantitative analysis of the overall performance of each method. On c Figure 9. The qualitative comparison of each combination in theContent-free mission. From left to right, the results of the results are analyzed and more experimental results, please refer to the original paper. 6. Directions that can be researched in the futureIn addition, this article also provides some analysis on future research directions. Here we take the challenges faced by content-aware tasks and content-free tasks as an example. 6.1. Challenges of Content-aware tasks. For the challenge of content-aware editing tasks, existing methods cannot handle multiple editing scenarios and control signals simultaneously. This limitation forces applications to switch appropriate backend algorithms between different tasks. Additionally, some advanced methods are not user-friendly. Some methods require the user to adjust key parameters to obtain optimal results, while others require tedious inputs such as source and target hints, or auxiliary masks.
6.2.Content-free task challenge. For content-free editing tasks, existing methods have lengthy tuning processes during testing and suffer from overfitting issues. Some studies aim to alleviate this problem by optimizing a small number of parameters or training models from scratch. However, they often lose details that individuate the subject or show poor generalization ability. Furthermore, current methods also fall short in extracting abstract concepts from a small number of images, and they cannot completely separate the desired concepts from other visual elements.
To learn more about the research direction, you can check the original paper. The above is the detailed content of More than 300 related studies, the latest multi-modal image editing review papers from Fudan University and Nanyang Technological University. For more information, please follow other related articles on the PHP Chinese website!
Statement:The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn






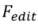
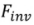 as the identifier of the source image. Including two types of inversion algorithms: tuning-based
as the identifier of the source image. Including two types of inversion algorithms: tuning-based and forward-based
and forward-based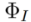 . It can be formalized as:
. It can be formalized as: 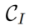
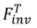
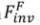 Tuning-based inversion
Tuning-based inversion

 is the introduced learnable parameter, and
is the introduced learnable parameter, and 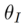
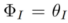
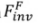
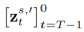
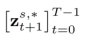
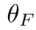 is the parameter introduced in the method, used to minimize
is the parameter introduced in the method, used to minimize 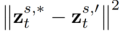 , where
, where 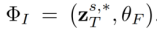 .
. 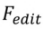 generates the final editing result
generates the final editing result 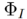 based on
based on 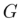 and the multi-modal guidance set
and the multi-modal guidance set 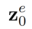 . Editing algorithms including attention-based
. Editing algorithms including attention-based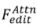 , blending-based
, blending-based , score-based
, score-based and optimization-based
and optimization-based . It can be formalized as:
. It can be formalized as: 
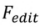 performs the following operations:
performs the following operations: 
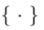 represent the intervention of the editing algorithm in the diffusion model sampling process
represent the intervention of the editing algorithm in the diffusion model sampling process  , used to ensure the consistency between the edited image
, used to ensure the consistency between the edited image  and the source image collection
and the source image collection  , and to reflect the visual transformation specified by the guidance conditions in
, and to reflect the visual transformation specified by the guidance conditions in 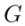 .
.  . It is formalized as:
. It is formalized as:
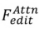 : The formal process of
: The formal process of 
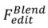 : The formal process of
: The formal process of 
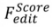 :
: 
 :
: 



 Application of algorithm combination
Application of algorithm combination
 5. Comparison of different combinations in text-guided editing scenarios
5. Comparison of different combinations in text-guided editing scenarios
 For content-aware tasks, we mainly consider object operations (add/deletion/replacement), attribute changes, and style migration. In particular, we consider challenging experimental settings: 1. Multi-objective editing. 2. Use cases that have a greater impact on the semantic layout of images. We also collect high-quality images of these complex scenes and perform a comprehensive quantitative comparison of state-of-the-art algorithms in different combinations. En Figure 8. The qualitative comparison of each combination in theContent-AWARE mission. From left to right, the results of the results are analyzed and more experimental results, please refer to the original papers.
For content-aware tasks, we mainly consider object operations (add/deletion/replacement), attribute changes, and style migration. In particular, we consider challenging experimental settings: 1. Multi-objective editing. 2. Use cases that have a greater impact on the semantic layout of images. We also collect high-quality images of these complex scenes and perform a comprehensive quantitative comparison of state-of-the-art algorithms in different combinations. En Figure 8. The qualitative comparison of each combination in theContent-AWARE mission. From left to right, the results of the results are analyzed and more experimental results, please refer to the original papers.