


The performance exceeds Llama-3 and is mainly used for synthetic data.



 #ision
#ision 


The above is the detailed content of NVIDIA's most powerful open source universal model Nemotron-4 340B. For more information, please follow other related articles on the PHP Chinese website!

 NVIDIA 控制面板无法在 Windows 11 中打开/工作问题修复Apr 13, 2023 pm 11:10 PM
NVIDIA 控制面板无法在 Windows 11 中打开/工作问题修复Apr 13, 2023 pm 11:10 PMNVIDIA 控制面板包含您可以调整的所有内容和设置,以提取显卡的全部功能。因此,当 NVIDIA 控制面板停止工作时,您无法更改许多想要更改的设置,除非您找到修复程序以再次制作 NVIDIA 控制面板。修复 1 – 杀死所有 NVIDIA 进程您必须终止所有 NVIDIA 进程并重新启动文件资源管理器进程。1. 尝试打开 NVIDIA 控制面板。Windows 将尝试启动 NVIDIA 控制面板。它不会打开。不用担心。2. 现在,只需右键单击 Windows 图标,然后点击“任务管理器”。4.
 NVIDIA 安装程序无法继续?4个简单的方法来解决它Jun 03, 2023 am 09:52 AM
NVIDIA 安装程序无法继续?4个简单的方法来解决它Jun 03, 2023 am 09:52 AMNVIDIA安装程序无法继续是一条错误消息,会阻止您为显卡安装驱动程序。无论您尝试在计算机上安装多少次,您几乎肯定会一遍又一遍地收到相同的消息。此外,此错误发生在各种驱动程序和Windows迭代中,表明存在多种潜在原因。也就是说,它不排除任何人,对于许多用户来说,解决问题可能是一种令人沮丧的体验。幸运的是,以下方法中的一种(如果不是更多)很有可能对您有效,因此请继续阅读以找出哪种方法最有效。即使驱动安装失败,在您下载并安装驱动后,安装操作系统的分区中也会创建一个NVIDIA文件夹。这是因为它会在
 NVIDIA控制面板打不开问题修复May 19, 2023 pm 03:22 PM
NVIDIA控制面板打不开问题修复May 19, 2023 pm 03:22 PM在Windows中,NVIDIA控制面板基本上是一种用于管理显卡中的图形驱动程序设置和NVIDIA实用程序的工具。显卡对于游戏、3D动画和渲染视频非常重要。所以,我们需要一个控制面板来管理显卡的设置。它将帮助用户更改显示质量、大小、方向等。有时由于使用了错误的图形驱动程序,控制面板无法打开或工作。每个图形适配器都有一个特定的图形驱动程序,因此选择正确的驱动程序将为您提供最佳的游戏优化。在某些情况下,系统中使用的防病毒软件可能会产生一些干扰。让我们看看解决此问题的一些方法NVIDIA无法
 在 Windows 11 上使用的最佳 Nvidia 驱动程序是什么?May 22, 2023 pm 04:12 PM
在 Windows 11 上使用的最佳 Nvidia 驱动程序是什么?May 22, 2023 pm 04:12 PMNVIDIA生产了许多业内最佳的显卡。多年来,它不断为PC游戏玩家、动画师、平面设计师、视频编辑和其他GPU密集型职业提供GPU。但是,您必须确保在您的操作系统上使用兼容的NVIDIA驱动程序。虽然Windows11具有适应性,但并非您在其他操作系统上使用过的所有驱动程序都可以正常工作。在这里,我们将分享与Windows11PC兼容的最佳NVIDIA显卡驱动程序。最后,您可以按照几个简单的步骤来纠正NVIDIA控制面板的问题,而不是打开.Windows11是否有N
 修复 Windows 11 中缺少的 NVIDIA 控制面板的 5 个技巧Apr 19, 2023 pm 05:10 PM
修复 Windows 11 中缺少的 NVIDIA 控制面板的 5 个技巧Apr 19, 2023 pm 05:10 PM几位NVIDIA显卡用户报告说,Windows11中缺少NVIDIA控制面板。造成这种情况的可能原因有多种,包括显卡驱动程序错误、软件过时、注册表子项和值丢失,或随机错误。除了提供对NVIDIA图形驱动程序设置的控制之外,该面板还允许您访问和使用您可能已安装在系统上的其他NVIDIA实用程序。建议您在获得运行显卡所需的驱动程序后立即下载并在您的设备上安装NVIDIA控制面板。该软件的使用对于那些使用3D应用程序或狂热的Windows游戏玩家特别有益。您可以详细了解您的系统在使
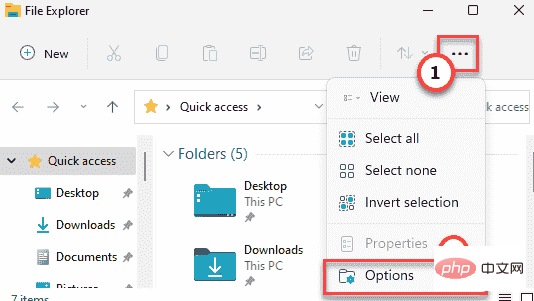 修复:没有 Dc 水印 NVIDIA / 游戏 - 屏幕左上角的 Adobe 没有 DcApr 30, 2023 am 08:22 AM
修复:没有 Dc 水印 NVIDIA / 游戏 - 屏幕左上角的 Adobe 没有 DcApr 30, 2023 am 08:22 AM一些NVIDIAStudio驱动程序用户最近报告了在AdobePremierePro应用程序上看到“NODC”水印的问题。一些用户还报告说也看到了“YESDC”水印。但是,别担心。这都是由于NVIDIA核心文件中的bin文件损坏所致。因此,只需在文件资源管理器中找到该文件并删除损坏的文件,然后重新启动即可解决问题。或者,您可以只恢复默认的NVIDIA3d设置。按照这些修复程序快速解决问题。修复1–删除NVIDIAbin文件按照以下步骤从系统中删除n
 和TensorFlow一样,英伟达CUDA的垄断格局将被打破?Apr 13, 2023 pm 01:04 PM
和TensorFlow一样,英伟达CUDA的垄断格局将被打破?Apr 13, 2023 pm 01:04 PM十年来,机器学习软件开发的格局发生了重大变化。许多框架如雨后春笋般涌现,但大多数都严重依赖于英伟达的 CUDA,并在英伟达的 GPU 上才能获得最佳的性能。然而,随着 PyTorch 2.0 和 OpenAI Triton 的到来,英伟达在这一领域的主导地位正在被打破。谷歌早期在机器学习模型架构、训练、模型优化方面都具有很大优势,但现在却难以充分发挥这些优势。而在硬件方面,其他 AI 硬件公司很难削弱英伟达的统治地位。直到 PyTorch 2.0 和 OpenAI Triton 出现,机器学习
 英伟达发布ChatGPT专用GPU,推理速度提升了10倍May 13, 2023 pm 11:04 PM
英伟达发布ChatGPT专用GPU,推理速度提升了10倍May 13, 2023 pm 11:04 PM曾何几时,人工智能因为算力不足进入了长达数十年的瓶颈,GPU点燃了深度学习。在ChatGPT时代,AI因为大模型再次面临算力不足的问题,这一次英伟达还有办法吗?3月22日,GTC大会正式召开,在刚刚进行的Keynote上,英伟达CEO黄仁勋搬出了为ChatGPT准备的芯片。「加速计算并非易事,2012年,计算机视觉模型AlexNet动用了GeForceGTX580,每秒可处理262PetaFLOPS。该模型引发了AI技术的爆炸,」黄仁勋说道。「十年之后,Tr


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Dreamweaver CS6
Visual web development tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

WebStorm Mac version
Useful JavaScript development tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

