

 Technology peripheralsAIGraphRAG enhanced for knowledge graph retrieval (implemented based on Neo4j code)
Technology peripheralsAIGraphRAG enhanced for knowledge graph retrieval (implemented based on Neo4j code)
图检索增强生成(Graph RAG)正逐渐流行起来,成为传统向量搜索方法的有力补充。这种方法利用图数据库的结构化特性,将数据以节点和关系的形式组织起来,从而增强检索信息的深度和上下文关联性。图在表示和存储多样化且相互关联的信息方面具有天然优势,能够轻松捕捉不同数据类型间的复杂关系和属性。而向量数据库则处理这类结构化信息时则显得力不从心,它们更专注于处理高维向量表示的非结构化数据。在 RAG 应用中,结合结构化化的图数据和非结构化的文本向量搜索,可以让我们同时享受两者的优势,这也是本文将要探讨的内容。
构建知识图谱通常是利用图数据表示的强大功能中最困难的一步。它需要收集和整理数据,这需要对领域知识和图建模有深刻的理解。为了简化这一过程,可以参考已有的项目或者利用LLM来创建知识图谱,进而可以把重点放在检索召回上,以提高LLM的生成阶段。下面来进行相关代码的实践。
1.知识图谱构建
为了存储知识图谱数据,首先需要搭建一个 Neo4j 实例。最简单的方法是在 Neo4j Aura 上启动一个免费实例,它提供了 Neo4j 数据库的云版本。当然,也可以通过 Docker 本地启动一个,然后将图谱数据导入到 Neo4j 数据库中。
步骤I:Neo4j环境搭建
下面是本地启动docker的运行示例:
docker run -d \--restart always \--publish=7474:7474 --publish=7687:7687 \--env NEO4J_AUTH=neo4j/000000 \--volume=/yourdockerVolume/neo4j:/data \neo4j:5.19.0
步骤II:图谱数据导入
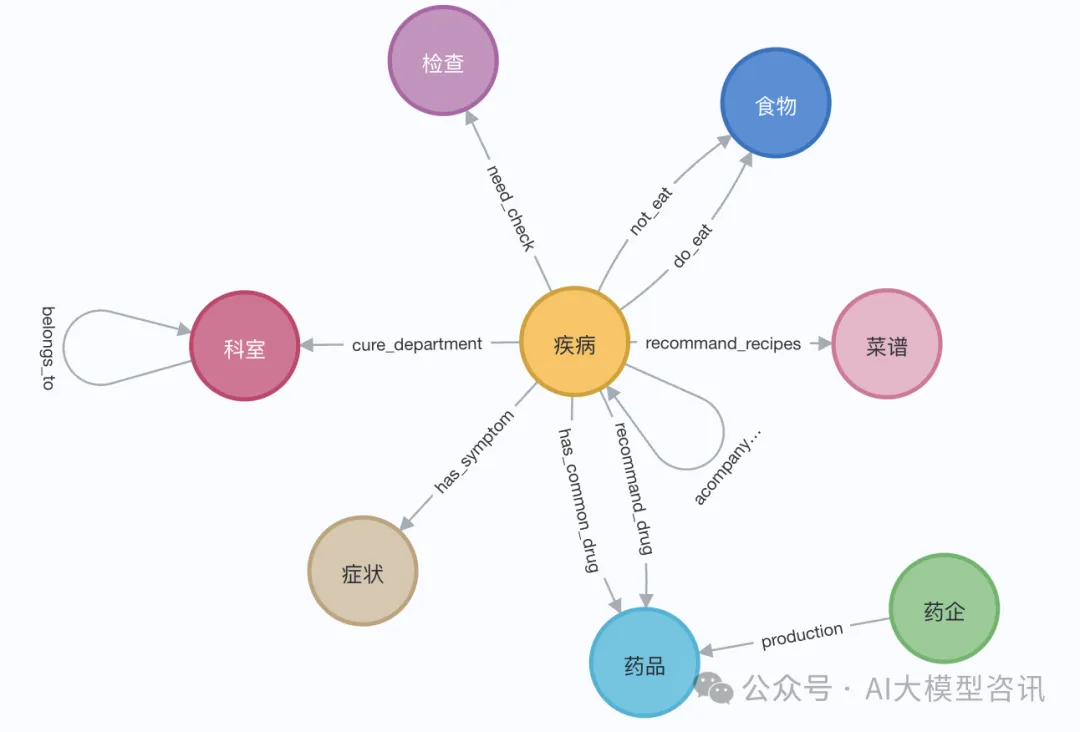
演示中,我们可以使用伊丽莎白一世的维基百科页面。利用 LangChain 加载器从维基百科获取并分割文档,后存入Neo4j数据库。为了试验中文上的效果,我们导入这个Github上的这个项目(QASystemOnMedicalKG)中的医学知识图谱,包含近35000个节点,30万组三元组,大致得到如下结果:
 图片
图片
或者利用LangChainLangChain 加载器从维基百科获取并分割文档,大致如下面步骤所示:
# 读取维基百科文章raw_documents = WikipediaLoader(query="Elizabeth I").load()# 定义分块策略text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24)documents = text_splitter.split_documents(raw_documents[:3])llm=ChatOpenAI(temperature=0, model_name="gpt-4-0125-preview")llm_transformer = LLMGraphTransformer(llm=llm)# 提取图数据graph_documents = llm_transformer.convert_to_graph_documents(documents)# 存储到 neo4jgraph.add_graph_documents(graph_documents, baseEntityLabel=True, include_source=True)
2.知识图谱检索
在对知识图谱检索之前,需要对实体和相关属性进行向量嵌入并存储到Neo4j数据库中:
- 实体信息向量嵌入:将实体名称和实体的描述信息拼接后,利用向量表征模型进行向量嵌入(如下述示例代码中的add_embeddings方法所示)。
- 图谱结构化检索:图谱的结构化检索分为四个步骤:步骤一,从图谱中检索与查询相关的实体;步骤二,从全局索引中检索得到实体的标签;步骤三,根据实体标签在相应的节点中查询邻居节点路径;步骤四,对关系进行筛选,保持多样性(整个检索过程如下述示例代码中的structured_retriever方法所示)。
class GraphRag(object):def __init__(self):"""Any embedding function implementing `langchain.embeddings.base.Embeddings` interface."""self._database = 'neo4j'self.label = 'Med'self._driver = neo4j.GraphDatabase.driver(uri=os.environ["NEO4J_URI"],auth=(os.environ["NEO4J_USERNAME"],os.environ["NEO4J_PASSWORD"]))self.embeddings_zh = HuggingFaceEmbeddings(model_name=os.environ["EMBEDDING_MODEL"])self.vectstore = Neo4jVector(embedding=self.embeddings_zh, username=os.environ["NEO4J_USERNAME"], password=os.environ["NEO4J_PASSWORD"], url=os.environ["NEO4J_URI"], node_label=self.label, index_name="vector" )def query(self, query: str, params: dict = {}) -> List[Dict[str, Any]]:"""Query Neo4j database."""from neo4j.exceptions import CypherSyntaxErrorwith self._driver.session(database=self._database) as session:try:data = session.run(query, params)return [r.data() for r in data]except CypherSyntaxError as e:raise ValueError(f"Generated Cypher Statement is not valid\n{e}")def add_embeddings(self):"""Add embeddings to Neo4j database."""# 查询图中所有节点,并且根据节点的描述和名字生成embedding,添加到该节点上query = """MATCH (n) WHERE not (n:{}) RETURN ID(n) AS id, labels(n) as labels, n""".format(self.label)print("qurey node...")data = self.query(query)ids, texts, embeddings, metas = [], [], [], []for row in tqdm(data,desc="parsing node"):ids.append(row['id'])text = row['n'].get('name','') + row['n'].get('desc','')texts.append(text)metas.append({"label": row['labels'], "context": text})self.embeddings_zh.multi_process = Falseprint("node embeddings...")embeddings = self.embeddings_zh.embed_documents(texts)print("adding node embeddings...")ids_ret = self.vectstore.add_embeddings(ids=ids,texts=texts,embeddings=embeddings,metadatas=metas)return ids_ret# Fulltext index querydef structured_retriever(self, query, limit=3, simlarity=0.9) -> str:"""Collects the neighborhood of entities mentioned in the question"""# step1 从图谱中检索与查询相关的实体。docs_with_score = self.vectstore.similarity_search_with_score(query, k=topk)entities = [item[0].page_content for item in data if item[1] > simlarity] # scoreself.vectstore.query("CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:Med) ON EACH [e.context]")result = ""for entity in entities:qry = entity# step2 从全局索引中查出entity label,query1 =f"""CALL db.index.fulltext.queryNodes('entity', '{qry}') YIELD node, score return node.label as label,node.context as context, node.id as id, score LIMIT {limit}"""data1 = self.vectstore.query(query1)# step3 根据label在相应的节点中查询邻居节点路径for item in data1:node_type = item['label']node_type = item['label'] if type(node_type) == str else node_type[0]node_id = item['id']query2 = f"""match (node:{node_type})-[r]-(neighbor) where ID(node) = {node_id} RETURN type(r) as rel, node.name+' - '+type(r)+' - '+neighbor.name as output limit 50"""data2 = self.vectstore.query(query2)# step4 为了保持多样性,对关系进行筛选rel_dict = defaultdict(list)if len(data2) > 3*limit:for item1 in data2:rel_dict[item1['rel']].append(item1['output'])if rel_dict:rel_dict = {k:random.sample(v, 3) if len(v)>3 else v for k,v in rel_dict.items()}result += "\n".join(['\n'.join(el) for el in rel_dict.values()]) +'\n'else:result += "\n".join([el['output'] for el in data2]) +'\n'return result3.结合LLM生成
最后利用大语言模型(LLM)根据从知识图谱中检索出来的结构化信息,生成最终的回复。下面的代码中我们以通义千问开源的大语言模型为例:
步骤I:加载LLM模型
from langchain import HuggingFacePipelinefrom transformers import pipeline, AutoTokenizer, AutoModelForCausalLMdef custom_model(model_name, branch_name=None, cache_dir=None, temperature=0, top_p=1, max_new_tokens=512, stream=False):tokenizer = AutoTokenizer.from_pretrained(model_name, revision=branch_name, cache_dir=cache_dir)model = AutoModelForCausalLM.from_pretrained(model_name,device_map='auto',torch_dtype=torch.float16,revision=branch_name,cache_dir=cache_dir)pipe = pipeline("text-generation",model = model,tokenizer = tokenizer,torch_dtype = torch.bfloat16,device_map = 'auto',max_new_tokens = max_new_tokens,do_sample = True)llm = HuggingFacePipeline(pipeline = pipe,model_kwargs = {"temperature":temperature, "top_p":top_p,"tokenizer":tokenizer, "model":model})return llmtongyi_model = "Qwen1.5-7B-Chat"llm_model = custom_model(model_name=tongyi_model)tokenizer = llm_model.model_kwargs['tokenizer']model = llm_model.model_kwargs['model']步骤II:输入检索数据生成回复
final_data = self.get_retrieval_data(query)prompt = ("请结合以下信息,简洁和专业的来回答用户的问题,若信息与问题关联紧密,请尽量参考已知信息。\n""已知相关信息:\n{context} 请回答以下问题:{question}".format(cnotallow=final_data, questinotallow=query))messages = [{"role": "system", "content": "你是**开发的智能助手。"},{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(self.device)generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)4 结语
对一个查询问题分别进行了测试, 与没有RAG仅利用LLM生成回复的的情况进行对比,在有GraphRAG 的情况下,LLM模型回答的信息量更大、准确会更高。
The above is the detailed content of GraphRAG enhanced for knowledge graph retrieval (implemented based on Neo4j code). For more information, please follow other related articles on the PHP Chinese website!

 本地使用Groq Llama 3 70B的逐步指南Jun 10, 2024 am 09:16 AM
本地使用Groq Llama 3 70B的逐步指南Jun 10, 2024 am 09:16 AM译者|布加迪审校|重楼本文介绍了如何使用GroqLPU推理引擎在JanAI和VSCode中生成超快速响应。每个人都致力于构建更好的大语言模型(LLM),例如Groq专注于AI的基础设施方面。这些大模型的快速响应是确保这些大模型更快捷地响应的关键。本教程将介绍GroqLPU解析引擎以及如何在笔记本电脑上使用API和JanAI本地访问它。本文还将把它整合到VSCode中,以帮助我们生成代码、重构代码、输入文档并生成测试单元。本文将免费创建我们自己的人工智能编程助手。GroqLPU推理引擎简介Groq
 从“人+RPA”到“人+生成式AI+RPA”,LLM如何影响RPA人机交互?Jun 05, 2023 pm 12:30 PM
从“人+RPA”到“人+生成式AI+RPA”,LLM如何影响RPA人机交互?Jun 05, 2023 pm 12:30 PM图片来源@视觉中国文|王吉伟从“人+RPA”到“人+生成式AI+RPA”,LLM如何影响RPA人机交互?换个角度,从人机交互看LLM如何影响RPA?影响程序开发与流程自动化人机交互的RPA,现在也要被LLM改变了?LLM如何影响人机交互?生成式AI怎么改变RPA人机交互?一文看明白:大模型时代来临,基于LLM的生成式AI正在快速变革RPA人机交互;生成式AI重新定义人机交互,LLM正在影响RPA软件架构变迁。如果问RPA对程序开发以及自动化有哪些贡献,其中一个答案便是它改变了人机交互(HCI,h
 加州理工华人用AI颠覆数学证明!提速5倍震惊陶哲轩,80%数学步骤全自动化Apr 23, 2024 pm 03:01 PM
加州理工华人用AI颠覆数学证明!提速5倍震惊陶哲轩,80%数学步骤全自动化Apr 23, 2024 pm 03:01 PMLeanCopilot,让陶哲轩等众多数学家赞不绝口的这个形式化数学工具,又有超强进化了?就在刚刚,加州理工教授AnimaAnandkumar宣布,团队发布了LeanCopilot论文的扩展版本,并且更新了代码库。图片论文地址:https://arxiv.org/pdf/2404.12534.pdf最新实验表明,这个Copilot工具,可以自动化80%以上的数学证明步骤了!这个纪录,比以前的基线aesop还要好2.3倍。并且,和以前一样,它在MIT许可下是开源的。图片他是一位华人小哥宋沛洋,他是
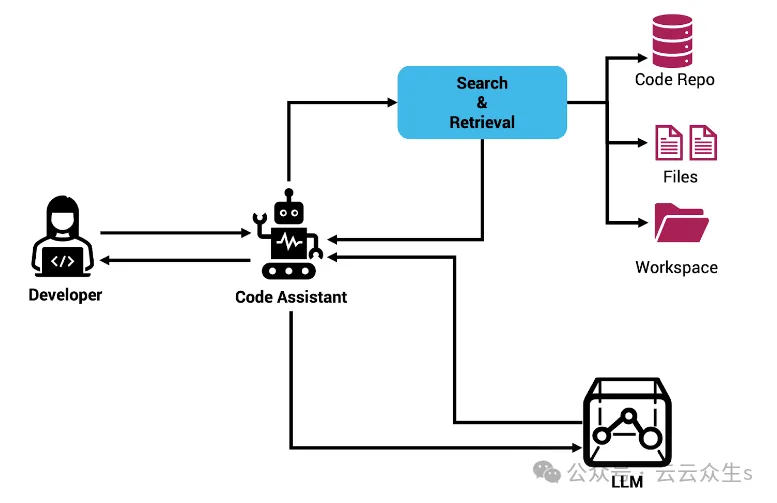 使用Rag和Sem-Rag提供上下文增强AI编码助手Jun 10, 2024 am 11:08 AM
使用Rag和Sem-Rag提供上下文增强AI编码助手Jun 10, 2024 am 11:08 AM通过将检索增强生成和语义记忆纳入AI编码助手,提升开发人员的生产力、效率和准确性。译自EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG,作者JanakiramMSV。虽然基本AI编程助手自然有帮助,但由于依赖对软件语言和编写软件最常见模式的总体理解,因此常常无法提供最相关和正确的代码建议。这些编码助手生成的代码适合解决他们负责解决的问题,但通常不符合各个团队的编码标准、惯例和风格。这通常会导致需要修改或完善其建议,以便将代码接受到应
 Plaud launches NotePin AI wearable recorder for $169Aug 29, 2024 pm 02:37 PM
Plaud launches NotePin AI wearable recorder for $169Aug 29, 2024 pm 02:37 PMPlaud, the company behind the Plaud Note AI Voice Recorder (available on Amazon for $159), has announced a new product. Dubbed the NotePin, the device is described as an AI memory capsule, and like the Humane AI Pin, this is wearable. The NotePin is
 七个很酷的GenAI & LLM技术性面试问题Jun 07, 2024 am 10:06 AM
七个很酷的GenAI & LLM技术性面试问题Jun 07, 2024 am 10:06 AM想了解更多AIGC的内容,请访问:51CTOAI.x社区https://www.51cto.com/aigc/译者|晶颜审校|重楼不同于互联网上随处可见的传统问题库,这些问题需要跳出常规思维。大语言模型(LLM)在数据科学、生成式人工智能(GenAI)和人工智能领域越来越重要。这些复杂的算法提升了人类的技能,并在诸多行业中推动了效率和创新性的提升,成为企业保持竞争力的关键。LLM的应用范围非常广泛,它可以用于自然语言处理、文本生成、语音识别和推荐系统等领域。通过学习大量的数据,LLM能够生成文本
 知识图谱检索增强的GraphRAG(基于Neo4j代码实现)Jun 12, 2024 am 10:32 AM
知识图谱检索增强的GraphRAG(基于Neo4j代码实现)Jun 12, 2024 am 10:32 AM图检索增强生成(GraphRAG)正逐渐流行起来,成为传统向量搜索方法的有力补充。这种方法利用图数据库的结构化特性,将数据以节点和关系的形式组织起来,从而增强检索信息的深度和上下文关联性。图在表示和存储多样化且相互关联的信息方面具有天然优势,能够轻松捕捉不同数据类型间的复杂关系和属性。而向量数据库则处理这类结构化信息时则显得力不从心,它们更专注于处理高维向量表示的非结构化数据。在RAG应用中,结合结构化化的图数据和非结构化的文本向量搜索,可以让我们同时享受两者的优势,这也是本文将要探讨的内容。构
 可视化FAISS矢量空间并调整RAG参数提高结果精度Mar 01, 2024 pm 09:16 PM
可视化FAISS矢量空间并调整RAG参数提高结果精度Mar 01, 2024 pm 09:16 PM随着开源大型语言模型的性能不断提高,编写和分析代码、推荐、文本摘要和问答(QA)对的性能都有了很大的提高。但是当涉及到QA时,LLM通常会在未训练数据的相关的问题上有所欠缺,很多内部文件都保存在公司内部,以确保合规性、商业秘密或隐私。当查询这些文件时,会使得LLM产生幻觉,产生不相关、捏造或不一致的内容。一种处理这一挑战的可行技术是检索增强生成(RAG)。它涉及通过引用训练数据源之外的权威知识库来增强响应的过程,以提升生成的质量和准确性。RAG系统包括一个检索系统,用于从语料库中检索相关文档片段


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

