


我们经常会在发现页面中无故多了一些空白行了,但在编辑器中又看到到,这个我们知道是由BOM(UTF-8)导致的,下面小编来给大家分享几种关于BOM(UTF-8)检测与删除方法。
下图是出现前面说的情况后用firebug看到的HTML代码。
图1
里面莫名其妙多出了一个空白行,而我们看源代码里面却没有。
我最常用的办法,利用php替换
BOM: 万国码档案签名 BOM (Byte Order Mark, U+FEFF)
BOM 的内容可以表示 UNICODE 是哪种编码, 但是在接收到的档案, 要拆解后写入 DB, 看到 BOM 就觉得有点 ooxx.
在 utf8_encode 看到两段程式可以来测试 写入/移除 BOM.
将写入的档案内容前加 BOM
| 代码如下 | 复制代码 |
|
function writeUTF8File($filename,$content) |
|
移除 BOM function
| 代码如下 | 复制代码 |
|
function removeBOM($str = '') |
|
由此上述 BOM = pack("CCC",0xef,0xbb,0xbf), 所以移除 BOM 的写法可用上面的 removeBOM function 或 下述其一:
■str_replace("锘�", '', $bom_content);
■preg_replace("/^锘�/", '', $bom_content);
另外看到 判断此字串是不是 UTF-8 的 function:
| 代码如下 | 复制代码 |
|
function isUTF8($string) |
|
linux系统中使用shell来解决
在详细讨论UTF-8编码中BOM的检测与删除问题前,不妨先通过一个例子热热身:
| 代码如下 | 复制代码 |
| shell> curl -s http://www.bKjia.c0m/ | head -1 | sed -n l 锘�br /> //EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> $ |
|
如上所示,前三个字节分别是357、273、277,这就是八进制的BOM。
| 代码如下 | 复制代码 |
| shell> curl -s http://www.111cn.Net/ | head -1 | hexdump -C 00000000 ef bb bf 3c 21 44 4f 43 54 59 50 45 20 68 74 6d |... 00000010 6c 20 50 55 42 4c 49 43 20 22 2d 2f 2f 57 33 43 |l PUBLIC "-//W3C| 00000020 2f 2f 44 54 44 20 58 48 54 4d 4c 20 31 2e 30 20 |//DTD XHTML 1.0 | 00000030 54 72 61 6e 73 69 74 69 6f 6e 61 6c 2f 2f 45 4e |Transitional//EN| 00000040 22 20 22 68 74 74 70 3a 2f 2f 77 77 77 2e 77 33 |" "http://www.w3| 00000050 2e 6f 72 67 2f 54 52 2f 78 68 74 6d 6c 31 2f 44 |.org/TR/xhtml1/D| 00000060 54 44 2f 78 68 74 6d 6c 31 2d 74 72 61 6e 73 69 |TD/xhtml1-transi| 00000070 74 69 6f 6e 61 6c 2e 64 74 64 22 3e 0d 0a |tional.dtd">..| |
|
如上所示,前三个字节分别是EF、BB、BF,这就是十六进制的BOM。 注:用到了第三方网站的页面,不能保证例子始终可用。 实际做项目开发时,可能会面对成百上千个文本文件,如果有几个文件混入了BOM,那么很难察觉,如果没有带BOM的UTF-8文本文件,可以用vi杜撰几个,相关命令如下:
设置UTF-8编码:
| 代码如下 | 复制代码 |
| :set fileencoding=utf-8 | |
添加BOM:
| 代码如下 | 复制代码 |
| :set bomb | |
删除BOM:
| 代码如下 | 复制代码 |
| :set nobomb | |
查询BOM:
| 代码如下 | 复制代码 |
| :set bomb? | |
如何检测UTF-8编码中的BOM呢?
| 代码如下 | 复制代码 |
|
shell> grep -r -I -l $'^锘�' /path如何删除UTF-8编码中的BOM呢? shell> grep -r -I -l $'^锘�' /path | xargs sed -i 's/^锘�//;q' |
|
推荐:如果你使用SVN的话,可以在pre-commit钩子里加上相关代码用以杜绝BOM。
| 代码如下 | 复制代码 |
|
#!/bin/bash REPOS="$1" SVNLOOK=/usr/bin/svnlook for FILE in $($SVNLOOK changed -t "$TXN" "$REPOS" | awk '/^[AU]/ {print $NF}'); do |
|
本文用到了很多shell命令
方法三,利用ultraedit编辑器直接修改文档
把出现空行的文档另存没没有BOM的格式就行了。
下图是ultraedit保存文档时的编码格式:
图2
选择里面的UTF8-无BOM,一切解决

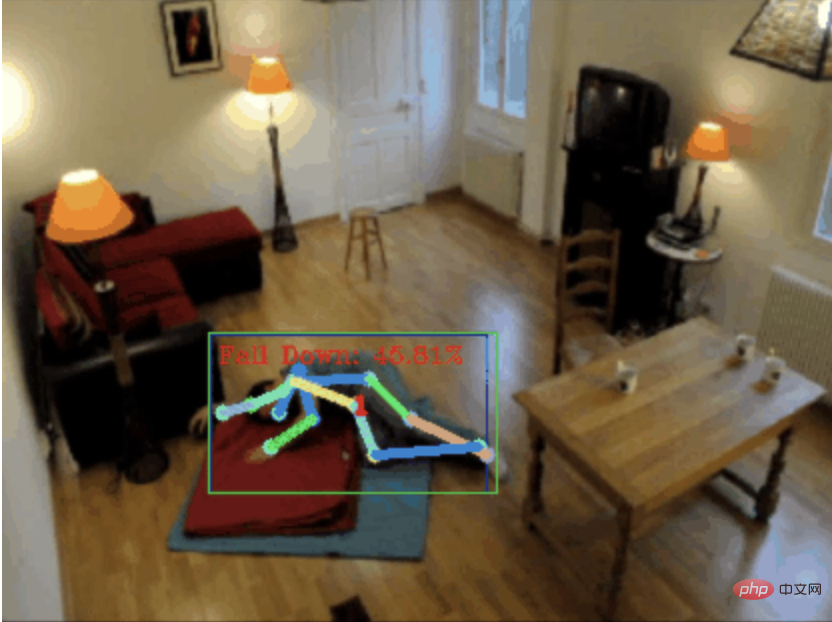 摔倒检测,基于骨骼点人体动作识别,部分代码用 Chatgpt 完成Apr 12, 2023 am 08:19 AM
摔倒检测,基于骨骼点人体动作识别,部分代码用 Chatgpt 完成Apr 12, 2023 am 08:19 AM哈喽,大家好。今天给大家分享一个摔倒检测项目,准确地说是基于骨骼点的人体动作识别。大概分为三个步骤识别人体识别人体骨骼点动作分类项目源码已经打包好了,获取方式见文末。0. chatgpt首先,我们需要获取监控的视频流。这段代码比较固定,我们可以直接让chatgpt完成chatgpt写的这段代码是没有问题的,可以直接使用。但后面涉及到业务型任务,比如:用mediapipe识别人体骨骼点,chatgpt给出的代码是不对的。我觉得chatgpt可以作为一个工具箱,能独立于业务逻辑,都可以试着交给c
 i7-7700无法升级至Windows 11的解决方案Dec 26, 2023 pm 06:52 PM
i7-7700无法升级至Windows 11的解决方案Dec 26, 2023 pm 06:52 PMi77700的性能运行win11完全足够,但是用户却发现自己的i77700不能升级win11,这主要是受到了微软硬性条件的限制,所以只要跳过该限制就能安装了。i77700不能升级win11:1、因为微软限制了cpu的版本。2、intel只有第八代及以上版本可以直升win11。3、而i77700作为7代,无法满足win11的升级需求。4、但是i77700在性能上是完全能流畅使用win11的。5、所以大家可以使用本站的win11直装系统。6、下载完成后,右键“装载”该文件。7、再双击运行其中的“一键
![从 Windows 10/11 中删除用户帐户的 5大方法 [2023]](https://img.php.cn/upload/article/000/465/014/168782606547724.png) 从 Windows 10/11 中删除用户帐户的 5大方法 [2023]Jun 27, 2023 am 08:34 AM
从 Windows 10/11 中删除用户帐户的 5大方法 [2023]Jun 27, 2023 am 08:34 AM您的WindowsPC上有多个过时的帐户?或者,由于某些错误,您是否在从系统中删除这些帐户时陷入困境?无论出于何种原因,您都应该尽快从计算机中删除那些未使用的用户帐户。这样,您将节省大量空间并修复系统中可能的漏洞点。在本文中,我们通过详细步骤详细阐述了多种用户帐户删除方法。方法1–使用设置这是从系统中删除任何帐户的标准方法。步骤1–按Win+I键应打开“设置”窗口。步骤2–转到“帐户”。第3步–找到“其他用户”将其打开。第4步–您将在屏幕右侧找到所有帐户。步骤5–只需在那里扩展帐户即可。在帐户和
 MIT最新力作:用GPT-3.5解决时间序列异常检测问题Jun 08, 2024 pm 06:09 PM
MIT最新力作:用GPT-3.5解决时间序列异常检测问题Jun 08, 2024 pm 06:09 PM今天给大家介绍一篇MIT上周发表的文章,使用GPT-3.5-turbo解决时间序列异常检测问题,初步验证了LLM在时间序列异常检测中的有效性。整个过程没有进行finetune,直接使用GPT-3.5-turbo进行异常检测,文中的核心是如何将时间序列转换成GPT-3.5-turbo可识别的输入,以及如何设计prompt或者pipeline让LLM解决异常检测任务。下面给大家详细介绍一下这篇工作。图片论文标题:Largelanguagemodelscanbezero-shotanomalydete
 改进的检测算法:用于高分辨率光学遥感图像目标检测Jun 06, 2024 pm 12:33 PM
改进的检测算法:用于高分辨率光学遥感图像目标检测Jun 06, 2024 pm 12:33 PM01前景概要目前,难以在检测效率和检测结果之间取得适当的平衡。我们就研究出了一种用于高分辨率光学遥感图像中目标检测的增强YOLOv5算法,利用多层特征金字塔、多检测头策略和混合注意力模块来提高光学遥感图像的目标检测网络的效果。根据SIMD数据集,新算法的mAP比YOLOv5好2.2%,比YOLOX好8.48%,在检测结果和速度之间实现了更好的平衡。02背景&动机随着远感技术的快速发展,高分辨率光学远感图像已被用于描述地球表面的许多物体,包括飞机、汽车、建筑物等。目标检测在远感图像的解释中
 怎么彻底删除快应用May 31, 2023 am 09:48 AM
怎么彻底删除快应用May 31, 2023 am 09:48 AM彻底删除快应用的方法:1、打开手机设置界面,点击打开“应用设置”;2、在应用设置界面,选择“应用管理”点击打开;3、进入应用管理界面,界面选择“快应用服务框架”点击打开;4、进入快应用服务框架界面,选择“卸载更新”选项并打开;5、界面显示窗口点击“确定”即可彻底删除快应用。
 AAAI2024:Far3D - 创新的直接干到150m视觉3D目标检测思路Dec 15, 2023 pm 01:54 PM
AAAI2024:Far3D - 创新的直接干到150m视觉3D目标检测思路Dec 15, 2023 pm 01:54 PM最近在Arxiv上阅读到一篇关于纯视觉环视感知的最新研究,该研究基于PETR系列方法,并专注于解决远距离目标检测的纯视觉感知问题,将感知范围扩大到150米。这篇论文的方法和结果对我们来说有很大的参考价值,所以我尝试着对其进行解读原标题:Far3D:ExpandingtheHorizonforSurround-view3DObjectDetection论文链接:https://arxiv.org/abs/2308.09616作者单位:北京理工大学&旷视科技任务背景三维物体检测在理解自动驾驶
 PHP语言开发中如何检测和处理空值错误?Jun 11, 2023 am 10:51 AM
PHP语言开发中如何检测和处理空值错误?Jun 11, 2023 am 10:51 AM随着现代Web应用不断发展,PHP作为其中最流行的编程语言之一,被广泛地应用于网站开发中。但在开发过程中,经常会遇到空值错误,而这些错误会导致应用程序抛出异常,进而影响用户的使用体验。因此,在PHP开发过程中,如何检测和处理空值错误,是程序员们需要掌握的重要技能。一、什么是空值错误在PHP开发过程中,空值错误通常指的是两种情况:变量未初始化和变


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

SublimeText3 English version
Recommended: Win version, supports code prompts!

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver CS6
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

