AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
上海交通大学生成式人工智能实验室(GAIR Lab)的研究团队,主要研究方向是:大模型训练、对齐与评估。团队主页:https://plms.ai/
在未来20年内,AI有望超过人类的智能水平。图灵奖得主Hinton在他的访谈中提及“在未来20年内,AI有望超越人类的智能水平”,并建议各大科技公司早做准备,评定大模型(包括多模态大模型)的“智力水平”则是这一准备的必要前提。
一个具有跨学科问题集、可以从多维度严谨评估AI的认知推理能力评估基准已经变得相当亟需。
1. 大模型不断占领人类智力高地:从小学试题到参加高考
以大模型为核心的生成式人工智能技术的兴起,使得人类不仅有了可交互的文本、From the college entrance examination to the Olympic arena: the ultimate battle between large models and human intelligence、视频交互生成工具,还使得人类有机会训练出一个”有智力“能力的模型,它可以看成是人类延申的大脑,独立完成不同学科问题,成为未来10年可以给科学发现提供加速度的最有力的工具(即AI4Science)。过去两年,我们看到这种以大模型为代表的硅基智能的快速进化,从最初只能用来去解决小学题目, 到2022年,CMU等人[1]第一次把AI带到了“高考”考场,并在全国卷II英语上取得了134分的成绩,然而,那时候的AI还是个数理逻辑掌握不好的偏科生。直至今年,2024高考刚刚落下帷幕,在无数学子在这一年一度的大考中奋力拼搏,展现了他们多年来的学习成果的同时,大模型也是空前第一次被全学科的拉到考场,并且在数理学科中取得巨大进步。这里我们不禁思考,AI智力进化的天花板在哪?人类还没祭出最难的题目,那会是AI的天花板吗?
2. 智力较量最高殿堂:从 AI 高考到 AI 奥运会四年一度的奥运会也即将到来,这不仅是体育竞技的巅峰盛会,更象征着人类对极限的不断追求和突破。学科奥林匹克竞赛则是知识的深度与智力的极限的完美结合,它既是对学术成就的严格评估,也是对思维敏捷性和创新能力的极限挑战。在这里,科学的严谨与奥运会的激情相遇,共同塑造了一种追求卓越、勇于探索的精神。学科的奥林匹克竞赛给将会给人机智力巅峰对决提供最好的赛场。不管未来AGI能否实现,AI参加奥林匹克竞赛将会成为通向AGI的必经一站,因为这些考察了模型极具重要的 认知推理能力,而这些能力逐渐被体现于各种复杂的现实世界场景中,比如用作软件开发的AI代理,合作处理复杂的决策过程,甚至推动科学研究领域(AI4Science)。
在此背景下,上海交通大学生成式人工智能实验室 (GAIR Lab) 的研究团队将大模型从高考考场搬到了更加具有挑战性的“奥林匹克竞技场”,推出了全新的大模型(包括多模态大模型)认知推理能力评估基准——OlympicArena。这一基准使用国际学科奥赛的高难度题目,全面测试了人工智能在跨学科领域的认知推理能力。OlympicArena涵盖了数学、物理、化学、生物、地理、天文、计算机七大核心学科,包括62个国际学科奥赛(如IMO, IPhO, IChO, IBO, ICPC等)的11,163道中英双语题目,为研究者们提供了一个全面评估AI模型的理想平台。同时,更长远来看,OlympicArena为今后AI在科学领域(AI4Science),工程领域(AI4Engineering)发挥自身强大的能力,甚至促进AI激发出超越人类水平达到Superintelligence,起到了不可忽视的奠定作用。
研究团队发现,当下所有的大模型在学科奥赛上都不能交出较好的答卷,即使是GPT-4o,仅仅只有39%的正确率,GPT-4V仅有33%,离及格线(60%正确率)还有相当大的距离。而多数开源大模型表现的更加不尽人意,例如,LLaVa-NeXT-34B, InternVL-Chat-V1.5等当下较强的多模态大模型都未达到20%的正确率。此外,多数多模态大模型都不擅长充分利用视觉信息解决复杂的推理任务,这也是大模型与人类最显著的差异(人类往往会优先关注处理视觉信息)。因此,OlympicArena上的测试结果表明模型在科学问题的求解上与人类依然有所差距,其内在的推理能力仍然需要不断提高才能更好的辅助人类的科学研究。
- 论文地址:https://arxiv.org/pdf/2406.12753
- 项目地址:https://gair-nlp.github.io/OlympicArena/
- 代码地址:https://github.com/GAIR-NLP/OlympicArena
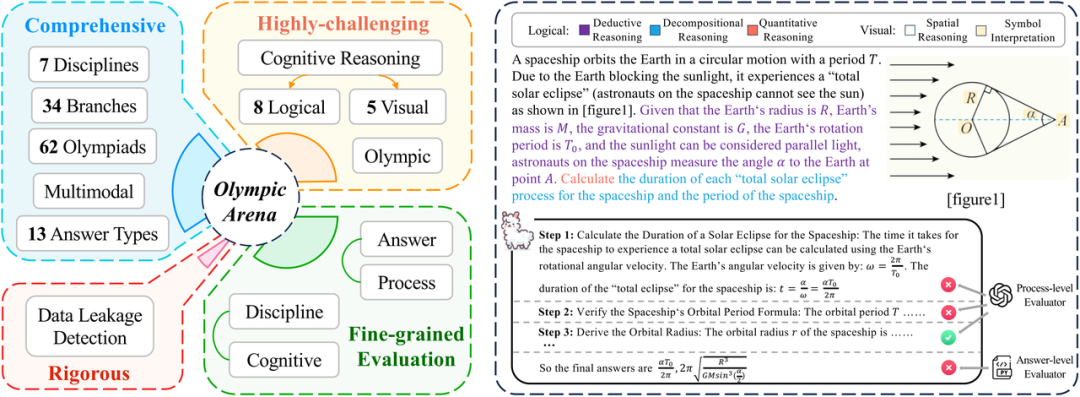
OlympicArena的特点概述了它对多模态支持、多种认知能力考察以及细粒度评估(既考虑对错的评估,又考虑每个推理步骤评估)的例子。
- Comprehensive: OlympicArena includes a total of 11,163 questions from 62 different Olympic competitions, spanning seven core subjects: mathematics, physics, chemistry, biology, geography, astronomy and computer, involving 34 professional branches. At the same time, unlike previous benchmarks that mostly focused on objective questions such as multiple-choice questions, OlympicArena supports a variety of question types, including expressions, equations, intervals, writing chemical equations and even programming questions. In addition, OlympicArena supports multi-modality (nearly half of the questions contain pictures), and adopts the most realistic text-image input format (interleaved text-image), fully testing the use of visual information to assist large models in solving problems. The ability to reason.
- Extremely challenging: Unlike previous benchmarks that either focused on high school (college entrance exam) questions or college questions, OlympicArena focuses more on the pure examination of complex reasoning abilities rather than on the massive knowledge of large models. Points of memory, recall ability or simple application ability. Therefore, all questions in OlympicArena are of Olympiad difficulty level. Moreover, in order to fine-grainedly evaluate the performance of large models in different types of reasoning capabilities, the research team also summarized 8 types of logical reasoning capabilities and 5 types of visual reasoning capabilities. Subsequently, they specifically analyzed the performance of existing large models in different types of reasoning capabilities. Differences in performance on reasoning abilities.
- Rigor: Guiding the healthy development of large models is the role that academia should play. Currently, in public benchmarks, many popular large models will have data leakage problems (that is, the test data of the benchmark is leaked in the large model) in the training data). Therefore, the research team specifically tested the data leakage of OlympicArena on some popular large models to more rigorously verify the effectiveness of the benchmark.
- Fine-grained evaluation: Previous benchmarks often only evaluate whether the final answer given by a large model is consistent with the correct answer. This is one-sided in the evaluation of very complex reasoning problems and cannot well reflect the current model. More realistic reasoning skills. Therefore, in addition to evaluating the answers, the research team also included an evaluation of the correctness of the question process (steps). At the same time, the research team also analyzed different results from multiple different dimensions, such as analyzing the performance differences of models in different disciplines, different modalities, and different reasoning capabilities.
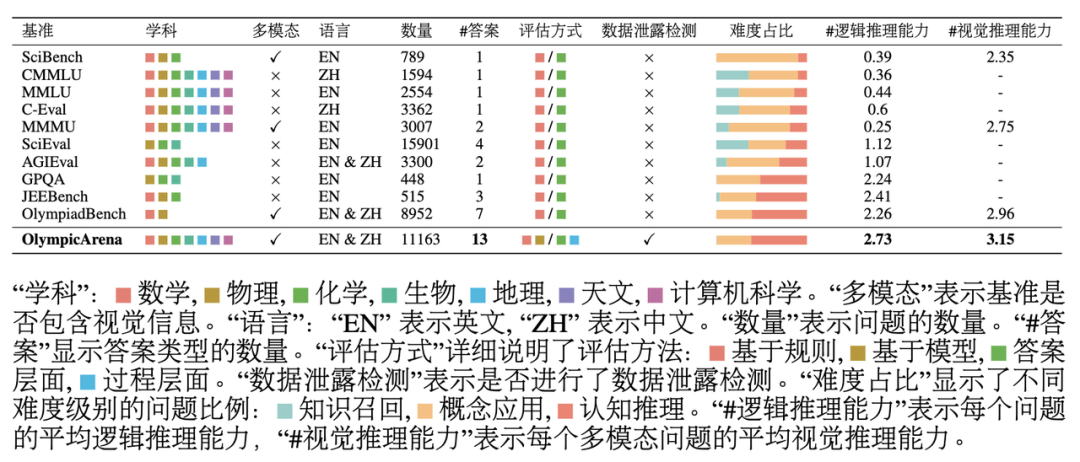
Comparison with related benchmarks
As can be seen from the above table: OlympicArena has great impact on reasoning ability in terms of coverage of subjects, languages, and modalities, as well as the diversity of question types. The depth of investigation and the comprehensiveness of the evaluation method are significantly different from other existing benchmarks that focus on evaluating scientific issues. The research team tested multiple multimodal large models (LMM) and plain text large models (LLM) on OlympicArena . For the multi-modal large model, the input form of interleaved text-image was used; for the large plain text model, tests were conducted under two settings, namely plain text input without any picture information. (text-only LLMs) and plain text input containing image description information (image caption + LLMs). The purpose of adding plain text large model testing is not only to expand the scope of application of this benchmark (so that all LLMs can participate in the rankings), but also to better understand and analyze the performance of existing multi-modal large models in their corresponding Compared with large plain text models, whether it can make full use of picture information to improve its problem-solving ability. All experiments used zero-shot CoT prompts, which the research team customized for each answer type and specified the output format to facilitate answer extraction and rule-based matching.
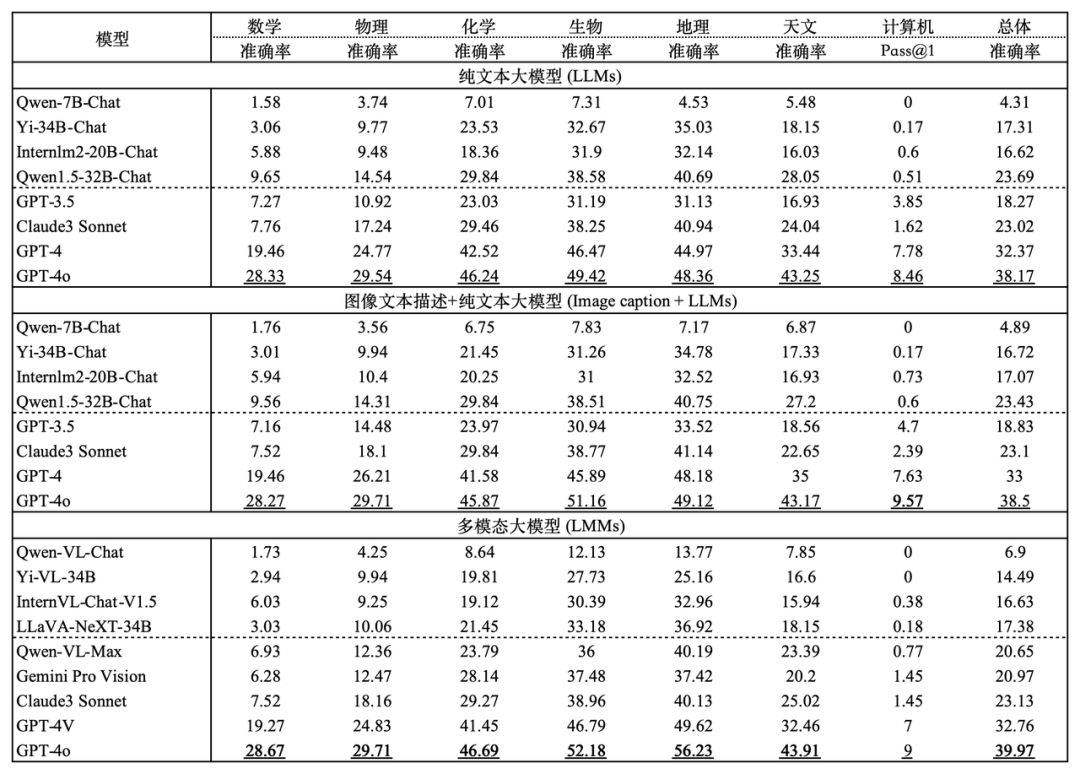
The accuracy of different models in different subjects of OlympicArena. The CS programming questions use the unbiased pass@k index, and the rest use the accuracy index.
It can be seen from the experimental results in the table that all mainstream large models currently on the market have failed to show a high level. Even the most advanced large model GPT-4o has an overall accuracy of only 39.97%, while other The overall accuracy of the open source model is difficult to reach 20%. This obvious difference highlights the challenge of this benchmark and proves that it has played a great role in pushing the upper limit of current AI reasoning capabilities. In addition, the research team observed that mathematics and physics are still the two most difficult subjects, because they rely more on complex and flexible reasoning abilities, have more steps in reasoning, and require more comprehensive and applied thinking skills. Diverse. In subjects such as biology and geography, the accuracy rate is relatively high, because these subjects pay more attention to the ability to use rich scientific knowledge to solve and analyze practical problems, focusing on the examination of abduction and causal reasoning abilities. Compared with complex induction, , deductive reasoning, large models are more adept at analyzing such subjects with the help of rich knowledge acquired during their own training stage. Computer programming competitions have also proven to be very difficult, with some open source models not even able to solve any of the problems in them (0 accuracy), which shows how capable current models are in designing effective algorithms to solve complex problems programmatically There is still a lot of room for improvement. It is worth mentioning that the original intention of OlympicArena was not to blindly pursue the difficulty of the questions, but to fully tap the ability of large models to cross disciplines and use multiple reasoning capabilities to solve practical scientific problems. The above-mentioned thinking ability using complex reasoning, the ability to use rich scientific knowledge to solve and analyze practical problems, and the ability to write efficient and accurate programs to solve problems are all indispensable in the field of scientific research, and have always been the benchmark for this benchmark. Focused. Fine-grained experimental analysisIn order to achieve a more fine-grained analysis of experimental results, the research team conducted further evaluation based on different modalities and reasoning capabilities. In addition, the research team also conducted evaluation and analysis of the model's reasoning process on questions. The main findings are as follows: The models perform differently in different logical reasoning and visual reasoning abilities
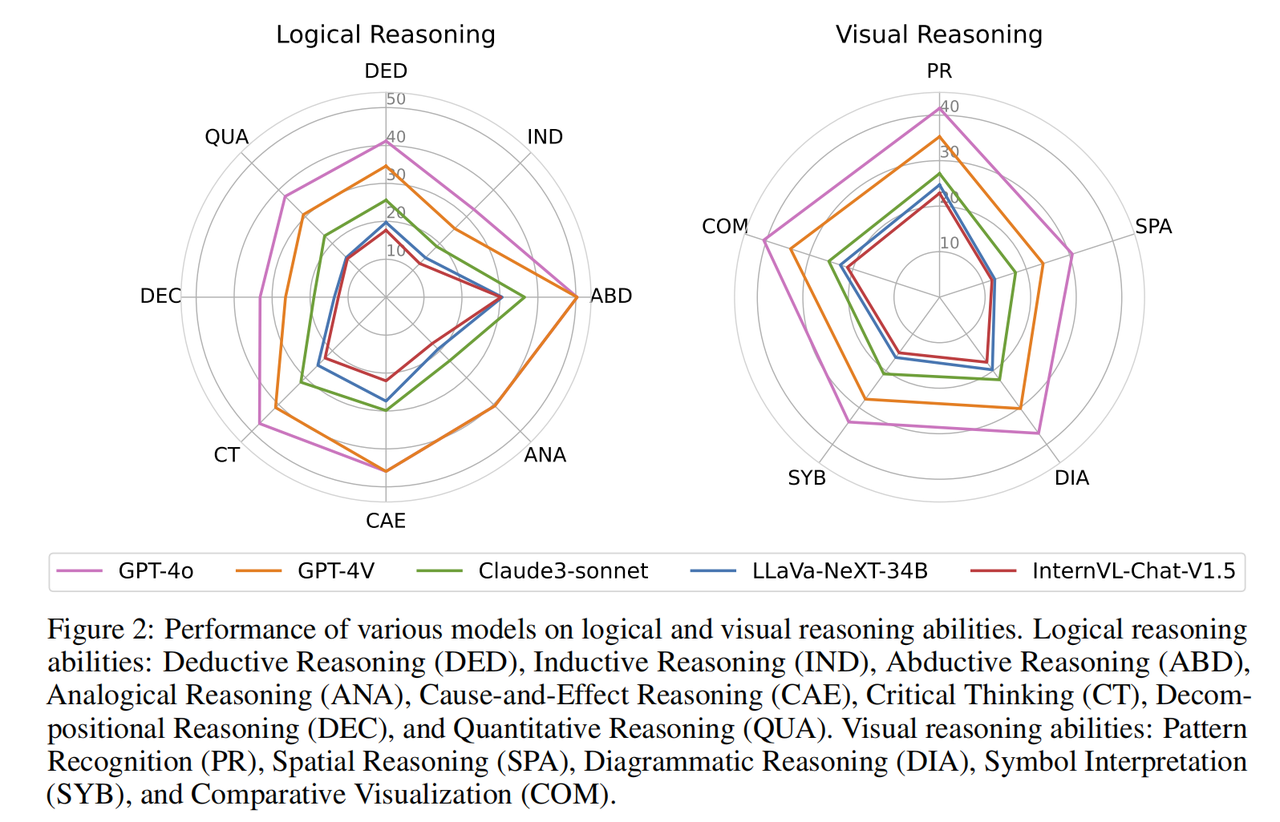
The performance of each model in logical reasoning and visual reasoning abilities. Logical reasoning abilities include: deductive reasoning (DED), inductive reasoning (IND), abductive reasoning (ABD), analogical reasoning (ANA), causal reasoning (CAE), critical thinking (CT), decomposition reasoning (DEC) and quantitative Reasoning (QUA). Visual reasoning abilities include: pattern recognition (PR), spatial reasoning (SPA), diagrammatic reasoning (DIA), symbolic interpretation (SYB), and visual comparison (COM).
Almost all models have similar performance trends in different logical reasoning capabilities. They excel in abductive and causal reasoning and are well able to identify cause and effect relationships from the information provided. In contrast, the model performs poorly on inductive reasoning and decomposition reasoning. This is due to the variety and non-routine nature of Olympic-level problems, which require the ability to break complex problems into smaller sub-problems, which relies on the model to successfully solve each sub-problem and combine the sub-problems to solve the larger problem. The problem. In terms of visual reasoning capabilities, the model performed better in pattern recognition and visual comparison. However, they have difficulty performing tasks involving spatial and geometric reasoning, as well as tasks that require understanding abstract symbols. From the fine-grained analysis of different reasoning abilities, the abilities that large models lack (such as decomposition of complex problems, visual reasoning of geometric figures, etc.) are indispensable and crucial abilities in scientific research, indicating that There is still a long way to go before AI can truly assist humans in scientific research in all aspects.
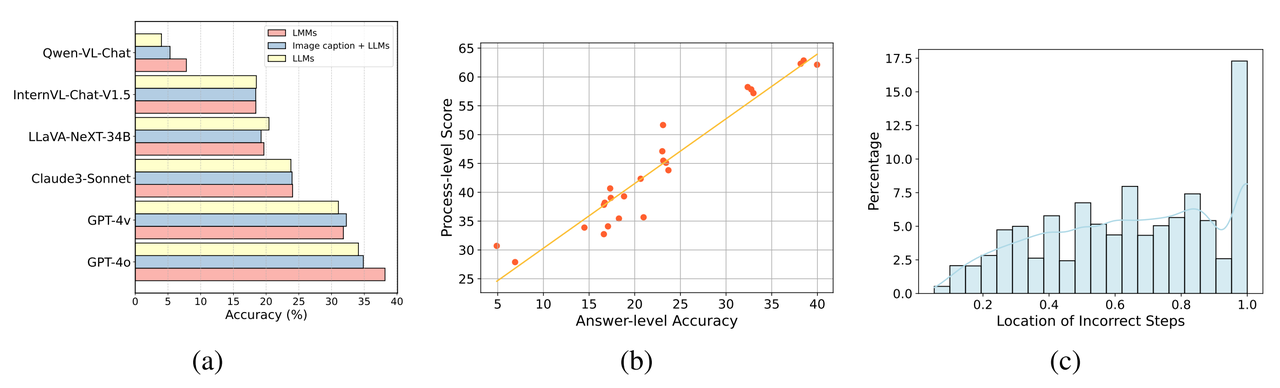
Comparison of different multimodal models (LMMs) and their corresponding text-only models (LLMs) in three different experimental settings.
Most multi-modal models (LMMs) are still not good at utilizing visual information to assist in reasoningAs shown in (a) above, there are only a few large multi-modal models (such as GPT-4o and Qwen-VL -Chat) shows significant performance improvements relative to its text-only counterpart when given image input. Many large multi-modal models do not show performance improvement when image input, or even show performance degradation when processing images. Possible reasons include:
- When text and images are input together, LMMs may pay more attention to the text and ignore the information in the image.
- Some LMMs may lose some of their inherent language capabilities (e.g., reasoning capabilities) when training visual capabilities based on their text models, which is especially obvious in the complex scenarios of this project.
- This benchmark question uses a complex text-image wrapping input format. Some models cannot support this format well, resulting in their inability to process and understand image position information embedded in text.
In scientific research, it is often accompanied by a very large amount of visual information such as charts, geometric figures, and visual data. Only when AI can skillfully use its visual capabilities to assist reasoning can it help promote The efficiency and innovation of scientific research have become powerful tools for solving complex scientific problems.
Left picture: The correlation between the correctness of the answers and the correctness of the process for all models in all questions where the inference process is evaluated. Right: Distribution of locations of erroneous process steps.
Analysis of evaluation results of the inference stepBy conducting a fine-grained evaluation of the correctness of the model inference step, the research team found:
- As shown in (b) above, step-level evaluation There is usually a high degree of agreement between the results of and assessments that rely solely on answers. When a model generates correct answers, the quality of its inference process is mostly higher.
- The accuracy of the reasoning process is usually higher than the accuracy of just looking at the answers. This shows that even for very complex problems, the model can correctly perform some intermediate steps. Therefore, models may have significant potential in cognitive reasoning, which opens up new research directions for researchers. The research team also found that in some disciplines, some models that performed well when evaluated solely on answers performed poorly on the inference process. The research team speculates that this is because models sometimes ignore the plausibility of intermediate steps when generating answers, even though these steps may not be critical to the final result.
- In addition, the research team conducted a statistical analysis of the location distribution of error steps (see Figure c) and found that a higher proportion of errors occurred in the later reasoning steps of a question. This shows that as the reasoning process accumulates, the model is more prone to errors and produces an accumulation of errors, which shows that the model still has a lot of room for improvement when dealing with long-chain logical reasoning.
The team also calls on all researchers to pay more attention to the supervision and evaluation of the model inference process in AI inference tasks. This can not only improve the credibility and transparency of the AI system and help better understand the model's reasoning path, but also identify the weak links of the model in complex reasoning, thereby guiding the improvement of model structure and training methods. Through careful process supervision, the potential of AI can be further explored and its widespread use in scientific research and practical applications promoted. Analysis of model error types
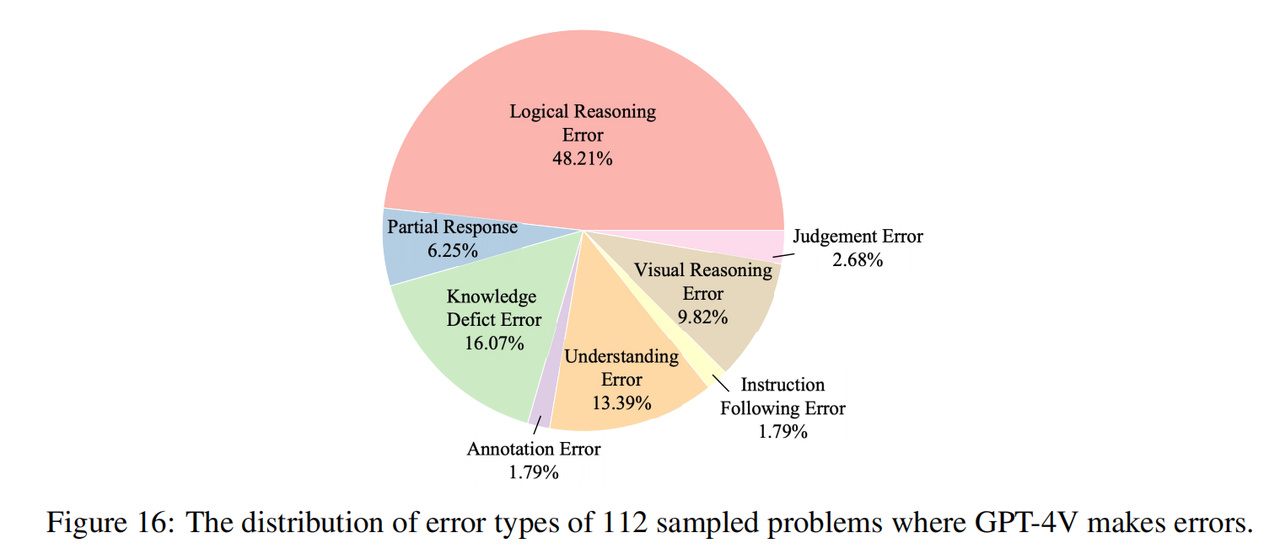
The research team sampled 112 questions in GPT-4V that were answered incorrectly (16 questions in each subject, 8 of which were plain text questions and 8 were multi-modal questions), and manually marked the reasons for these errors. As shown in the figure above, reasoning errors (including logical reasoning errors and visual reasoning errors) constitute the largest cause of errors, which shows that our benchmark effectively highlights the shortcomings of current models in cognitive reasoning capabilities, which is consistent with the original intention of the research team of. In addition, a considerable part of the errors also come from the lack of knowledge (although the Olympiad questions are only based on high school knowledge), which shows that the current model lacks domain knowledge and is more unable to use this knowledge to assist reasoning. Another common cause of errors is comprehension bias, which can be attributed to the model’s misunderstanding of context and difficulty integrating complex language structures and multimodal information.
An example of GPT-4V making mistakes on a Mathematical Olympiad question
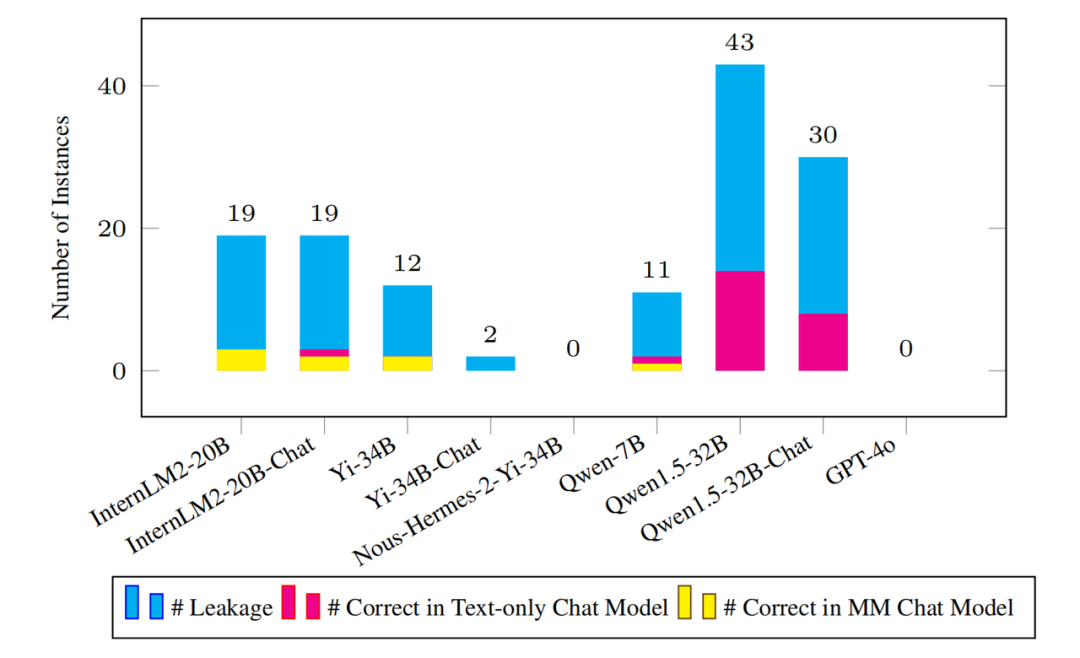
The number of leaked samples detected and the corresponding plain text and multi-modal models on these sample questions Make the right amount.
As the scale of pre-training corpus continues to expand, it is crucial to detect potential data leaks on the benchmark. The opacity of the pre-training process often makes this task challenging. To this end, the research team adopted a newly proposed instance-level leak detection metric called "N-gram prediction accuracy." This metric evenly samples several starting points from each instance, predicts the next N-gram for each starting point, and checks whether all predicted N-grams are correct to determine whether the model may have encountered it during the training phase. this instance. The research team applied this metric to all available base models. As shown in the figure above, the mainstream model does not have significant data leakage problems on Olympic Arena. Even if there is a leak, the amount is insignificant compared to the complete benchmark data set. For example, the Qwen1.5-32B model with the most leaks only had 43 suspected leak instances detected. This naturally raises the question: Can the model correctly answer these leaked instance questions? On this issue, the research team was surprised to find that even for leaked questions, the corresponding model could answer very few questions correctly. These results indicate that the benchmark has suffered almost no impact from data breaches and remains quite challenging to maintain its effectiveness for a long time to come.
Although OlympicArena has very high value, the research team stated that there is still a lot of work to be done in the future. First of all, the OlympicArena benchmark will inevitably introduce some noisy data, and the author will actively use community feedback to continuously improve and improve it. In addition, the research team plans to release new versions of the benchmark every year to further mitigate issues related to data breaches. Furthermore, in the longer term, current benchmarks are limited to evaluating a model's ability to solve complex problems. In the future, everyone hopes that artificial intelligence can assist in completing complex comprehensive tasks and demonstrate value in practical applications, such as AI4Science and AI4Engineering, which will be the goal and purpose of future benchmark design. Despite this, Olympic Arena still plays an important role as a catalyst in promoting AI towards superintelligence.
Vision: A glorious moment of joint progress between humans and AI
In the future, we have reason to believe that as AI technology continues to mature and application scenarios continue to expand, OlympicArena will be more than just a venue for evaluating AI capabilities , will become a stage to demonstrate the application potential of AI in various fields. Whether in scientific research, engineering design, or in broader fields such as sports competition, AI will contribute to the development of human society in its own unique way. Finally, the research team also said that the Subject Olympics will be just the beginning of the OlympicArena, and more capabilities of AI are worthy of continuous exploration. For example, the Olympic sports arena will become an arena of embodied intelligence in the future. [1] reStructured Pre-training, arXiv 2022, Weizhe Yuan, Pengfei LiuThe above is the detailed content of From the college entrance examination to the Olympic arena: the ultimate battle between large models and human intelligence. For more information, please follow other related articles on the PHP Chinese website!
Statement:The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn