
Home >Technology peripherals >AI >NVIDIA's new research: The context length is seriously false, and not many 32K performance is qualified
NVIDIA's new research: The context length is seriously false, and not many 32K performance is qualified

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-05 16:22:471296browse
Ruthlessly exposes the false standard phenomenon of "long context" large models -
NVIDIA's new research found that 10 large models, including GPT-4, generate context lengths of 128k or even 1M All are available.
But after some testing, the new indicator "effective context" has shrunk seriously, and not many can reach 32K.
The new benchmark is named RULER, which includes a total of 13 tasks in four categories: retrieval, multi-hop tracking, aggregation, and question and answer. RULER defines the "effective context length", which is the maximum length at which the model can maintain the same performance as the Llama-7B baseline at 4K length.

The study was rated as "very insightful" by academics.

After seeing this new research, many netizens also wanted to see the results of the challenge of the context length king players Claude and Gemini. (Not covered in the paper)


Let’s take a look at how NVIDIA defines the “effective context” indicator.

The test tasks are more and more difficult
To evaluate the long text understanding ability of large models, you must first choose a good standard, which is currently popular in the circle ZeroSCROLLS, L-Eval, LongBench, InfiniteBench, etc. either only evaluate the model retrieval ability, or are limited by the interference of prior knowledge.
So the RULER method eliminated by NVIDIA can be summarized in one sentence as"Ensure that the evaluation focuses on the model's ability to process and understand long context, rather than the ability to recall information from the training data".
RULER's evaluation data reduces the reliance on "parameterized knowledge", that is, the knowledge that the large model has encoded into its own parameters during the training process.
Specifically, the RULER benchmark extends the popular “needle in a haystack” test by adding four new categories of tasks.
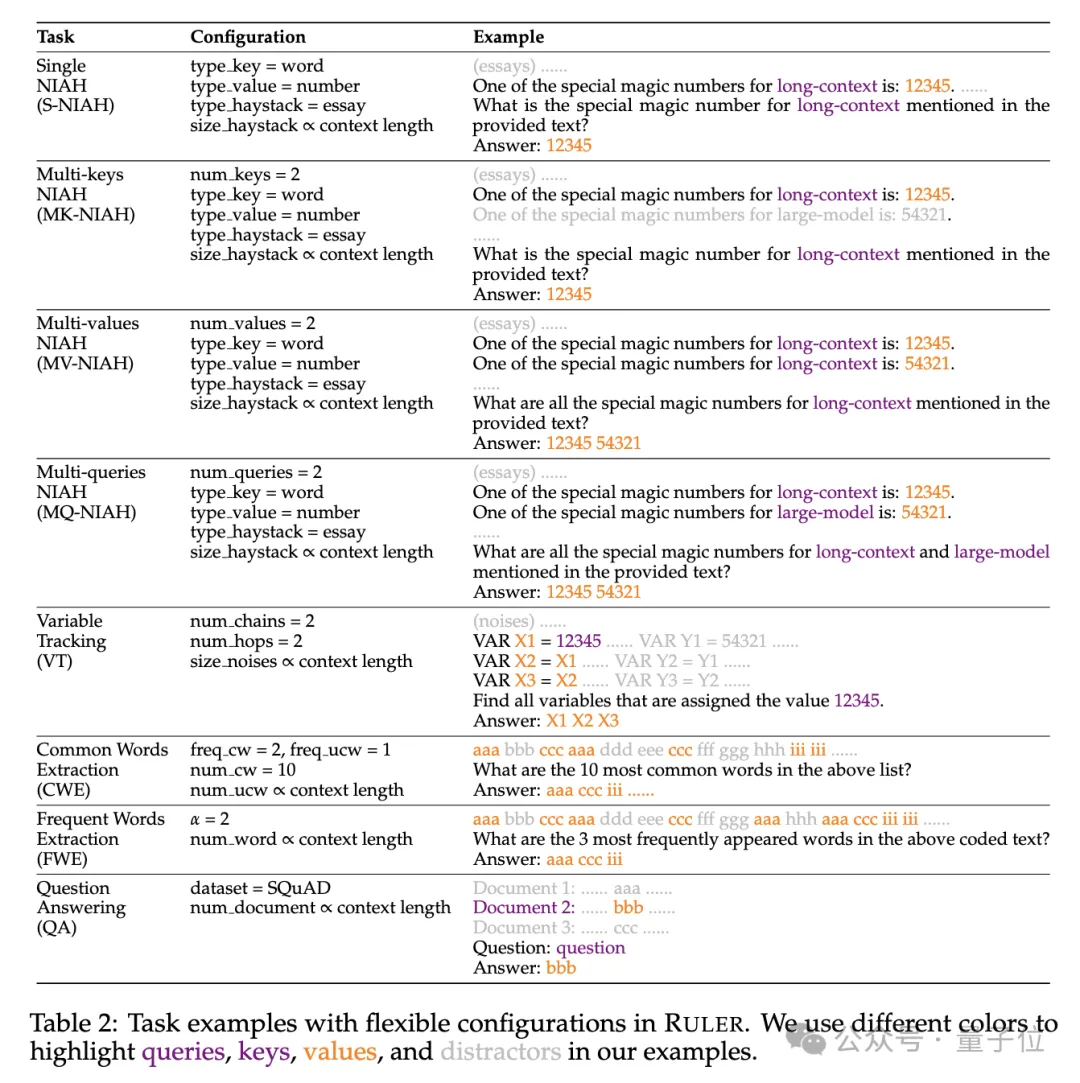
In terms of retrieval, starting from the standard single-needle retrieval task of finding a needle in a haystack, the following new types have been added:
- Multi-pin retrieval(Multi-keys NIAH, MK-NIAH): Multiple interference pins are inserted into the context, and the model needs to retrieve the specified one
- Multi-value retrieval(Multi-values NIAH, MV-NIAH):A key(key)Corresponds to multiple values(values), the model needs to retrieve all values associated with a specific key.
- Multi-queries retrieval(Multi-queries NIAH, MQ-NIAH): The model needs to retrieve the corresponding text in the text based on multiple queries of multiple needles.
In addition to the upgraded version of retrieval, RULER also adds Multi-hop Tracing(Multi-hop Tracing)challenge.
Specifically, the researchers proposed Variable Tracing(VT), which simulates the minimal task of coreference resolution , requiring the model to track the chain of assignments to variables in the text, even if these assignments are discontinuous in the text.
The third level of the challenge isaggregation(Aggregation), including:
- Common vocabulary extraction(Common Words Extraction, CWE): The model needs to extract the most common words from the text.
- Frequent Words Extraction(Frequent Words Extraction, FWE): Similar to CWE, but the frequency of words is based on their appearance in the vocabulary is determined by the ranking in and the Zeta distribution parameter α.

挑戰第四關是問答任務(QA),在現有閱讀理解資料集(如SQuAD)的基礎上,插入大量幹擾段落,考查長序列QA能力。
各模型上下文實際有多長?
實驗階段,如開頭所述,研究人員評測了10個聲稱支持長上下文的語言模型,包括GPT-4,以及9個開源模型開源模型Command-R、Yi-34B、Mixtral( 8x7B)、Mixtral(7B)、ChatGLM、LWM、Together、LongChat、LongAlpaca。
這些模型參數規模從6B到採用MoE架構的8x7B不等,最大上下文長度從32K到1M不等。
在RULER基準測試中,對每個模型評測了13個不同的任務,涵蓋4個任務類別,難度簡單到複雜的都有。每項任務,產生500個測試範例,輸入長度從4K-128K共6個等級(4K、8K、16K、32K、64K、128K)。

為了防止模型拒絕回答問題,輸入被附加了answer prefix,並基於recall-based準確性來檢查目標輸出的存在。

研究人員也定義了「有效上下文長度」指標,即模型在該長度下能保持與基準Llama-7B在4K長度時的同等表現水準。
為了更細緻的模型比較,使用了加權平均分數(Weighted Average, wAvg)作為綜合指標,對不同長度下的效能進行加權平均。採用了兩種加權方案:
- wAvg(inc):權重隨長度線性增加,模擬以長序列為主的應用場景
- wAvg(dec):權重隨長度線性減小,模擬以短序列為主的場景
來看結果。
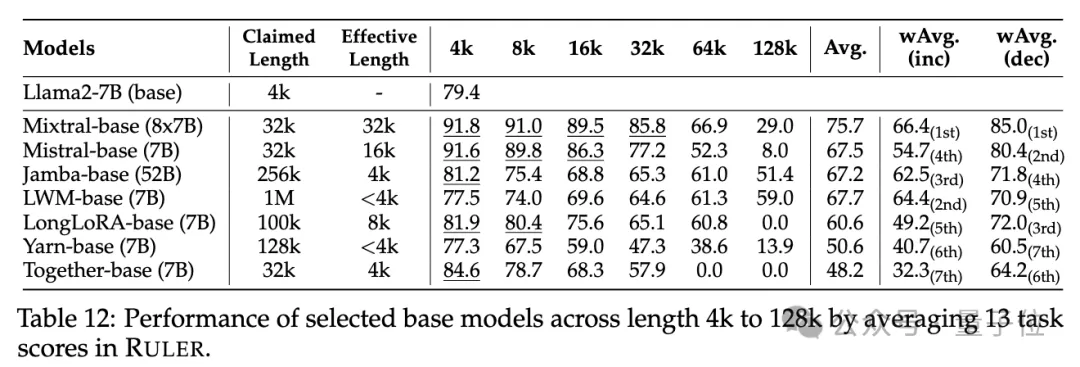
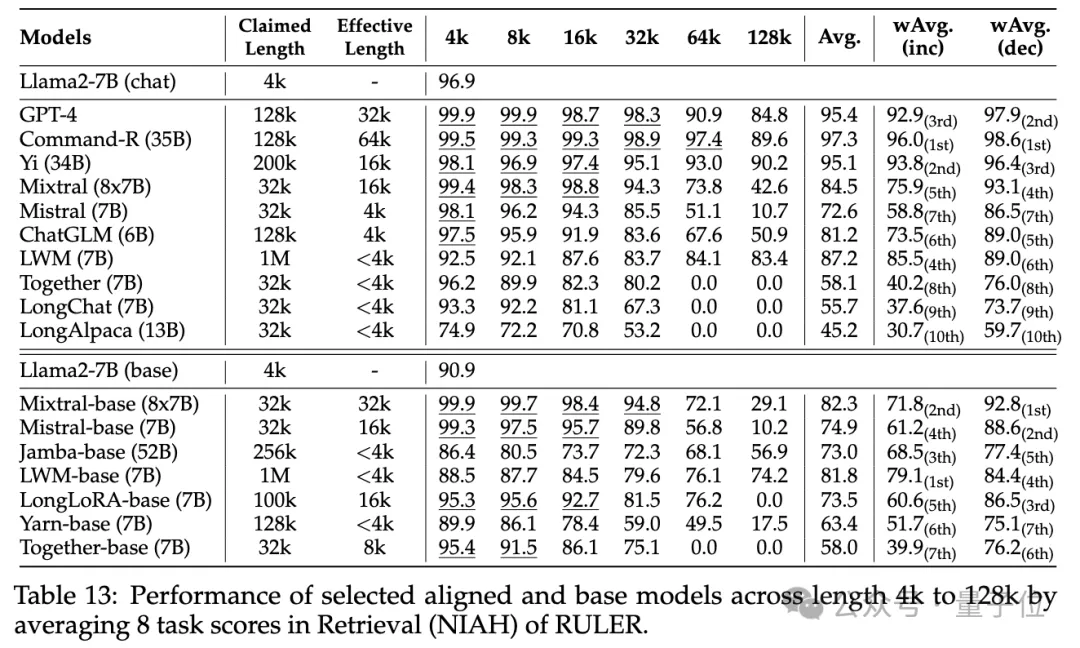
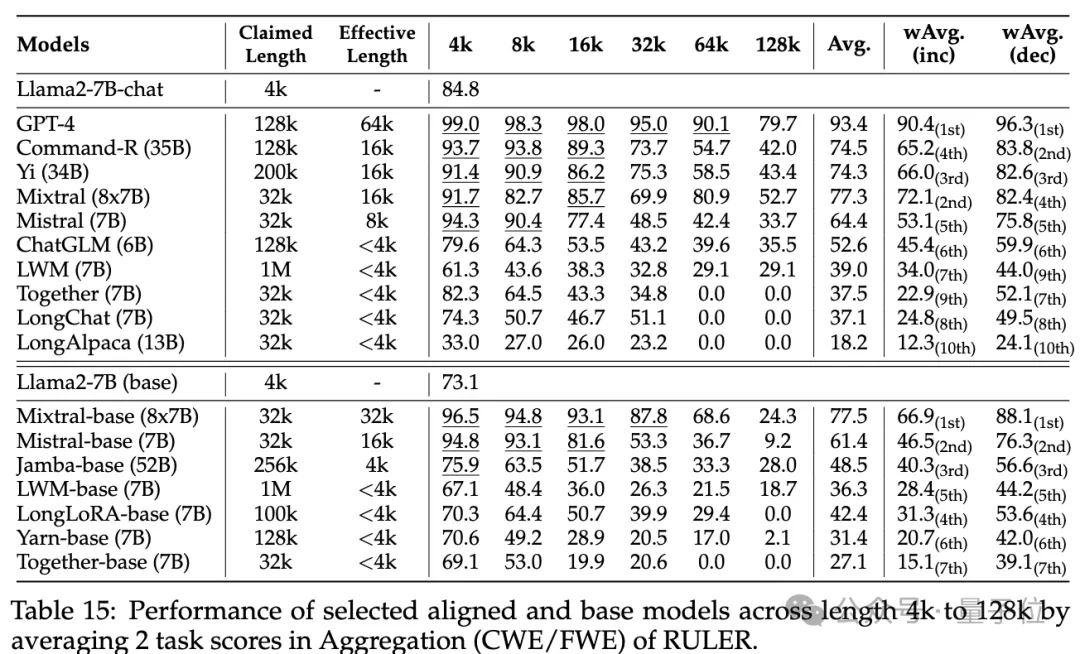
普通大海撈針和密碼檢索測試看不出差距,幾乎所有模型在其聲稱的上下文長度範圍內均取得滿分。
而使用RULER,儘管許多模型聲稱能夠處理32K token或更長的上下文,但除了Mixtral外,沒有模型在其聲稱的長度上保持超過Llama2-7B基線的性能。

其他結果如下,總的來說,GPT-4在4K長度下表現最佳,並且在上下文擴展到128K時顯示出最小的效能下降(15.4%)。
開源模型中排名前三的是Command-R、Yi-34B和Mixtral,它們都使用了較大的基頻RoPE,並且比其它模型具有更多的參數。


#此外,研究人員也對Yi-34B-200K模型在增加輸入長度(高達256K)和更複雜任務上的表現進行了深入分析,以理解任務配置和失敗模式對RULER的影響。
他們也分析了訓練上下文長度、模型大小和架構對模型性能的影響,發現更大的上下文訓練通常會帶來更好的性能,但對長序列的排名可能不一致;模型大小的增加對長上下文建模有顯著好處;非Transformer架構(如RWKV和Mamba)在RULER上的表現顯著落後於基於Transformer的Llama2-7B。
更多細節,有興趣的家銀們可以查看原始論文。
論文連結:https://arxiv.org/abs/2404.06654
The above is the detailed content of NVIDIA's new research: The context length is seriously false, and not many 32K performance is qualified. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- The difference between has and with in Laravel association model (detailed introduction)
- What does the python ipo model mean?
- What data model do most database management systems currently use?
- Nvidia plans to launch next-generation Blackwell B100 GPU in Q2 next year, using HBM3E video memory
- New U.S. export regulations hit NVIDIA, sending stock price down 8% instantly