
 Technology peripheralsAIThe visual representation model vHeat inspired by physical heat transfer is here. It attempts to break through the attention mechanism and has both low complexity and global receptive field.
Technology peripheralsAIThe visual representation model vHeat inspired by physical heat transfer is here. It attempts to break through the attention mechanism and has both low complexity and global receptive field.The visual representation model vHeat inspired by physical heat transfer is here. It attempts to break through the attention mechanism and has both low complexity and global receptive field.


The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
based on heat conduction. Treat image feature blocks as heat sources, and extract image features by predicting thermal conductivity and using physical heat conductionprinciples. Compared with visual models based on the Attention mechanism, vHeat takes into account: computational complexity (1.5th power), global receptive field, and physical interpretability. When using vHeat-base+%E6%A8%A1%E5%9E%8B for high-resolution image input, the put, GPU memory usage, and flops are Swin-base+%E6%A8%A1 respectively. 3 times, 1/4, 3/4 of %E5%9E%8B. It has achieved advanced performance on basic downstream tasks such as image classification, target detection, and semantic/instance segmentation.

- Paper address: https://arxiv.org/pdf/2405.16555
- Code address: https://github.com/MzeroMiko/vHeat
- Paper title: vHeat: Building Vision Models upon Heat Conduction
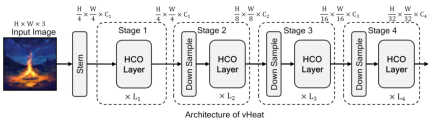
The two most mainstream basic visual models currently are CNN and Visual Transformer (ViT). However, the performance of CNN is limited by local receptive fields and fixed convolution kernel operators. ViT has the ability to represent global dependencies, but at the cost of high quadratic norm computational complexity. We believe that the convolution operators and self-attention operators of CNN and ViT are both pixel transfer processes within features, which are respectively a form of information transfer, which also reminds us of heat conduction in the physical field. So based on the heat conduction equation, we connected the spatial propagation of visual semantics with physical heat conduction, proposed a visual conduction operator (Heat Conduction Operator, HCO) with 1.5 power computational complexity, and then designed a heat conduction operator with low Visual representation model vHeat for complexity, global receptive field, and physical interpretability. The calculation form and complexity comparison between HCO and self-attention are shown in the figure below. Experiments have proven that vHeat performs well in various visual tasks. For example, vHeat-T achieves 82.2% classification accuracy on ImageNet-1K, which is 0.9% higher than Swin-T and 1.7% higher than ViM-S. In addition to performance, vHeat also has the advantages of high inference speed, low GPU memory usage and low FLOPs. When the input image resolution is high, the base-scale vHeat model only has 1/3 more throughput, 1/4 GPU memory usage, and 3/4 FLOPs compared to Swin.
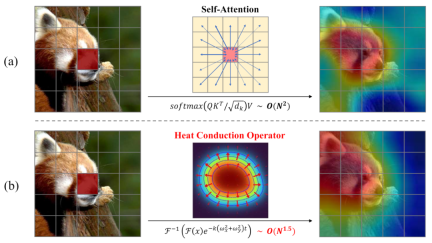
Use
to represent the temperature of point at time t, and the physical heat conduction equation is  , where k>0, represents thermal diffusivity. Given the initial conditions
, where k>0, represents thermal diffusivity. Given the initial conditions at time t=0, the heat conduction equation can be solved by using Fourier transform, which is expressed as follows:
at time t=0, the heat conduction equation can be solved by using Fourier transform, which is expressed as follows: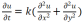

where  and
and  represent Fourier transform and inverse Fourier transform respectively,
represent Fourier transform and inverse Fourier transform respectively,  represents frequency domain spatial coordinates.
represents frequency domain spatial coordinates.
We use HCO to implement heat conduction in visual semantics. First, we extend the  in the physical heat conduction equation to a multi-channel feature
in the physical heat conduction equation to a multi-channel feature  , and treat
, and treat  as input and
as input and  as output. , HCO simulates the general solution of heat conduction in the discretized form, as shown in the following formula:
as output. , HCO simulates the general solution of heat conduction in the discretized form, as shown in the following formula:

where  and
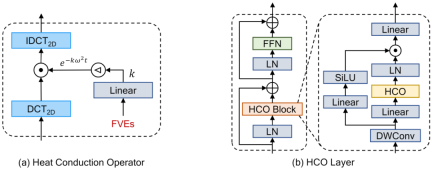
and  represent the two-dimensional discrete cosine transform and the inverse transform respectively, The structure of HCO is shown in Figure (a) below.
represent the two-dimensional discrete cosine transform and the inverse transform respectively, The structure of HCO is shown in Figure (a) below.
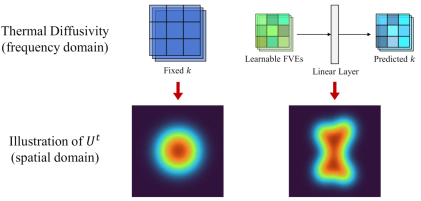
In addition, we believe that different image contents should correspond to different thermal diffusivities. Considering that the output of  is in the frequency domain, we determine the thermal diffusion based on the frequency value Rate,
is in the frequency domain, we determine the thermal diffusion based on the frequency value Rate, . Since different positions in the frequency domain represent different frequency values, we propose Frequency Value Embeddings (FVEs) to represent frequency value information, which is similar to the implementation and function of absolute position encoding in ViT, and use FVEs to control heat diffusion. The rate k is predicted so that HCO can perform non-uniform and adaptive conduction, as shown in the figure below.
. Since different positions in the frequency domain represent different frequency values, we propose Frequency Value Embeddings (FVEs) to represent frequency value information, which is similar to the implementation and function of absolute position encoding in ViT, and use FVEs to control heat diffusion. The rate k is predicted so that HCO can perform non-uniform and adaptive conduction, as shown in the figure below.
vHeat is implemented using a multi-level structure, as shown in the figure below. The overall framework is similar to the mainstream visual model, and the HCO layer is shown in Figure 2 (b).
Experimental results
ImageNet classification
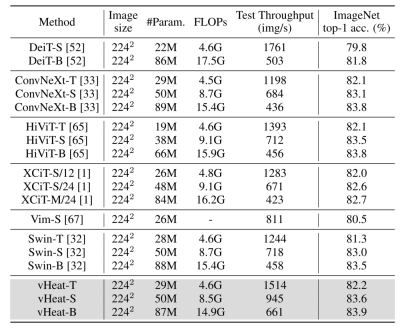
vHeat-T achieved 82.2 The performance of % exceeds DeiT-S by 2.4%, Vim-S by 1.7%, and Swin-T by 0.9%. vHeat-S achieved 83.6% performance, exceeding Swin-S by 0.6% and ConvNeXt-S by 0.5%. vHeat-B achieved 83.9% performance, exceeding DeiT-B by 2.1% and Swin-B by 0.4%.
Downstream tasks

On the COCO data set, vHeat also has a performance advantage: in the case of fine-tune 12 epochs , vHeat-T/S/B reaches 45.1/46.8/47.7 mAP respectively, exceeding Swin-T/S/B by 2.4/2.0/0.8 mAP, and exceeding ConvNeXt-T/S/B by 0.9/1.4/0.7 mAP. On the ADE20K data set, vHeat-T/S/B reached 46.9/49.0/49.6 mIoU respectively, which still has better performance than Swin and ConvNeXt. These results verify that vHeat fully works in visual downstream experiments, demonstrating the potential to replace mainstream basic visual models.
Analysis Experiment
Effective Feeling Field
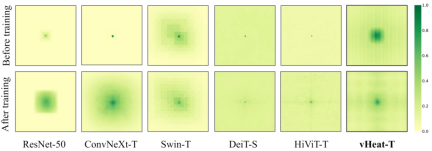

The above is the detailed content of The visual representation model vHeat inspired by physical heat transfer is here. It attempts to break through the attention mechanism and has both low complexity and global receptive field.. For more information, please follow other related articles on the PHP Chinese website!

 Personal Hacking Will Be A Pretty Fierce BearMay 11, 2025 am 11:09 AM
Personal Hacking Will Be A Pretty Fierce BearMay 11, 2025 am 11:09 AMCyberattacks are evolving. Gone are the days of generic phishing emails. The future of cybercrime is hyper-personalized, leveraging readily available online data and AI to craft highly targeted attacks. Imagine a scammer who knows your job, your f
 Pope Leo XIV Reveals How AI Influenced His Name ChoiceMay 11, 2025 am 11:07 AM
Pope Leo XIV Reveals How AI Influenced His Name ChoiceMay 11, 2025 am 11:07 AMIn his inaugural address to the College of Cardinals, Chicago-born Robert Francis Prevost, the newly elected Pope Leo XIV, discussed the influence of his namesake, Pope Leo XIII, whose papacy (1878-1903) coincided with the dawn of the automobile and
 3 Ways AI Can Make Mentorship More Meaningful Than EverMay 10, 2025 am 11:17 AM
3 Ways AI Can Make Mentorship More Meaningful Than EverMay 10, 2025 am 11:17 AMI wholeheartedly agree. My success is inextricably linked to the guidance of my mentors. Their insights, particularly regarding business management, formed the bedrock of my beliefs and practices. This experience underscores my commitment to mentor
 AI Unearths New Potential In The Mining IndustryMay 10, 2025 am 11:16 AM
AI Unearths New Potential In The Mining IndustryMay 10, 2025 am 11:16 AMAI Enhanced Mining Equipment The mining operation environment is harsh and dangerous. Artificial intelligence systems help improve overall efficiency and security by removing humans from the most dangerous environments and enhancing human capabilities. Artificial intelligence is increasingly used to power autonomous trucks, drills and loaders used in mining operations. These AI-powered vehicles can operate accurately in hazardous environments, thereby increasing safety and productivity. Some companies have developed autonomous mining vehicles for large-scale mining operations. Equipment operating in challenging environments requires ongoing maintenance. However, maintenance can keep critical devices offline and consume resources. More precise maintenance means increased uptime for expensive and necessary equipment and significant cost savings. AI-driven
 Why AI Agents Will Trigger The Biggest Workplace Revolution In 25 YearsMay 10, 2025 am 11:15 AM
Why AI Agents Will Trigger The Biggest Workplace Revolution In 25 YearsMay 10, 2025 am 11:15 AMMarc Benioff, Salesforce CEO, predicts a monumental workplace revolution driven by AI agents, a transformation already underway within Salesforce and its client base. He envisions a shift from traditional markets to a vastly larger market focused on
 AI HR Is Going To Rock Our Worlds As AI Adoption SoarsMay 10, 2025 am 11:14 AM
AI HR Is Going To Rock Our Worlds As AI Adoption SoarsMay 10, 2025 am 11:14 AMThe Rise of AI in HR: Navigating a Workforce with Robot Colleagues The integration of AI into human resources (HR) is no longer a futuristic concept; it's rapidly becoming the new reality. This shift impacts both HR professionals and employees, dem
 5 ChatGPT Prompts To Break Through Revenue PlateausMay 10, 2025 am 11:13 AM
5 ChatGPT Prompts To Break Through Revenue PlateausMay 10, 2025 am 11:13 AMYour revenue breakthrough is right in front of you. Break the ceiling and take your business to a whole new level. This is possible. Copy, paste, and modify the square bracket content in ChatGPT and keep the same chat window open so the context can continue. Break down revenue barriers with ChatGPT: Unleash your growth potential 10 times the growth mindset Your goals are boring. The business vision that once excites you now feels painfully safe. You reach your goal, but you feel empty. Success is not based on luck. They set bold goals that are both frightening and exciting. They see business as a game, and so can you. Pursuing higher bets. The dream is bigger. The plan is bigger. Execute more. Watch your results
 Romance Stories Reaching New Heartfelt Heights Via Generative AIMay 10, 2025 am 11:12 AM
Romance Stories Reaching New Heartfelt Heights Via Generative AIMay 10, 2025 am 11:12 AMLet's explore the exciting intersection of romance and generative AI. This analysis is part of my ongoing Forbes column on AI's latest advancements, focusing on impactful AI complexities (see link here). Redefining Romance: A Modern Perspective We've


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Notepad++7.3.1
Easy-to-use and free code editor

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

