

 Technology peripheralsAILeCun's new work: layered world model, data-driven humanoid robot control
Technology peripheralsAILeCun's new work: layered world model, data-driven humanoid robot controlLeCun's new work: layered world model, data-driven humanoid robot control

With large models as an intellectual blessing, humanoid robots have become a new trend.
The robot in the science fiction movie "can tell that I am not a human being" seems to be getting closer.
However, it is still a difficult engineering problem for robots, especially humanoid robots, to think and act like humans.
Take a simple learning to walk as an example, using reinforcement learning to train may evolve into the following:

There is no problem in theory (following the reward mechanism), and the goal of going up the stairs has been achieved. Except that the process is relatively abstract and may not be the same as most human behavior patterns.
The reason it is difficult for robots to act "naturally" like humans is due to the high-dimensional nature of the observation and action space, as well as the inherent instability of the bipedal form.
In this regard, a work LeCun participated in provided a new solution based on data-driven.

Paper address: https://arxiv.org/pdf/2405.18418
Project introduction: https://nicklashansen.com/rlpuppeteer
Let’s look at the efficacy first:

Compare the effect on the right , the new method trains behavior that is closer to human beings. Although it has a bit of a "zombie" meaning, the abstraction level has been reduced a lot, at least within the capabilities of most humans.
Of course, some netizens who came to cause trouble said, "The one before looked more interesting."

In this work, researchers explore a reinforcement learning-based, highly data-driven, visual full-body humanoid control approach without any simplifications assumptions, reward designs, or skill primitives.
The author proposed a hierarchical world model to train two agents, high-level and low-level. The high-level agent generates commands based on visual observations for execution by the low-level agent.

Open source code: https://github.com/nicklashansen/puppeteer
This model is Named Puppeteer, we utilize a simulated 56-DoF humanoid robot to generate high-performance control strategies across eight tasks while synthesizing natural human-like movements and the ability to traverse challenging terrains.

High-dimensional control hierarchical world model
Learning and training general-purpose agents in the physical world has always been AI One of the goals of field research.
Humanoid robots, by integrating full-body control and perception, can perform a variety of tasks and stand out as multi-functional platforms.
But the cost of imitating advanced animals like us is still very high.
For example, in the picture below, in order to avoid stepping into pits, the humanoid robot needs to accurately sense the position and length of the oncoming floor gap, and at the same time carefully coordinate its whole body movements to make it effective. Enough momentum and range to cross every gap.

Puppeteer is a data-driven RL method based on the hierarchical JEPA world model proposed by LeCun in 2022.
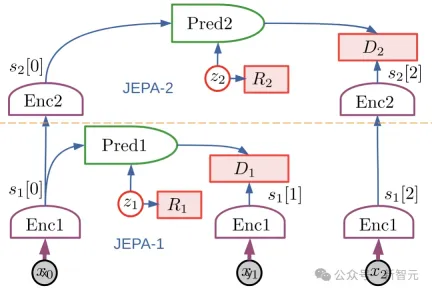
It consists of two different agents: one is responsible for perception and tracking, tracking reference motion through joint-level control; the other "visual puppet" (puppeteer) learns to execute downstream by synthesizing low-dimensional reference motion tasks to provide support for the tracking of the former.
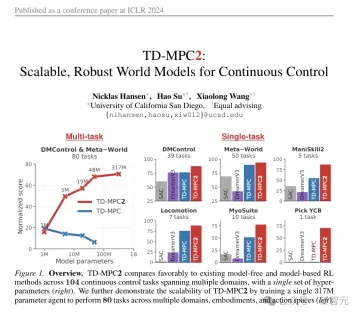
Puppeteer uses the model-based RL algorithm-TD-MPC2 to independently train two agents in two different stages.
(ps: This TD-MPC2 is the animated picture used for comparison at the beginning of the article. Although it seems a bit abstract, it is actually the previous SOTA, published in this year's ICLR, a work Also part of this article)
## In the first stage, the world model for tracking is first pre-trained, using pre-existing human actions. Capture data as a reference to convert motion into physically actionable actions. This agent can be saved and reused in all downstream tasks.
In the second stage, a puppet world model is trained, which takes visual observations as input and integrates reference motion provided by another agent as output according to the specified downstream task.
This framework seems simple: the two world models are algorithmically the same, only different in input/output, and are trained using RL without any other bells and whistles thing.
Unlike traditional hierarchical RL settings, "Puppet" outputs the geometric positions of the end-effector joints rather than the embedding of the target.
This makes the agent responsible for tracking easy to share and generalize between tasks, saving the space occupied by the overall calculation.
Research Method
The researchers modeled visual full-body humanoid control as an reinforcement controlled by a Markov decision process (MDP) Learning problem, the process is characterized by tuples (S, A, T, R, γ, Δ),
where S is the state, A is the action, and T is the environment transition function , R is the scalar reward function, γ is the discount factor, and Δ is the termination condition.
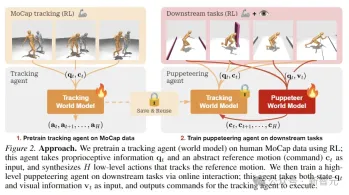
As shown in the figure above, the researchers used RL to pre-train the tracking agent on human MoCap data for obtaining proprioceptive information and abstract reference motion input, and synthesizes low-level actions that track reference motion.
Then through online interaction, the advanced puppet agent responsible for downstream tasks is trained. The puppet accepts status and visual information input and outputs commands for the tracking agent to execute.
TD-MPC2
TD-MPC2 learns a latent decoder-free world model from environment interactions, and use the learned model for planning.
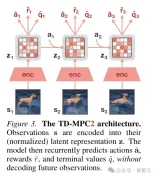
All components of the world model are learned end-to-end using a combination of joint embedding prediction, reward prediction, and temporal difference loss without decoding Original observations.
During inference, TD-MPC2 follows the Model Predictive Control (MPC) framework, using Model Predictive Path Integral (MPPI) as a derivative-free (sampling-based) optimizer for local trajectories optimization.
In order to speed up planning, TD-MPC2 also learns a model-free strategy in advance to pre-start the sampling program.
The two agents are algorithmically identical and both consist of the following 6 components:

Experiment
To evaluate the effectiveness of the method, the researchers proposed a new task suite using a simulated 56-degree-of-freedom humanoid robot for visual full-body control, containing a total of 8 Challenging tasks, methods used for comparison include SAC, DreamerV3 and TD-MPC2.
The 8 tasks are shown in the figure below, including 5 visual-condition whole-body movement tasks, and another 3 tasks without visual input.
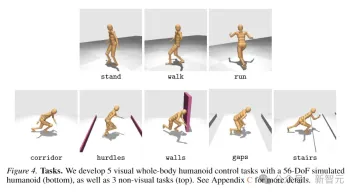
Missions are designed with a high degree of randomness and involve running down corridors, jumping over obstacles and gaps, walking up stairs, and around walls.
The five visual control tasks all use a reward function proportional to linear forward speed, while the non-visual tasks reward displacement in any direction.
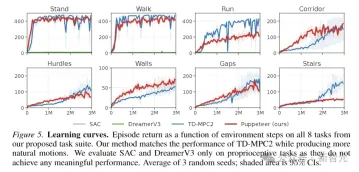
The above figure plots the learning curve. The results show that SAC and DreamerV3 are unable to achieve meaningful performance on these tasks.
TD-MPC2 performs comparably to this article’s method in terms of rewards, but produces unnatural behavior (see abstract actions in the image below).

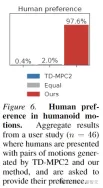
In addition, in order to prove that the actions generated by Puppeteer are indeed more "natural", this article also conducted human preference Experiments with 46 participants showed that humans generally like the motion generated by this method.
The above is the detailed content of LeCun's new work: layered world model, data-driven humanoid robot control. For more information, please follow other related articles on the PHP Chinese website!

 Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AM
Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AMExploring the Inner Workings of Language Models with Gemma Scope Understanding the complexities of AI language models is a significant challenge. Google's release of Gemma Scope, a comprehensive toolkit, offers researchers a powerful way to delve in
 Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AM
Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AMUnlocking Business Success: A Guide to Becoming a Business Intelligence Analyst Imagine transforming raw data into actionable insights that drive organizational growth. This is the power of a Business Intelligence (BI) Analyst – a crucial role in gu
 How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMIntroduction Imagine a bustling office where two professionals collaborate on a critical project. The business analyst focuses on the company's objectives, identifying areas for improvement, and ensuring strategic alignment with market trends. Simu
 What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel data counting and analysis: detailed explanation of COUNT and COUNTA functions Accurate data counting and analysis are critical in Excel, especially when working with large data sets. Excel provides a variety of functions to achieve this, with the COUNT and COUNTA functions being key tools for counting the number of cells under different conditions. Although both functions are used to count cells, their design targets are targeted at different data types. Let's dig into the specific details of COUNT and COUNTA functions, highlight their unique features and differences, and learn how to apply them in data analysis. Overview of key points Understand COUNT and COU
 Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AM
Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AMGoogle Chrome's AI Revolution: A Personalized and Efficient Browsing Experience Artificial Intelligence (AI) is rapidly transforming our daily lives, and Google Chrome is leading the charge in the web browsing arena. This article explores the exciti
 AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AM
AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AMReimagining Impact: The Quadruple Bottom Line For too long, the conversation has been dominated by a narrow view of AI’s impact, primarily focused on the bottom line of profit. However, a more holistic approach recognizes the interconnectedness of bu
 5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AM
5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AMThings are moving steadily towards that point. The investment pouring into quantum service providers and startups shows that industry understands its significance. And a growing number of real-world use cases are emerging to demonstrate its value out


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Dreamweaver Mac version
Visual web development tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

