
 Technology peripheralsAICVPR 24|ETH Zurich and other teams: Redefining the small sample 3D segmentation task, the new benchmark opens up broad potential for improvement!
Technology peripheralsAICVPR 24|ETH Zurich and other teams: Redefining the small sample 3D segmentation task, the new benchmark opens up broad potential for improvement!

The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
The first author of this article, An Zhaochong, is currently studying for a PhD at the University of Copenhagen, under the supervision of Serge Belongie. He graduated with a master's degree from ETH Zurich. During his master's degree, he participated in multiple research projects in the laboratory of his mentor Luc Van Gool. His main research interests include scene understanding, few-shot learning, and multi-modal learning.
3D scene understanding allows humanoid robots to "see" the surrounding scene, allowing the car's autonomous driving function to perceive possible situations during driving in real time, thereby making more intelligent behaviors and reactions. All of this requires detailed annotation of a large number of 3D scenes, which sharply increases time cost and resource investment.

Paper link: https://arxiv.org/abs/2403.00592 Code link: https://github.com/ZhaochongAn/COSeg


The first problem is
- : 3D tasks usually uniformly sample dense points in the scene point cloud as the input of the model. However, the sampling method used by FS-PCS is not uniform sampling. Instead, it will sample more points for the target category (foreground area) and sample fewer points for the non-target area (background area). The input point cloud obtained in this way There will be a denser distribution of points in the foreground, resulting in foreground leakage problems. As shown in Figure 1, the input point clouds in the fourth and sixth columns come from the current biased sampling and show a denser point distribution in the foreground area (door or board) than in the background, while the input point clouds in the third and fifth columns The input uses corrected consistency sampling, exhibiting a uniform point density distribution. This problem causes the information of the new class to be leaked by the density distribution of the point cloud, allowing the model to simply exploit the density difference in the input point cloud and predict denser areas as foregrounds to achieve good few-shot performance. It does not rely on learning the ability to transfer knowledge from support to query. Therefore, the current evaluation
- benchmark cannot reflect the real performance of past models
. As shown in Table 1, after correcting the foreground leakage in the current setting, the past models showed a large performance drop, indicating that the past models relied heavily on density differences to achieve seemingly superior few-shot performance. The second problem is sparse point distribution: the current settingonly samples 2048 pointsfrom the scene as input to the model during training and testing. Such sparse point distribution severely limits the semantics of the input scene Clarity. As shown in Figure 1, in the first row and fifth column, it is difficult for the human eye to distinguish the semantic category door in the area from the surrounding category wall. For the second line, it is also difficult to distinguish whether the target area is the board class or another class such as window. These sparse input point clouds have very limited semantic information , - introducing significant ambiguity
and limiting the model’s ability to effectively mine the semantics in the scene. Therefore, in order to correct these problems, the author proposed a new setting to standardize the FS-PCS task , using uniform sampling and increasing the number of sampling points 10 times to 20480 points. As shown in the third column of Figure 1, the input under the new setting has a consistent point distribution and clearer semantic information, making the task closer to the real application scenario.
, which directly inputs the correlations between support and query into a module with parameters, and
In addition, since the few-shot model is trained on the base category and tested on the novel category. These models will be easily interfered by familiar base categories existing in the test scene, affecting the segmentation of novel categories. In order to solve this problem, the article proposes to learn parameter-free prototypes for the base category (called base prototypes). When

First, the authors identify two key issues in the current FS-PCS setting (
Solving the Base category interference problem is also a key factor affecting Few-shot performance. It can be optimized from the perspective of training or model design [5,6] to better reduce the Base category interference.
Improve the training and inference efficiency of the model [7], especially when deployed to practical applications, the efficiency of the model is also a key consideration. - In summary, this field has very broad prospects, and it is still in its emerging initial stage. For the majority of researchers, it is undoubtedly a research field full of hope and opportunities.
The above is the detailed content of CVPR 24|ETH Zurich and other teams: Redefining the small sample 3D segmentation task, the new benchmark opens up broad potential for improvement!. For more information, please follow other related articles on the PHP Chinese website!

 4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PM
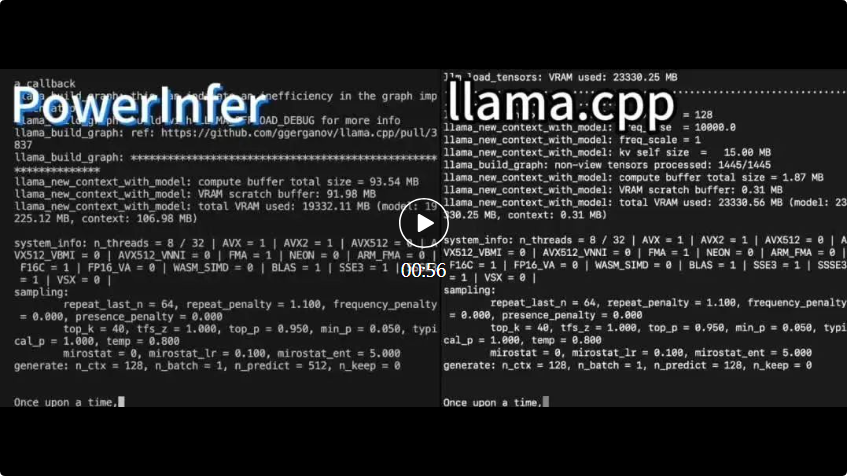
4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PMPowerInfer提高了在消费级硬件上运行AI的效率上海交大团队最新推出了超强CPU/GPULLM高速推理引擎PowerInfer。PowerInfer和llama.cpp都在相同的硬件上运行,并充分利用了RTX4090上的VRAM。这个推理引擎速度有多快?在单个NVIDIARTX4090GPU上运行LLM,PowerInfer的平均token生成速率为13.20tokens/s,峰值为29.08tokens/s,仅比顶级服务器A100GPU低18%,可适用于各种LLM。PowerInfer与
 思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM
思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM要让大型语言模型(LLM)充分发挥其能力,有效的prompt设计方案是必不可少的,为此甚至出现了promptengineering(提示工程)这一新兴领域。在各种prompt设计方案中,思维链(CoT)凭借其强大的推理能力吸引了许多研究者和用户的眼球,基于其改进的CoT-SC以及更进一步的思维树(ToT)也收获了大量关注。近日,苏黎世联邦理工学院、Cledar和华沙理工大学的一个研究团队提出了更进一步的想法:思维图(GoT)。让思维从链到树到图,为LLM构建推理过程的能力不断得到提升,研究者也通
 复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM
复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM近期,复旦大学自然语言处理团队(FudanNLP)推出LLM-basedAgents综述论文,全文长达86页,共有600余篇参考文献!作者们从AIAgent的历史出发,全面梳理了基于大型语言模型的智能代理现状,包括:LLM-basedAgent的背景、构成、应用场景、以及备受关注的代理社会。同时,作者们探讨了Agent相关的前瞻开放问题,对于相关领域的未来发展趋势具有重要价值。论文链接:https://arxiv.org/pdf/2309.07864.pdfLLM-basedAgent论文列表:
 吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM
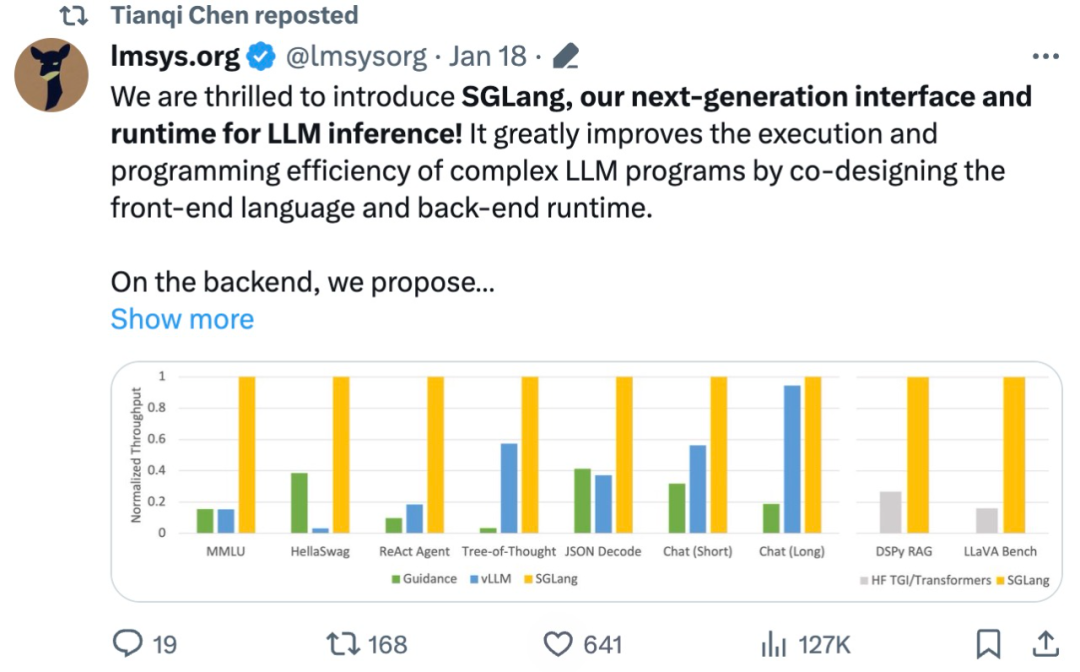
吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM大型语言模型(LLM)被广泛应用于需要多个链式生成调用、高级提示技术、控制流以及与外部环境交互的复杂任务。尽管如此,目前用于编程和执行这些应用程序的高效系统却存在明显的不足之处。研究人员最近提出了一种新的结构化生成语言(StructuredGenerationLanguage),称为SGLang,旨在改进与LLM的交互性。通过整合后端运行时系统和前端语言的设计,SGLang使得LLM的性能更高、更易控制。这项研究也获得了机器学习领域的知名学者、CMU助理教授陈天奇的转发。总的来说,SGLang的
 大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM
大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。大模型的预训练需要耗费大量的计算资源和数据,因此预训练模型的参数成为各大机构重点保护的核心竞争力和资产。然而,与传统软件知识产权保护不同,对预训练模型参数盗用的判断存在以下两个新问题:1)预训练模型的参数,尤其是千亿级别模型的参数,通常不会开源。预训练模型的输出和参数会受到后续处理步骤(如SFT、RLHF、continuepretraining等)的影响,这使得判断一个模型是否基于另一个现有模型微调得来变得困难。无
 FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AM
FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AMFATE2.0全面升级,推动隐私计算联邦学习规模化应用FATE开源平台宣布发布FATE2.0版本,作为全球领先的联邦学习工业级开源框架。此次更新实现了联邦异构系统之间的互联互通,持续增强了隐私计算平台的互联互通能力。这一进展进一步推动了联邦学习与隐私计算规模化应用的发展。FATE2.0以全面互通为设计理念,采用开源方式对应用层、调度、通信、异构计算(算法)四个层面进行改造,实现了系统与系统、系统与算法、算法与算法之间异构互通的能力。FATE2.0的设计兼容了北京金融科技产业联盟的《金融业隐私计算
 220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PM
220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PMIBM再度发力。随着AI系统的飞速发展,其能源需求也在不断增加。训练新系统需要大量的数据集和处理器时间,因此能耗极高。在某些情况下,执行一些训练好的系统,智能手机就能轻松胜任。但是,执行的次数太多,能耗也会增加。幸运的是,有很多方法可以降低后者的能耗。IBM和英特尔已经试验过模仿实际神经元行为设计的处理器。IBM还测试了在相变存储器中执行神经网络计算,以避免重复访问RAM。现在,IBM又推出了另一种方法。该公司的新型NorthPole处理器综合了上述方法的一些理念,并将其与一种非常精简的计算运行
 制作莫比乌斯环,最少需要多长纸带?50年来的谜题被解开了Oct 07, 2023 pm 06:17 PM
制作莫比乌斯环,最少需要多长纸带?50年来的谜题被解开了Oct 07, 2023 pm 06:17 PM自己动手做过莫比乌斯带吗?莫比乌斯带是一种奇特的数学结构。要构造一个这样美丽的单面曲面其实非常简单,即使是小孩子也可以轻松完成。你只需要取一张纸带,扭曲一次,然后将两端粘在一起。然而,这样容易制作的莫比乌斯带却有着复杂的性质,长期吸引着数学家们的兴趣。最近,研究人员一直被一个看似简单的问题困扰着,那就是关于制作莫比乌斯带所需纸带的最短长度?布朗大学RichardEvanSchwartz谈到,对于莫比乌斯带来说,这个问题没有解决,因为它们是「嵌入的」而不是「浸入的」,这意味着它们不会相互渗透或自我


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Zend Studio 13.0.1
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

