
 Technology peripheralsAIFrom RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Technology peripheralsAIFrom RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'

The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
In the development process of the field of artificial intelligence, the control and guidance of large language models (LLM) has always been one of the core challenges, aiming to ensure that these models Serve human society both powerfully and safely. Early efforts focused on managing these models through reinforcement learning methods with human feedback (RLHF), with impressive results marking a key step toward more human-like AI.
Despite its great success, RLHF is very resource intensive during training. Therefore, in recent times, scholars have continued to explore simpler and more efficient policy optimization paths based on the solid foundation laid by RLHF, giving rise to the birth of direct preference optimization (DPO). DPO obtains a direct mapping between the reward function and the optimal strategy through mathematical reasoning, eliminating the training process of the reward model, optimizing the strategy model directly on the preference data, and achieving an intuitive leap from "feedback to strategy". This not only reduces the complexity, but also enhances the robustness of the algorithm, quickly becoming the new favorite in the industry.
However, DPO mainly focuses on policy optimization under inverse KL divergence constraints. DPO excels at improving alignment performance due to the mode-seeking property of inverse KL divergence, but this property also tends to reduce diversity in the generation process, potentially limiting the capabilities of the model. On the other hand, although DPO controls KL divergence from a sentence-level perspective, the model generation process is essentially token-by-token. Controlling KL divergence at the sentence level intuitively shows that DPO has limitations in fine-grained control and its weak ability to adjust KL divergence, which may be one of the key factors that leads to the rapid decline in the generative diversity of LLM during DPO training.
To this end, the team of Wang Jun and Zhang Haifeng from the Chinese Academy of Sciences and University College London proposed a large model alignment algorithm modeled from a token-level perspective: TDPO.

Paper title: Token-level Direct Preference Optimization
Paper address: https://arxiv.org/abs/2404.11999
Code address: https://github.com/Vance0124 /Token-level-Direct-Preference-Optimization
In order to deal with the problem of significant decline in the diversity of model generation, TDPO redefined the objective function of the entire alignment process from a token-level perspective, and transformed the Bradley-Terry model into Converting it into the form of advantage function enables the entire alignment process to be finally analyzed and optimized from the Token-level level. Compared with DPO, the main contributions of TDPO are as follows:
Token-level modeling method: TDPO models the problem from a Token-level perspective and conducts a more detailed analysis of RLHF;
Fine-grained KL divergence constraints: The forward KL divergence constraints are theoretically introduced at each token, allowing the method to better constrain model optimization;
Obvious performance advantages: compared to DPO , TDPO is able to achieve better alignment performance and generate diverse Pareto fronts.
The main difference between DPO and TDPO is shown in the figure below:

to TDPO ’ to TDPO’s TDPO’s TDPO’s TDPO’s alignment to be optimized as shown below. DPO is modeled from a sentence-level perspective

Figure 2: Alignment optimization method of TDPO. TDPO models from a token-level perspective and introduces additional forward KL divergence constraints at each token, as shown in the red part in the figure, which not only controls the degree of model offset, but also serves as a baseline for model alignment.
The specific derivation process of the two methods is introduced below.
Background: Direct Preference Optimization (DPO)
DPO obtains a direct mapping between the reward function and the optimal policy through mathematical derivation, eliminating the reward modeling stage in the RLHF process:

Formula (1) is substituted into the Bradley-Terry (BT) preference model to obtain the direct policy optimization (DPO) loss function:

where  is the preference pair consisting of prompt, winning response and losing response from preference data set D.
is the preference pair consisting of prompt, winning response and losing response from preference data set D.
TDPO
Symbol annotation
In order to model the sequential and autoregressive generation process of the language model, TDPO expresses the generated response as a form composed of T tokens , where
, where  ,
,  represent the alphabet (Glossary).
represent the alphabet (Glossary).
When text generation is modeled as a Markov decision process, the state is defined as the combination of prompt and the token that has been generated up to the current step, represented by  , while the action corresponds to the next generated token, represented by is
, while the action corresponds to the next generated token, represented by is  , the token-level reward is defined as
, the token-level reward is defined as  .
.
Based on the definitions provided above, TDPO establishes a state-action function  , a state value function
, a state value function  and an advantage function
and an advantage function  for the policy
for the policy  :
:

where  represents the discount factor.
represents the discount factor.
Human Feedback Reinforcement Learning from a Token-level Perspective
TDPO theoretically modifies the reward modeling phase and RL fine-tuning phase of RLHF, extending them into optimization goals considered from a token-level perspective.
For the reward modeling stage, TDPO established the correlation between the Bradley-Terry model and the advantage function:

For the RL fine-tuning stage, TDPO defined the following objective function:

Derivation
Starting from objective (4), TDPO derives the mapping relationship between the optimal strategy  and the state-action function
and the state-action function  on each token:
on each token:

Where,  represents the partition function.
represents the partition function.
Substituting equation (5) into equation (3), we get:

where,  represents the difference in implicit reward function represented by the policy model
represents the difference in implicit reward function represented by the policy model  and the reference model
and the reference model  , expressed as
, expressed as

while  is Denoting the sequence-level forward KL divergence difference of
is Denoting the sequence-level forward KL divergence difference of  and
and  , weighted by
, weighted by  , is expressed as
, is expressed as

Based on Equation (8), the TDPO maximum likelihood loss function can be modeled as:

Considering that In practice,  loss tends to increase
loss tends to increase  , amplifying the difference between
, amplifying the difference between  and
and  . TDPO proposes to modify equation (9) as:
. TDPO proposes to modify equation (9) as:

where  is a hyperparameter, and
is a hyperparameter, and

Here,  means Stop the gradient propagation operator.
means Stop the gradient propagation operator.
We summarize the loss functions of TDPO and DPO as follows:

It can be seen that TDPO introduces this forward KL divergence control at each token, allowing better control of KL during the optimization process changes without affecting the alignment performance, thereby achieving a better Pareto front.
Experimental settings
TDPO conducted experiments on IMDb, Anthropic/hh-rlhf, MT-Bench data sets.
IMDb
On the IMDb data set, the team used GPT-2 as the base model, and then used siebert/sentiment-roberta-large-english as the reward model to evaluate the policy model output. The experimental results are shown in Figure 3.

As can be seen from Figure 3 (a), TDPO (TDPO1, TDPO2) can achieve a better reward-KL Pareto front than DPO, while from Figure 3 (b)-(d) It can be seen that TDPO performs extremely well in KL divergence control, which is far better than the KL divergence control capability of the DPO algorithm.
Anthropic HH
On the Anthropic/hh-rlhf data set, the team used Pythia 2.8B as the base model and used two methods to evaluate the quality of the model generation: 1) using existing indicators; 2 ) evaluated using GPT-4.
For the first evaluation method, the team evaluated the trade-offs in alignment performance (Accuracy) and generation diversity (Entropy) of models trained with different algorithms, as shown in Table 1.

It can be seen that the TDPO algorithm is not only better than DPO and f-DPO in alignment performance (Accuracy), but also has an advantage in generation diversity (Entropy), which is a key indicator of the response generated by these two large models. A better trade-off is achieved.
For the second evaluation method, the team evaluated the consistency between models trained by different algorithms and human preferences, and compared them with the winning responses in the data set, as shown in Figure 4.

DPO, TDPO1 and TDPO2 algorithms are all able to achieve a winning rate of higher than 50% for winning responses at a temperature coefficient of 0.75, which is better in line with human preferences.
MT-Bench
In the last experiment in the paper, the team used the Pythia 2.8B model trained on the Anthropic HH data set to directly use it for MT-Bench data set evaluation. The results are shown in Figure 5 Show.

On MT-Bench, TDPO is able to achieve a higher winning probability than other algorithms, which fully demonstrates the higher quality of responses generated by the model trained by the TDPO algorithm.
In addition, there are related studies comparing DPO, TDPO, and SimPO algorithms. Please refer to the link: https://www.zhihu.com/question/651021172/answer/3513696851
Based on the eval script provided by eurus, the evaluation The performance of the base models qwen-4b, mistral-0.1, and deepseek-math-base was obtained by fine-tuning training based on different alignment algorithms DPO, TDPO, and SimPO. The following are the experimental results:

Table 2: DPO, Performance comparison of TDPO and SimPO algorithms
For more results, please refer to the original paper.
The above is the detailed content of From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'. For more information, please follow other related articles on the PHP Chinese website!

 4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PM
4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PMPowerInfer提高了在消费级硬件上运行AI的效率上海交大团队最新推出了超强CPU/GPULLM高速推理引擎PowerInfer。PowerInfer和llama.cpp都在相同的硬件上运行,并充分利用了RTX4090上的VRAM。这个推理引擎速度有多快?在单个NVIDIARTX4090GPU上运行LLM,PowerInfer的平均token生成速率为13.20tokens/s,峰值为29.08tokens/s,仅比顶级服务器A100GPU低18%,可适用于各种LLM。PowerInfer与
 思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM
思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM要让大型语言模型(LLM)充分发挥其能力,有效的prompt设计方案是必不可少的,为此甚至出现了promptengineering(提示工程)这一新兴领域。在各种prompt设计方案中,思维链(CoT)凭借其强大的推理能力吸引了许多研究者和用户的眼球,基于其改进的CoT-SC以及更进一步的思维树(ToT)也收获了大量关注。近日,苏黎世联邦理工学院、Cledar和华沙理工大学的一个研究团队提出了更进一步的想法:思维图(GoT)。让思维从链到树到图,为LLM构建推理过程的能力不断得到提升,研究者也通
 复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM
复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM近期,复旦大学自然语言处理团队(FudanNLP)推出LLM-basedAgents综述论文,全文长达86页,共有600余篇参考文献!作者们从AIAgent的历史出发,全面梳理了基于大型语言模型的智能代理现状,包括:LLM-basedAgent的背景、构成、应用场景、以及备受关注的代理社会。同时,作者们探讨了Agent相关的前瞻开放问题,对于相关领域的未来发展趋势具有重要价值。论文链接:https://arxiv.org/pdf/2309.07864.pdfLLM-basedAgent论文列表:
 大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM
大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。大模型的预训练需要耗费大量的计算资源和数据,因此预训练模型的参数成为各大机构重点保护的核心竞争力和资产。然而,与传统软件知识产权保护不同,对预训练模型参数盗用的判断存在以下两个新问题:1)预训练模型的参数,尤其是千亿级别模型的参数,通常不会开源。预训练模型的输出和参数会受到后续处理步骤(如SFT、RLHF、continuepretraining等)的影响,这使得判断一个模型是否基于另一个现有模型微调得来变得困难。无
 FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AM
FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AMFATE2.0全面升级,推动隐私计算联邦学习规模化应用FATE开源平台宣布发布FATE2.0版本,作为全球领先的联邦学习工业级开源框架。此次更新实现了联邦异构系统之间的互联互通,持续增强了隐私计算平台的互联互通能力。这一进展进一步推动了联邦学习与隐私计算规模化应用的发展。FATE2.0以全面互通为设计理念,采用开源方式对应用层、调度、通信、异构计算(算法)四个层面进行改造,实现了系统与系统、系统与算法、算法与算法之间异构互通的能力。FATE2.0的设计兼容了北京金融科技产业联盟的《金融业隐私计算
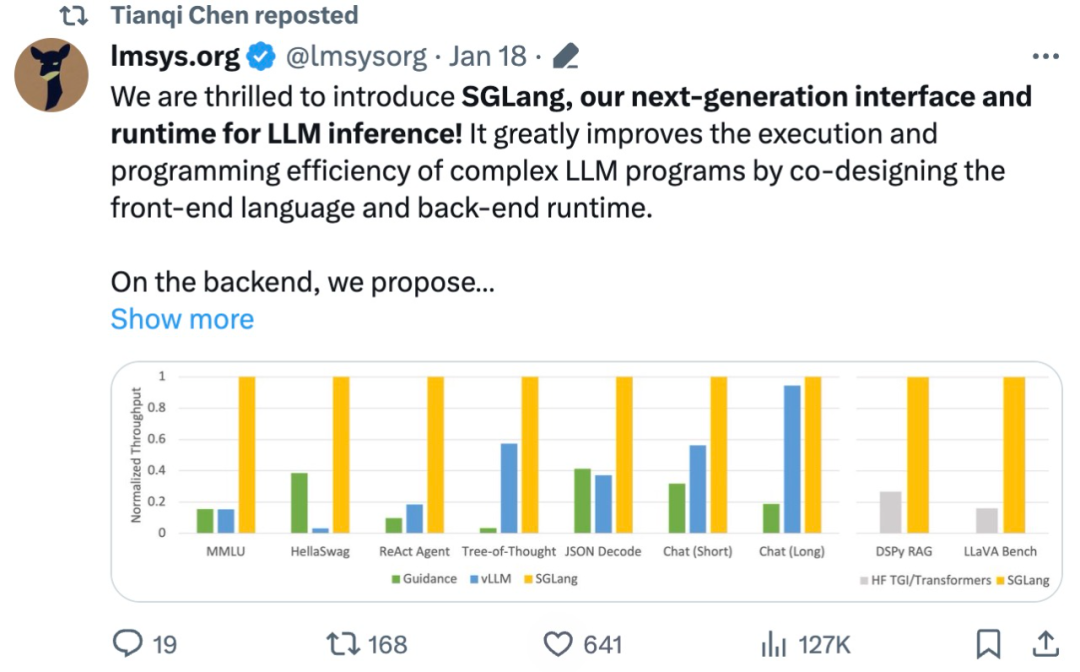 吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM
吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM大型语言模型(LLM)被广泛应用于需要多个链式生成调用、高级提示技术、控制流以及与外部环境交互的复杂任务。尽管如此,目前用于编程和执行这些应用程序的高效系统却存在明显的不足之处。研究人员最近提出了一种新的结构化生成语言(StructuredGenerationLanguage),称为SGLang,旨在改进与LLM的交互性。通过整合后端运行时系统和前端语言的设计,SGLang使得LLM的性能更高、更易控制。这项研究也获得了机器学习领域的知名学者、CMU助理教授陈天奇的转发。总的来说,SGLang的
 220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PM
220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PMIBM再度发力。随着AI系统的飞速发展,其能源需求也在不断增加。训练新系统需要大量的数据集和处理器时间,因此能耗极高。在某些情况下,执行一些训练好的系统,智能手机就能轻松胜任。但是,执行的次数太多,能耗也会增加。幸运的是,有很多方法可以降低后者的能耗。IBM和英特尔已经试验过模仿实际神经元行为设计的处理器。IBM还测试了在相变存储器中执行神经网络计算,以避免重复访问RAM。现在,IBM又推出了另一种方法。该公司的新型NorthPole处理器综合了上述方法的一些理念,并将其与一种非常精简的计算运行
 何恺明和谢赛宁团队成功跟随解构扩散模型探索,最终创造出备受赞誉的去噪自编码器Jan 29, 2024 pm 02:15 PM
何恺明和谢赛宁团队成功跟随解构扩散模型探索,最终创造出备受赞誉的去噪自编码器Jan 29, 2024 pm 02:15 PM去噪扩散模型(DDM)是目前广泛应用于图像生成的一种方法。最近,XinleiChen、ZhuangLiu、谢赛宁和何恺明四人团队对DDM进行了解构研究。通过逐步剥离其组件,他们发现DDM的生成能力逐渐下降,但表征学习能力仍然保持一定水平。这说明DDM中的某些组件对于表征学习的作用可能并不重要。针对当前计算机视觉等领域的生成模型,去噪被认为是一种核心方法。这类方法通常被称为去噪扩散模型(DDM),通过学习一个去噪自动编码器(DAE),能够通过扩散过程有效地消除多个层级的噪声。这些方法实现了出色的图


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SublimeText3 Chinese version
Chinese version, very easy to use

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

Dreamweaver CS6
Visual web development tools

