

 Technology peripheralsAIFocus on it! ! Analysis of two major algorithm frameworks for causal inference
Technology peripheralsAIFocus on it! ! Analysis of two major algorithm frameworks for causal inference
1. Overall Framework

##The main tasks can be divided into three categories. The first is the discovery of causal structures, that is, identifying causal relationships between variables from the data. The second is the estimation of causal effects, that is, inferring from the data the degree of influence of one variable on another variable. It should be noted that this impact does not refer to relative nature, but to how the value or distribution of another variable changes when one variable is intervened. The last step is to correct for bias, because in many tasks, various factors may cause the distribution of development samples and application samples to be different. In this case, causal inference may help us correct for bias.
These functions are suitable for a variety of scenarios, the most typical of which is decision-making scenarios. Through causal inference, we can understand how different users react to our decision-making behavior. Secondly, in industrial scenarios, business processes are often complex and long, leading to data bias. Clearly describing the cause-and-effect relationships of these deviations through causal inference can help us correct them. In addition, many scenarios have high requirements on model robustness and interpretability. It is hoped that the model can make predictions based on causal relationships, and causal inference can help build more powerful explanatory models. Finally, the evaluation of the effects of decision-making outcomes is also important. Causal inference can help better analyze the actual effects of strategies.
Next, we will introduce two important issues in causal inference: how to judge whether a scene is suitable for applying causal inference, and typical algorithms in causal inference. First, it is critical to determine whether a scenario is suitable for applying causal inference. Causal inference is usually used to solve the problem of causality, that is, to infer the relationship between cause and effect through observed data. Therefore, when judging a
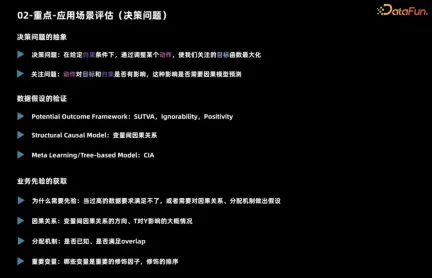
##First introduce the application scenario assessment. Judging whether a scenario is suitable for using inference mainly involves decision-making issues.
Regarding a decision-making problem, we first need to clarify what it is, that is, what actions should be taken under what constraints to achieve the maximum goal. Then you need to consider whether this action has an impact on the goals and constraints, and whether you need to use a causal inference model for prediction. For example, when marketing a product, we usually consider whether to issue coupons or discounts to each user given the total budget. Consider maximizing sales as the overall goal. If there is no budget constraint, it may affect the final sales, but as long as you know that it is a forward strategy, you can give discounts to all users. In this case, although the decision action has an impact on the target, there is no need to use a causal inference model for prediction.
The above is the basic analysis of the decision-making problem. In addition, it is necessary to observe whether the data items are satisfied. For building causal models, different causal algorithms have different requirements for data and task assumptions.
- The model of potential outcome classes has three key assumptions. First of all, the individual causal effect must be stable. For example, when exploring the impact of issuing coupons on users’ purchase probability, it is necessary to ensure that a user’s behavior is not affected by other users, such as offline price comparison or being affected by coupons with different discounts. Influence. The second assumption is that the user's actual processing and potential outcomes are independent given the characteristic situation, which can be used to deal with unobserved confounding. The third hypothesis is about overlap, that is, any kind of user should make different decisions, otherwise the performance of this kind of user under different decisions cannot be observed.
- The main assumption faced by structural causal models is the causal relationship between variables, and these assumptions are often difficult to prove. When using Meta learning and tree-based methods, the assumption is usually conditional independence, that is, given features, decision actions and potential outcomes are independent. This assumption is similar to the independence assumption mentioned earlier.
#In actual business scenarios, understanding prior knowledge is crucial. First, one needs to understand the distribution mechanism of actual observational data, which is the basis for previous decisions. When the most accurate data are not available, it may be necessary to rely on assumptions to make inferences. Second, business experience can guide us in determining which variables have a significant impact on distinguishing causal effects, which is critical for feature engineering. Therefore, when dealing with actual business, combined with the distribution mechanism of observation data and business experience, we can better cope with challenges and effectively carry out decision-making and feature engineering.
3. Typical causal algorithm

The second important issue is the selection of causal inference algorithms.
The first is the causal structure discovery algorithm. The core goal of these algorithms is to determine causal relationships between variables. The main research ideas can be divided into three categories. The first type of method is to judge based on the conditional independence characteristics of the node network in the causal graph. Another approach is to define a scoring function to measure the quality of the causal diagram. For example, by defining a likelihood function, a directed acyclic graph that maximizes the function is sought and used as a causal graph. The third type of method introduces more information. For example, assume that the actual data generation process for two variables follows a n m type, an additive noise model, and then solve for the direction of causality between the two variables.
The estimation of causal effects involves a variety of algorithms. Here are some common algorithms:
- The first is the instrumental variable method, did method and synthetic control method that are often mentioned in econometrics. The core idea of the instrumental variable method is to find variables that are related to the treatment but not related to the random error term, that is, instrumental variables. At this time, the relationship between the instrumental variable and the dependent variable is not affected by confounding. The prediction can be divided into two stages: first, use the instrumental variable to predict the treatment variable, and then use the predicted treatment variable to predict the dependent variable. The obtained regression coefficient is: is the average treatment effect (ATE). The DID method and synthetic control law are methods designed for panel data, but will not be introduced in detail here.
- #Another common approach is to use propensity scores to estimate causal effects. The core of this method is to predict the hidden allocation mechanism, such as the probability of issuing a coupon versus not issuing a coupon. If two users have the same coupon issuance probability, but one user actually received the coupon and the other did not, then we can consider the two users to be equivalent in terms of the distribution mechanism, and therefore their effects can be compared . Based on this, a series of methods can be generalized, including matching methods, hierarchical methods, and weighting methods.
- #Another method is to predict the result directly. Even in the presence of unobserved confounding, the results can be directly predicted through assumptions and automatically adjusted through the model. However, this approach may raise a question: If directly predicting the outcome is enough, then does the problem disappear? Actually, not so.
- The fourth is the idea of combining propensity scores and potential outcomes, using dual robust and dual machine learning methods may be more accurate. Dual robustness and dual machine learning provide double assurance by combining two methods, where the accuracy of either part ensures the reliability of the final result.
- #Another method is a structural causal model, which builds a model based on causal relationships, such as a cause-and-effect diagram or a structured equation. This approach allows direct intervention of a variable to obtain an outcome, as well as counterfactual inference. However, this approach assumes that we already know the causal relationships between variables, which is often a luxurious assumption.
- Meta learning method is an important learning method that covers many different categories. One of them is S-learning, which treats the processing method as a feature and feeds it directly into the model. By adjusting this feature, we can observe changes in results under different processing methods. This approach is sometimes called a single-model learner because we build a model for each of the experimental and control groups and then modify the features to observe the results. Another method is X-learning, whose process is similar to S-learning, but additionally considers the step of cross-validation to more accurately evaluate the performance of the model.
- The tree method is an intuitive and simple method that splits the sample by building a tree structure to maximize the difference in causal effects on the left and right nodes. However, this method is prone to overfitting, so in practice methods such as random forests are often used to reduce the risk of overfitting. Using boosting methods may increase challenges because it is easier to filter out some information, so more complex models need to be designed to prevent information loss when used. Meta learning methods and tree-based algorithms are also often called Uplift models.
- #Causal representation is one of the fields that has achieved certain results in academia in recent years. This method strives to decouple different modules and separate influencing factors to more accurately identify confounding factors. By analyzing the factors that affect the dependent variable y and the treatment variable (treatment), we can identify confounding factors that may affect y and treatment. These factors are called confounding factors. This method is expected to improve the end-to-end learning effect of the model. Take the propensity score, for example, which often does an excellent job of dealing with confounding factors. However, excessive accuracy of propensity scores is sometimes unfavorable. Under the same propensity score, there may be situations where the overlapping assumption cannot be met. This is because the propensity score may contain some information that is related to the confounding factors but does not affect y. When the model learns too accurately, it may lead to larger errors during weighted matching or hierarchical processing. These errors are not actually caused by confounding factors and therefore do not need to be considered. Causal representation learning methods provide a way to solve this problem and can handle the identification and analysis of causal relationships more effectively.
##4. Difficulties in the actual implementation of causal inference

Causal inference faces many challenges in practical applications.
- #The weakening of the causal relationship. In many scenarios, causal relationships are often of the same order as random fluctuations in noise, which poses a huge challenge to modeling efforts. In this case, the benefits of modeling are relatively low because the causal relationship itself is not obvious. However, even if modeling is necessary, models with stronger learning capabilities will be needed to accurately capture this weakened causal relationship. At the same time, special attention needs to be paid to the problem of overfitting, because models with strong learning capabilities may be more susceptible to noise, causing the model to overfit the data.
- #The second common problem is insufficient data conditions. The scope of this problem is relatively broad, mainly because the algorithm assumptions we use have many shortcomings, especially when using observational data for modeling, our assumptions may not be completely true. The most typical problems include that the overlap assumption may not be met and our allocation mechanism may lack randomness. A more serious problem is that we don't even have enough random test data, which makes it difficult to objectively evaluate the performance of the model. In this case, if we still insist on modeling and the model performance is better than the year-on-year rule, we can use some business experience to evaluate whether the model's decision is reasonable. From a business perspective, there is no particularly good theoretical solution to situations where some assumptions do not hold, such as unobserved confounding factors. However, if you must use a model, you can try to conduct some small-scale random simulations based on business experience or Tests to assess the direction and magnitude of the influence of confounding factors. At the same time, taking these factors into account in the model, for situations where the overlapping assumption is not met, although this is the fourth issue in our enumeration later, we will discuss it together here. We can use some algorithms to exclude some allocation mechanisms. non-confounding factors, i.e., this problem is alleviated through causal representation learning.
- #When dealing with this complexity, decision-making actions are particularly important. Many existing models focus on solving binary problems. However, when multiple processing solutions are involved, how to allocate resources becomes a more complex problem. To address this challenge, we can decompose multiple solutions into sub-problems in different fields. In addition, using deep learning methods, we can treat processing schemes as features and assume that there is some functional relationship between continuous processing schemes and results. By optimizing the parameters of these functions, continuous decision problems can be better solved, however, this also introduces some additional assumptions, such as overlap issues.
- Allocation mechanism is fixed. See analysis above.
- #Another common problem is having too many target predictions. In some cases, target predictions are affected by multiple factors, which in turn are associated with treatment options. In order to solve this problem, we can use a multi-task learning method. Although it may be difficult to deal with complex role problems directly, we can simplify the problem and only predict the most critical indicators affected by the treatment plan, gradually providing a reference for decision-making.
- #Finally, the cost of random testing in some scenarios is higher, and the effect recovery cycle is longer. It is particularly important to fully evaluate the performance of the model before it goes online. In this case, small-scale randomized testing can be used to evaluate effectiveness. Although the sample set required to evaluate the model is much smaller than the sample set for modeling, if even small-scale random testing is not possible, then we may only be able to judge the reasonableness of the model decision results through business interpretability.
##5. Case - Jingdong Technology’s quota decision-making model
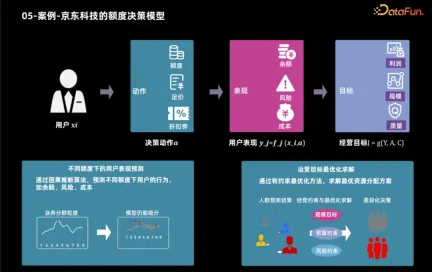
Next, we will take the auxiliary application of JD Technology using causal inference technology to develop credit products as an example to show how to determine the best credit limit based on user characteristics and business goals. After business goals are determined, these goals can usually be broken down into user performance indicators, such as users' product usage and borrowing behavior. By analyzing these indicators, business goals such as profit and scale can be calculated. Therefore, the credit limit decision-making process is divided into two steps: first, use causal inference technology to predict the user's performance under different credit limits, and then use various methods to determine the optimal credit limit for each user based on these performances and operating goals.
6. Future Development

We will face a series of challenges and opportunities in future development.
First of all, in response to the shortcomings of current causal models, academic circles generally believe that large-scale models are needed to handle more complex nonlinear relationships. Causal models typically only deal with two-dimensional data, and most model structures are relatively simple, so future research directions may include addressing this issue.
Secondly, the researchers proposed the concept of causal representation learning, emphasizing the importance of decoupling and modular ideas in representation learning. By understanding the data generation process from a causal perspective, models built based on real-world laws are likely to have better transfer capabilities and generalization.
Finally, the researchers pointed out that the current assumptions are too strong and cannot meet actual needs in many cases, so different models need to be adopted for different scenarios. This also results in a very high threshold for model implementation. Therefore, it is of great value to find a versatile snake oil algorithm.
The above is the detailed content of Focus on it! ! Analysis of two major algorithm frameworks for causal inference. For more information, please follow other related articles on the PHP Chinese website!

 特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM
特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。01 感知 Occupancy Network特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的
 基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM
基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM译者 | 朱先忠审校 | 孙淑娟在我之前的博客中,我们已经了解了如何使用因果树来评估政策的异质处理效应。如果你还没有阅读过,我建议你在阅读本文前先读一遍,因为我们在本文中认为你已经了解了此文中的部分与本文相关的内容。为什么是异质处理效应(HTE:heterogenous treatment effects)呢?首先,对异质处理效应的估计允许我们根据它们的预期结果(疾病、公司收入、客户满意度等)选择提供处理(药物、广告、产品等)的用户(患者、用户、客户等)。换句话说,估计HTE有助于我
 Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM
Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM译者 | 朱先忠审校 | 孙淑娟引言模型超参数(或模型设置)的优化可能是训练机器学习算法中最重要的一步,因为它可以找到最小化模型损失函数的最佳参数。这一步对于构建不易过拟合的泛化模型也是必不可少的。优化模型超参数的最著名技术是穷举网格搜索和随机网格搜索。在第一种方法中,搜索空间被定义为跨越每个模型超参数的域的网格。通过在网格的每个点上训练模型来获得最优超参数。尽管网格搜索非常容易实现,但它在计算上变得昂贵,尤其是当要优化的变量数量很大时。另一方面,随机网格搜索是一种更快的优化方法,可以提供更好的
 因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM
因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM导读:因果推断是数据科学的一个重要分支,在互联网和工业界的产品迭代、算法和激励策略的评估中都扮演者重要的角色,结合数据、实验或者统计计量模型来计算新的改变带来的收益,是决策制定的基础。然而,因果推断并不是一件简单的事情。首先,在日常生活中,人们常常把相关和因果混为一谈。相关往往代表着两个变量具有同时增长或者降低的趋势,但是因果意味着我们想要知道对一个变量施加改变的时候会发生什么样的结果,或者说我们期望得到反事实的结果,如果过去做了不一样的动作,未来是否会发生改变?然而难点在于,反事实的数据往往是
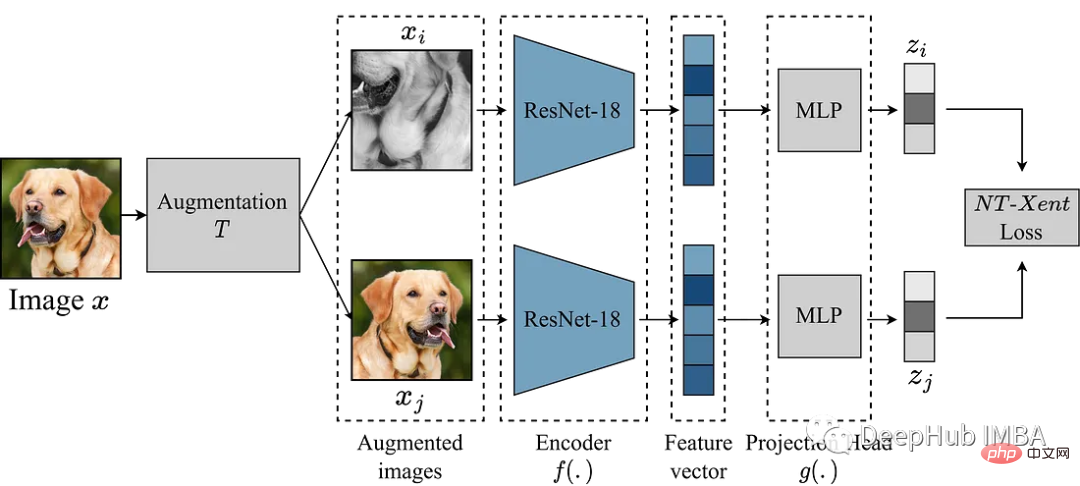 使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PM
使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PMSimCLR(Simple Framework for Contrastive Learning of Representations)是一种学习图像表示的自监督技术。 与传统的监督学习方法不同,SimCLR 不依赖标记数据来学习有用的表示。 它利用对比学习框架来学习一组有用的特征,这些特征可以从未标记的图像中捕获高级语义信息。SimCLR 已被证明在各种图像分类基准上优于最先进的无监督学习方法。 并且它学习到的表示可以很容易地转移到下游任务,例如对象检测、语义分割和小样本学习,只需在较小的标记
 盒马供应链算法实战Apr 10, 2023 pm 09:11 PM
盒马供应链算法实战Apr 10, 2023 pm 09:11 PM一、盒马供应链介绍1、盒马商业模式盒马是一个技术创新的公司,更是一个消费驱动的公司,回归消费者价值:买的到、买的好、买的方便、买的放心、买的开心。盒马包含盒马鲜生、X 会员店、盒马超云、盒马邻里等多种业务模式,其中最核心的商业模式是线上线下一体化,最快 30 分钟到家的 O2O(即盒马鲜生)模式。2、盒马经营品类介绍盒马精选全球品质商品,追求极致新鲜;结合品类特点和消费者购物体验预期,为不同品类选择最为高效的经营模式。盒马生鲜的销售占比达 60%~70%,是最核心的品类,该品类的特点是用户预期时
 研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM
研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM译者 | 李睿 审校 | 孙淑娟随着机器学习成为人们每天都在使用的很多应用程序的一部分,人们越来越关注如何识别和解决机器学习模型的安全和隐私方面的威胁。 然而,不同机器学习范式面临的安全威胁各不相同,机器学习安全的某些领域仍未得到充分研究。尤其是强化学习算法的安全性近年来并未受到太多关注。 加拿大的麦吉尔大学、机器学习实验室(MILA)和滑铁卢大学的研究人员开展了一项新研究,主要侧重于深度强化学习算法的隐私威胁。研究人员提出了一个框架,用于测试强化学习模型对成员推理攻击的脆弱性。 研究
 人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM
人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM10 月 5 日,AlphaTensor 横空出世,DeepMind 宣布其解决了数学领域 50 年来一个悬而未决的数学算法问题,即矩阵乘法。AlphaTensor 成为首个用于为矩阵乘法等数学问题发现新颖、高效且可证明正确的算法的 AI 系统。论文《Discovering faster matrix multiplication algorithms with reinforcement learning》也登上了 Nature 封面。然而,AlphaTensor 的记录仅保持了一周,便被人类


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

