
 Technology peripheralsAIYann LeCun: ViT is slow and inefficient. Real-time image processing still depends on convolution.
Technology peripheralsAIYann LeCun: ViT is slow and inefficient. Real-time image processing still depends on convolution.
In the era of Transformer unification, is it still necessary to study the CNN direction of computer vision?
At the beginning of this year, OpenAI’s large video model Sora made the Vision Transformer (ViT) architecture popular. Since then, there has been an ongoing debate about who is more powerful, ViT or traditional convolutional neural networks (CNN).
Recently, Yann LeCun, Turing Award winner and Meta chief scientist who has been active on social media, has also joined the discussion on the dispute between ViT and CNN.

The cause of this incident was that Harald Schäfer, CTO of Comma.ai, was showing off his latest research. He (like many recent AI scholars) cue Yann LeCun's expression that although the Turing Award tycoon believes that pure ViT is not practical, we have recently changed our compressor to pure ViT. There is no quick gain and it will take longer. training, but the effect is very good.
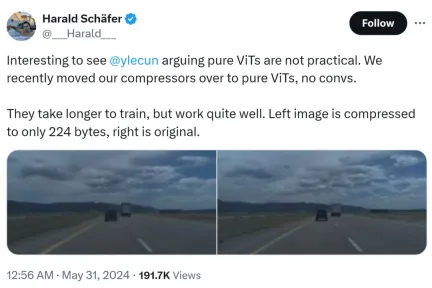
For example, the image on the left is compressed to only 224 bytes, and the right is the original image.
Only 14×128, which is very large for the world model used for autonomous driving, which means that a large amount of data can be input for training. Training in a virtual environment is less expensive than in a real environment, where agents need to be trained according to policies to work properly. Higher resolutions for virtual training will work better, but the simulator will become very slow, so compression is necessary for now.
His demonstration sparked discussion in the AI circle, and Eric Jang, vice president of artificial intelligence at 1X, replied that the results were amazing.
Harald continued to praise ViT: It is a very beautiful architecture.
Someone started to get angry here: Masters like LeCun sometimes fail to keep up with the pace of innovation.

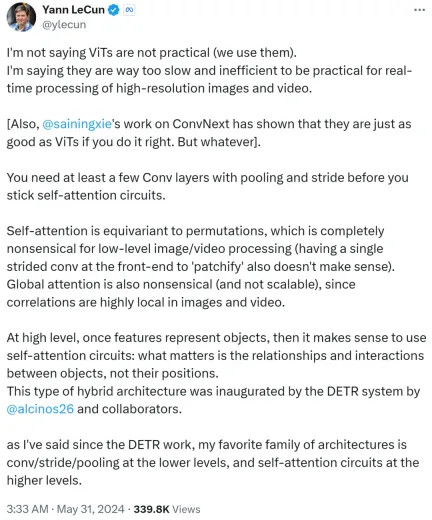
However, Yann LeCun quickly replied and argued that he was not saying that ViT is not practical, and everyone is using it now it. What he wants to express is that ViT is too slow and inefficient, making it unsuitable for real-time processing of high-resolution image and video tasks.
Yann LeCun also Cue Xie Saining, an assistant professor at New York University, whose work ConvNext proved that CNN can be as good as ViT if the method is right.
He goes on to say that you need at least a few convolutional layers with pooling and strides before sticking to a self-attention loop.
If self-attention is equivalent to permutation, it makes no sense at all for low-level image or video processing, nor does using a single stride for patchify on the front end. In addition, since the correlation in images or videos is highly concentrated locally, global attention is meaningless and unscalable.
At a higher level, once features represent objects, then using a self-attention loop makes sense: it is the relationships and interactions between objects that matter, not their Location. This hybrid architecture was pioneered by the DETR system completed by Meta research scientist Nicolas Carion and co-authors.
Since the emergence of DETR work, Yann LeCun said that his favorite architecture is low-level convolution/stride/pooling, and high-level self-attention loop.
Yann LeCun summed it up in the second post: use convolution with stride or pooling at low level, and at high level Use a self-attention loop and use feature vectors to represent objects.
He also bets that Tesla Fully Self-Driving (FSD) uses convolutions (or more complex local operators) at low levels and combines more at higher levels Global loop (possibly using self-attention). Therefore, using Transformers on low-level patch embeddings is a complete waste.

I guess that the archenemy Musk still uses the convolution route.
Xie Saining also expressed his opinion. He believes that ViT is very suitable for low-resolution images of 224x224, but what should we do if the image resolution reaches 1 million x 1 million? At this time, either convolution is used, or ViT is patched and processed using shared weights, which is still convolution in nature.
Therefore, Xie Saining said that there was a moment when he realized that the convolutional network was not an architecture, but a way of thinking.

This view is recognized by Yann LeCun.

Google DeepMind researcher Lucas Beyer also said that thanks to the zero padding of conventional convolutional networks, he is very sure "Convolution ViT" (instead of ViT + convolution) will work well.

##It is foreseeable that this debate between ViT and CNN will continue until another update is made in the future. The emergence of powerful architecture.
The above is the detailed content of Yann LeCun: ViT is slow and inefficient. Real-time image processing still depends on convolution.. For more information, please follow other related articles on the PHP Chinese website!

 ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AM
ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AMai合并图层的快捷键是“Ctrl+Shift+E”,它的作用是把目前所有处在显示状态的图层合并,在隐藏状态的图层则不作变动。也可以选中要合并的图层,在菜单栏中依次点击“窗口”-“路径查找器”,点击“合并”按钮。
 ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AM
ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AMai橡皮擦擦不掉东西是因为AI是矢量图软件,用橡皮擦不能擦位图的,其解决办法就是用蒙板工具以及钢笔勾好路径再建立蒙板即可实现擦掉东西。
 谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM
谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM虽然谷歌早在2020年,就在自家的数据中心上部署了当时最强的AI芯片——TPU v4。但直到今年的4月4日,谷歌才首次公布了这台AI超算的技术细节。论文地址:https://arxiv.org/abs/2304.01433相比于TPU v3,TPU v4的性能要高出2.1倍,而在整合4096个芯片之后,超算的性能更是提升了10倍。另外,谷歌还声称,自家芯片要比英伟达A100更快、更节能。与A100对打,速度快1.7倍论文中,谷歌表示,对于规模相当的系统,TPU v4可以提供比英伟达A100强1.
 ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PM
ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PMai可以转成psd格式。转换方法:1、打开Adobe Illustrator软件,依次点击顶部菜单栏的“文件”-“打开”,选择所需的ai文件;2、点击右侧功能面板中的“图层”,点击三杠图标,在弹出的选项中选择“释放到图层(顺序)”;3、依次点击顶部菜单栏的“文件”-“导出”-“导出为”;4、在弹出的“导出”对话框中,将“保存类型”设置为“PSD格式”,点击“导出”即可;
 ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PM
ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PMai顶部属性栏不见了的解决办法:1、开启Ai新建画布,进入绘图页面;2、在Ai顶部菜单栏中点击“窗口”;3、在系统弹出的窗口菜单页面中点击“控制”,然后开启“控制”窗口即可显示出属性栏。
 GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AM
GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AMYann LeCun 这个观点的确有些大胆。 「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」最近,图灵奖得主 Yann LeCun 给一场辩论做了个特别的开场。而他口中的自回归,正是当前爆红的 GPT 家族模型所依赖的学习范式。当然,被 Yann LeCun 指出问题的不只是自回归模型。在他看来,当前整个的机器学习领域都面临巨大挑战。这场辩论的主题为「Do large language models need sensory grounding for meaning and u
 强化学习再登Nature封面,自动驾驶安全验证新范式大幅减少测试里程Mar 31, 2023 pm 10:38 PM
强化学习再登Nature封面,自动驾驶安全验证新范式大幅减少测试里程Mar 31, 2023 pm 10:38 PM引入密集强化学习,用 AI 验证 AI。 自动驾驶汽车 (AV) 技术的快速发展,使得我们正处于交通革命的风口浪尖,其规模是自一个世纪前汽车问世以来从未见过的。自动驾驶技术具有显着提高交通安全性、机动性和可持续性的潜力,因此引起了工业界、政府机构、专业组织和学术机构的共同关注。过去 20 年里,自动驾驶汽车的发展取得了长足的进步,尤其是随着深度学习的出现更是如此。到 2015 年,开始有公司宣布他们将在 2020 之前量产 AV。不过到目前为止,并且没有 level 4 级别的 AV 可以在市场
 ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AM
ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AMai移动不了东西的解决办法:1、打开ai软件,打开空白文档;2、选择矩形工具,在文档中绘制矩形;3、点击选择工具,移动文档中的矩形;4、点击图层按钮,弹出图层面板对话框,解锁图层;5、点击选择工具,移动矩形即可。


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Atom editor mac version download
The most popular open source editor

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

