

 Technology peripheralsAIAn American professor used his 2-year-old daughter to train an AI model to appear in Science! Human cubs use head-mounted cameras to train new AI
Technology peripheralsAIAn American professor used his 2-year-old daughter to train an AI model to appear in Science! Human cubs use head-mounted cameras to train new AI
Absolutely, in order to train an AI model, a professor from the State University of New York strapped a GoPro-like camera to his daughter’s head!
Although it sounds incredible, this professor’s behavior is actually well-founded.

To train the complex neural network behind LLM, a massive amount of data is required.
Is our current LLM training process necessarily the simplest and most efficient way?
Certainly not! Scientists have discovered that in human toddlers, the brain absorbs water like a sponge, quickly forming a coherent worldview.

Although LLM has amazing performance at times, over time, human children will become smarter and smarter than the model. Be more creative!
The secret of children mastering language
How to train LLM in a better way?
When scientists were puzzled, human cubs made their eyes light up——
The way they learn language, He is a master of language acquisition.

We all know this story: throw a young child into a country with a completely different language and culture, and within a few months, he will... The mastery of the local language may be close to the native level.
The large language model pales in comparison.
First of all, they are too data intensive!
Nowadays, major companies that train models have almost exhausted all the data in the world. Because LLM learning requires astronomical amounts of text mined from the Internet and various places.
For them to master a language, you need to feed them trillions of words.

Brenden Lake and the NYU scholars who participated in this study
Secondly, they smashed such a With too much data, LLM may not learn accurately.
The output of many LLMs is to predict the next word with a certain accuracy. And this accuracy is increasingly disturbing.
In stark contrast, children do not need so much experience to learn to speak a language fluently.
Brenden Lake, a psychologist at the State University of New York who studies humans and AI, is focusing on this.
He decided to conduct an experiment on his 1-year-old and 9-month-old daughter Luna.

For the past 11 months, Lake has let her daughter wear a camera for an hour every week to record videos from her perspective while playing.
With videos captured by Luna’s cameras, Lake hopes to train models by using the same data that children are exposed to.

Strapped a GoPro to my toddler daughter
While currently linguists and children Experts do not agree on how children acquire language, but Lake is convinced that the secret to making LLM more efficient lies in children's learning patterns!
Therefore, Lake launched a research project: studying the stimulation that children experience when learning their first words, in order to improve the efficiency of training LLM.
To do this, Lake's team needed to collect video and audio data from 25 children across the United States.
This is the scene at the beginning of the article - they tied GoPro-like cameras to the heads of these children, including Lake's daughter Luna.

Lake explained that their model attempts to connect video clips from the child's perspective with what the child's caregiver is saying, in a similar way OpenAI’s Clip model connects annotations to images.
Clip can take an image as input and output a descriptive annotation as a suggestion based on training data of image-annotation pairs.

Paper address: https://openai.com/index/clip/
In addition, Lake's team's model can also take as input an image of a scene, based on training data from GoPro footage and caregiver audio, and then output language to describe the scene.
Furthermore, the model can also convert descriptions to frames previously seen in training.
At first glance, doesn’t it sound quite simple? That is, the model learns to match spoken words to objects observed in video frames, just like human children.
But in actual implementation, we will still face many complex situations.
For example, children do not always look at the object or action being described.
There are even more abstract situations, such as when we give milk to our children, but the milk is in an opaque cup, which leads to a very loose connection.
Thus, Lake explained: This experiment was not intended to prove whether we can train a model to match objects in images with corresponding words (OpenAI has already demonstrated this).
# Instead, what the team wanted to do was to see if the model could be modeled using only the sparse data levels available to children (which are incredibly sparse). ), you can actually learn to recognize objects.
As you can see, this is completely opposite to the way big companies such as OpenAI, Google, and Meta build models.
You know, Meta used 15 trillion tokens to train Llama 3.
If the Lake team's experiment is successful, perhaps the LLM data shortage faced by the whole world will be solved - because then, training LLM will not require so much data at all!
In other words, the new idea is to let the AI model learn from limited inputs and then generalize from the data we see .
I think our focus should not be limited to training larger and larger LLMs from more and more data. Yes, you can get amazing performance from LLM this way, but it's getting further and further away from the wonders of human intelligence we know...
Early experiments have been successful
The early experimental results have proven that the Lake team's idea may be right.
In February this year, they used 61 hours of video footage to train a neural network to record the experience of a young child.
The study found that the model was able to connect the various words and phrases spoken by the subjects to the experiences captured in the video frames - as long as the word or phrase was presented, the model Ability to recall relevant images. This paper has been published in Science.

Paper address: https://www.science.org/doi/10.1126/science.adi1374
Lake said that the most surprising thing is that the model can generalize the names of objects in untrained images!
Of course, the accuracy may not be very good. But the model was originally just to verify a concept.
The project is not yet complete because the model has not learned everything a child would know.

After all, it’s only about 60 hours of annotated speech, which is only one percent of the experience a child acquires in two years one. And the team needs more data to figure out what is learnable.
And Lake also admitted that the method used by the first model still has limitations-
Only analyzes the words related to the caregiver’s words Video clips are just shots converted into images at a speed of 5 frames per second. Based on these alone, AI does not really learn what verbs are and what abstract words are. It only obtains static slices of what the world looks like.
Because it knows nothing about what happened before, what happened after, or the context of the conversation, it is difficult to learn what "walking", "running" and "jumping" are.
But in the future, as the technology behind modeling videos becomes more mature, Lake believes the team will build more effective models.
If we could build a model of how language acquisition actually begins, it would open up important applications for understanding human learning and development, and perhaps help us understand development disorders, or conditions in which children learn language.
Eventually, such models could be used to test millions of different speech therapies.
Having said that, how do children solidly master a language through their own eyes and ears?

Let’s take a closer look at this article posted by the Lake team in Science.
Connect words with real objects and visual images
How do human children shed their ignorance of the world and acquire knowledge? The mystery of this "black box" not only attracts the constant pursuit of educationists, but also questions the origin of individual wisdom trapped in the hearts of each of us.
Korean science fiction writer Kim Cho-ye wrote this assumption in "The Symbiosis Hypothesis": The wisdom displayed by human children in their early years actually carries a lost alien civilization. They chose to coexist with humans in this way, but it only lasted for five short years. After humans grew up and had truly solid memories, they erased the magnificent memories of their childhood.
Netizens often share stories online about human cubs who "forgot to drink Meng Po soup".
Regarding the enigmatic childhood, it is a mysterious place that is difficult for us to explain and difficult to return to. It is a kind of "nostalgia". As it is written on a golden blade of grass, "Don't leave." Don’t take away that beautiful world. When I grow up, please stay with me.

How do young children associate new words with specific objects or visual concepts?
For example, when hearing the word "ball", how do children think of elastic round objects?

To this end, Lake's team put a head-mounted camera on a child and tracked his growth from 6 to 25 months old, recording a 61-hour stream of visual and verbal data.
On this 1.5-year-old children's clip data set (including 600,000 video frames and 37,500 transcribed utterance pairs), the researchers trained a model, namely children's perspective contrastive learning Model CVCL.
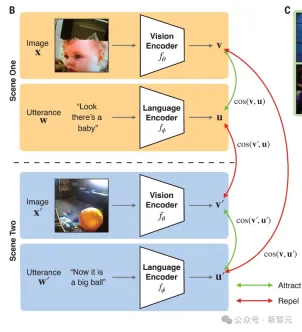
This model instantiates a form of associative learning across situations, identifying mappings between words and possible visual referents.
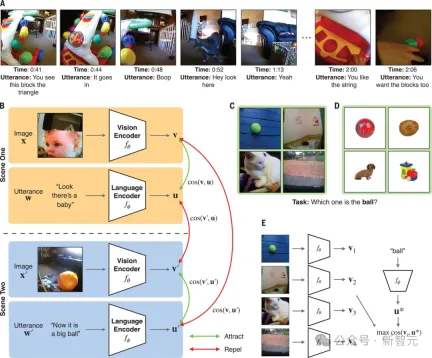
This model coordinates the contrasting objectives of two neural networks, a visual encoder and a language encoder, and is trained in a self-supervised manner (i.e. Using only child-view recordings and no external labels), the comparison objective combines embeddings (vectors) of video frames and temporally co-occurring verbal utterances (processing embeddings of simultaneous video frames and verbal utterances)
Of course, this dataset, called SAYCam-S, is limited because it only captures about 1% of a child's waking time, missing a lot of their experience.
But despite this, CVCL can still learn powerful multi-modal representations from a child’s limited experience!
The team successfully demonstrated that the model acquires many referential mappings that exist in children's daily experiences, and is therefore able to generalize new visual referents with zero samples and adjust the visual and Linguistic concept system.
Evaluate the learned word meaning mapping
Specifically, after training was completed, the team evaluated what CVCL and various alternative models had learned The quality of the word-referent mapping.
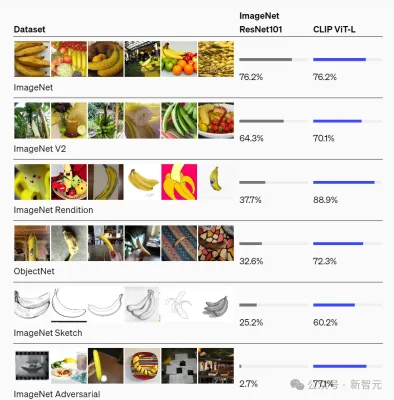
The results show that the classification accuracy of CVCL is 61.6%.
Moreover, Figure 2D shows that for 11 of the 22 concepts, the performance of CVCL is within 5% of the error of CLIP, but the training data of CLIP is more Several orders of magnitude (400 million image-text pairs from the web).
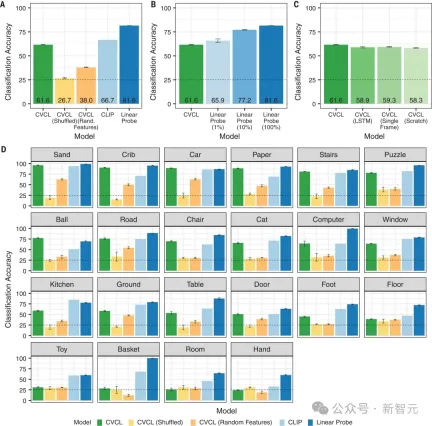
The results show that many of the earliest word referent mappings can be obtained from at least 10 to 100 naturally occurring word-referent pairs. .
Generalize to new visual paradigms
In addition, the researchers also evaluated whether the words learned by CVCL can be generalized to out-of-distribution On visual stimulation.
Figure 3A shows that CVCL also shows some understanding of these visual concepts, with an overall accuracy of 34.7%.
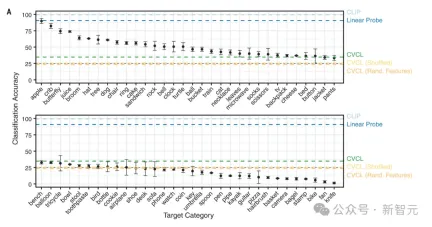
Obviously, this task requires a larger concept set, and the extra difficulty of out-of-distribution generalization.

On the left are two randomly selected training cases, and on the right are four test cases. The percentage below represents the accuracy of the model in identifying this image. and performance, the selected cases are the two highest values, the median value and the lowest value respectively from left to right. It can be seen that when the test case and the training case are more similar in color and shape, the accuracy of model recognition is also higher
Multi-modal consistency is very good
Finally, the researchers tested the consistency of CVCL’s visual and language concept systems.
For example, if the visual embedding and word embedding of "car" are more similar to "road" than to "ball", this indicates that multi-modal alignment works well .
The following figure shows the high degree of alignment of CVCL's visual and language systems.
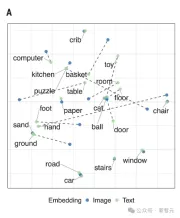
The relationship between the image and text, the dotted line represents the distance between the visual centroid corresponding to each concept and the word embedding
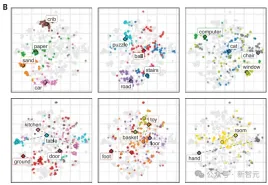
Different visual concepts vary in how tightly their examples are clustered. Because the baby's line of sight will wander between objects that are very close, the model does not form a clear reference mapping when distinguishing "hands" and "toys". "Car" and "crib" have better performance
In each figure, we visually demonstrate the comparison of CVCL predictions with labeled examples using t-SNE.

The blue points on the left correspond to the 100 frames belonging to a specific category, and the green points on the right correspond to the 100 highest activated frames (based on cosine similarity to the word embedding of each concept in CVCL). Below each figure are multiple example frames belonging to one or more sub-clusters within each concept, capturing how word embeddings interact with image embeddings in the joint embedding space. For example, for the word "stairs," we see one cluster representing images of indoor wooden stairs, while another main cluster represents images of a set of blue stairs outdoors. All t-SNE graphs in these figures are derived from the same set of joint image and text embeddings.
The following figure shows that the model can be positioned in different views to locate the target.

In the normalized attention map, yellow indicates the area with the highest attention. In the first two categories (ball and rook) we can see that the model can locate the target in different views. However, in the lower two categories (cat and paper), attention maps were sometimes misaligned with the referent, suggesting that the ability to locate the referent was not consistent across categories.
Of course, there are still many differences between children's learning and machine learning models.
But the Lake team’s research has undoubtedly inspired us a lot.
The above is the detailed content of An American professor used his 2-year-old daughter to train an AI model to appear in Science! Human cubs use head-mounted cameras to train new AI. For more information, please follow other related articles on the PHP Chinese website!

 从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM
从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM1 前言在发布DALL·E的15个月后,OpenAI在今年春天带了续作DALL·E 2,以其更加惊艳的效果和丰富的可玩性迅速占领了各大AI社区的头条。近年来,随着生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion models)的出现,深度学习已向世人展现其强大的图像生成能力;加上GPT-3、BERT等NLP模型的成功,人类正逐步打破文本和图像的信息界限。在DALL·E 2中,只需输入简单的文本(prompt),它就可以生成多张1024*1024的高清图像。这些图像甚至
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM
普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM“Making large models smaller”这是很多语言模型研究人员的学术追求,针对大模型昂贵的环境和训练成本,陈丹琦在智源大会青源学术年会上做了题为“Making large models smaller”的特邀报告。报告中重点提及了基于记忆增强的TRIME算法和基于粗细粒度联合剪枝和逐层蒸馏的CofiPruning算法。前者能够在不改变模型结构的基础上兼顾语言模型困惑度和检索速度方面的优势;而后者可以在保证下游任务准确度的同时实现更快的处理速度,具有更小的模型结构。陈丹琦 普
 解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM
解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?近期一些工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。基于此,来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer——Next-ViT。从延迟 / 准确性权衡的角度看,
 Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM
Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM3月27号,Stability AI的创始人兼首席执行官Emad Mostaque在一条推文中宣布,Stable Diffusion XL 现已可用于公开测试。以下是一些事项:“XL”不是这个新的AI模型的官方名称。一旦发布稳定性AI公司的官方公告,名称将会更改。与先前版本相比,图像质量有所提高与先前版本相比,图像生成速度大大加快。示例图像让我们看看新旧AI模型在结果上的差异。Prompt: Luxury sports car with aerodynamic curves, shot in a
 五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM
五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM人工智能就是一个「拼财力」的行业,如果没有高性能计算设备,别说开发基础模型,就连微调模型都做不到。但如果只靠拼硬件,单靠当前计算性能的发展速度,迟早有一天无法满足日益膨胀的需求,所以还需要配套的软件来协调统筹计算能力,这时候就需要用到「智能计算」技术。最近,来自之江实验室、中国工程院、国防科技大学、浙江大学等多达十二个国内外研究机构共同发表了一篇论文,首次对智能计算领域进行了全面的调研,涵盖了理论基础、智能与计算的技术融合、重要应用、挑战和未来前景。论文链接:https://spj.scien
 什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM
什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM译者 | 李睿审校 | 孙淑娟近年来, Transformer 机器学习模型已经成为深度学习和深度神经网络技术进步的主要亮点之一。它主要用于自然语言处理中的高级应用。谷歌正在使用它来增强其搜索引擎结果。OpenAI 使用 Transformer 创建了著名的 GPT-2和 GPT-3模型。自从2017年首次亮相以来,Transformer 架构不断发展并扩展到多种不同的变体,从语言任务扩展到其他领域。它们已被用于时间序列预测。它们是 DeepMind 的蛋白质结构预测模型 AlphaFold
 AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM
AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM说起2010年南非世界杯的最大网红,一定非「章鱼保罗」莫属!这只位于德国海洋生物中心的神奇章鱼,不仅成功预测了德国队全部七场比赛的结果,还顺利地选出了最终的总冠军西班牙队。不幸的是,保罗已经永远地离开了我们,但它的「遗产」却在人们预测足球比赛结果的尝试中持续存在。在艾伦图灵研究所(The Alan Turing Institute),随着2022年卡塔尔世界杯的持续进行,三位研究员Nick Barlow、Jack Roberts和Ryan Chan决定用一种AI算法预测今年的冠军归属。预测模型图


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

WebStorm Mac version
Useful JavaScript development tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

