


用Python实现常规的静态网页抓取时,往往是用urllib2来获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字。如下所示:
import urllib2
url="http://mm.taobao.com/json/request_top_list.htm?type=0&page=1"
up=urllib2.urlopen(url)#打开目标页面,存入变量up
cont=up.read()#从up中读入该HTML文件
key1=' pa=cont.find(key1)#找出关键字1的位置
pt=cont.find(key2,pa)#找出关键字2的位置(从字1后面开始查找)
urlx=cont[pa:pt]#得到关键字1与关键字2之间的内容(即想要的数据)
print urlx
但是,在动态页面中,所显示的内容往往不是通过HTML页面呈现的,而是通过调用js等方式从数据库中得到数据,回显到网页上。以发改委网站上的“备案信息”(http://beian.hndrc.gov.cn/)为例,要抓取此页面中的某些备案项目。例如“http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518”。
那么,在浏览器中打开此页面:
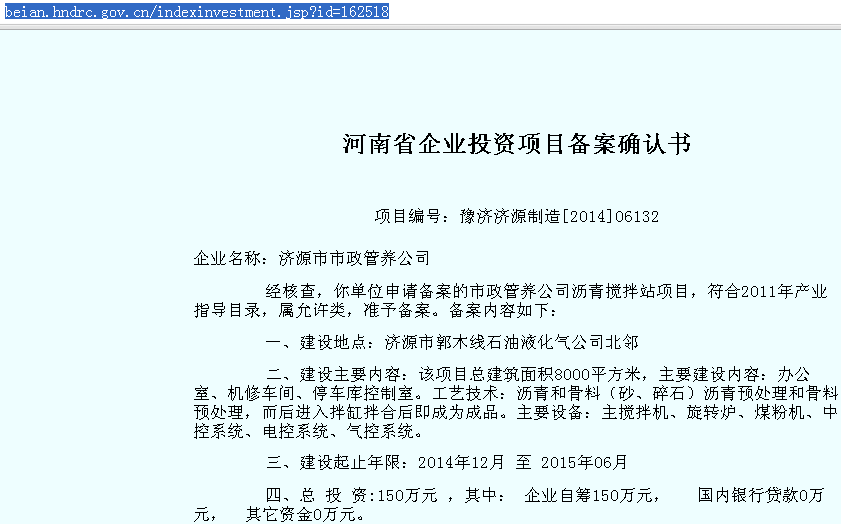
相关信息都显示的很全了,但是如果按照之前的办法:
up=urllib2.urlopen(url)
cont=up.read()
就抓取不到上述内容了。
我们查看一下这个页面对应的源码:

由源码可以看出,这个《备案确认书》属于“填空”形式的,HTML提供文字模板,js根据不同的id提供不同的变量,“填入”到文字模板中,形成了一个具体的《备案确认书》。所以单纯抓取此HTML,只能得到一些文字模板,而无法得到具体内容。
那么,该如何找到那些具体内容呢?可以利用Chrome的“开发者工具”来寻找谁是真正的内容提供者。
打开Chrome浏览器,按下键盘F12即可呼出此工具。如下图:
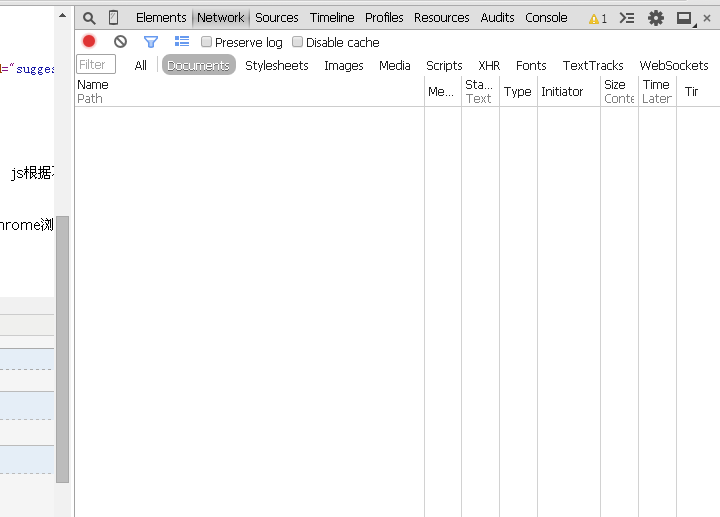
此时选中“Network”标签,在地址栏中输入此页面“http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518”,浏览器会分析出此次响应的全过程,而红框内的文件,就是此次响应中,浏览器和web后端的所有通信。

因为要获得不同企业对应的不同信息,那么浏览器发送给服务器的请求里面一定会有一个和当前企业id有关的参数。
那么,参数是多少呢?URL上有,是“jsp?id=162518”,问号表示要调用参数,后面跟的是id号即是被调用的参数。而通过对这几个文件的分析,很显然,企业信息存在于“indexinvestment.action”文件中。

然而,双击打开此文件并不能获得企业信息,而是一堆代码。因为没有对应的参数为它指明要显示第几号的信息。如图:

那么,应该如何将参数传递给它呢?这时我们仍旧看F12窗口:
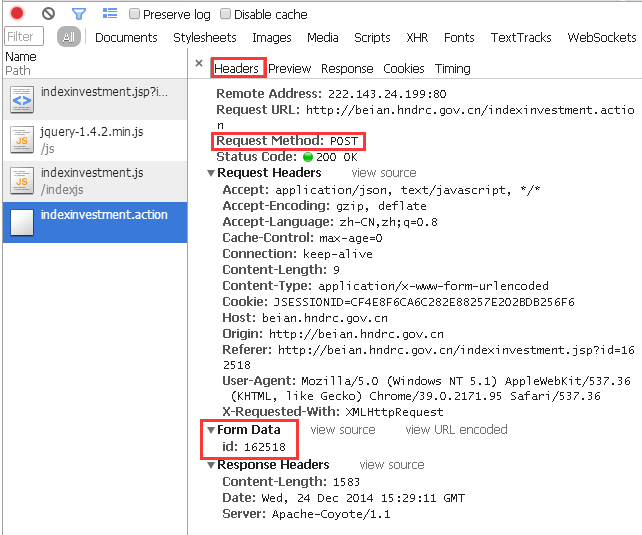
“Header”一栏中明确地显示出了此次响应的过程:
对目标URL,用POST的方式,传递了一个id为162518的参数。
我们先手工操作一下。js是如何调用参数的呢?对,上面说过:问号+变量名+等号+变量对应的数字。也就是说,向“http://beian.hndrc.gov.cn/indexinvestment.action”这个页面提交id为162518的参数时,应该在URL后面加上
“?id=162518”,即
“http://beian.hndrc.gov.cn/indexinvestment.action?id=162518”。
我们把这个URL粘贴到浏览器中来看:

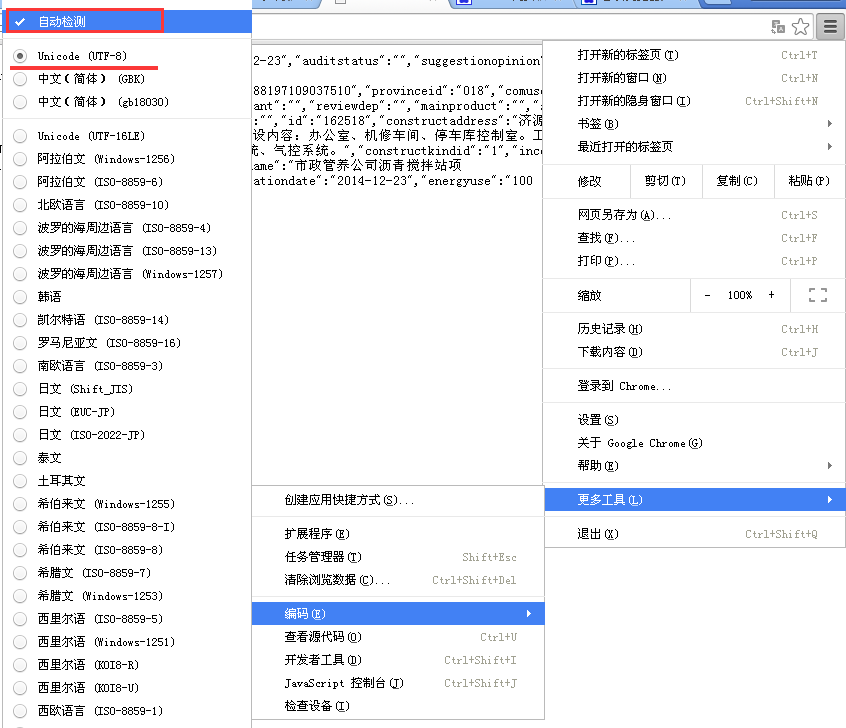
似乎有了点内容,可是都是乱码啊,怎么破?熟悉的朋友可能一眼就看出来,这是编码的问题。是因为响应回来的内容与浏览器默认的编码方式不同。只需要在Chrome右上角菜单——更多工具——编码——“自动检测”即可。(其实这是UTF-8的编码,而Chrome默认的是中文简体)。如下图:
好了,真正的信息源已经被挖出,剩下的就是用Python处理这些页面上的字符串,然后剪切、拼接,重新组成新的《项目备案书》了。
再然后使用for、while等循环,批量获取这些《备案书》。
正如“不论是静态网页,动态网页,模拟登陆等,都要先分析、搞懂逻辑,再去写代码”所说,编程语言只是一个工具,重要的是解决问题的思路。有了思路,再寻找趁手的工具去解决,就OK了。

 Python: Games, GUIs, and MoreApr 13, 2025 am 12:14 AM
Python: Games, GUIs, and MoreApr 13, 2025 am 12:14 AMPython excels in gaming and GUI development. 1) Game development uses Pygame, providing drawing, audio and other functions, which are suitable for creating 2D games. 2) GUI development can choose Tkinter or PyQt. Tkinter is simple and easy to use, PyQt has rich functions and is suitable for professional development.
 Python vs. C : Applications and Use Cases ComparedApr 12, 2025 am 12:01 AM
Python vs. C : Applications and Use Cases ComparedApr 12, 2025 am 12:01 AMPython is suitable for data science, web development and automation tasks, while C is suitable for system programming, game development and embedded systems. Python is known for its simplicity and powerful ecosystem, while C is known for its high performance and underlying control capabilities.
 The 2-Hour Python Plan: A Realistic ApproachApr 11, 2025 am 12:04 AM
The 2-Hour Python Plan: A Realistic ApproachApr 11, 2025 am 12:04 AMYou can learn basic programming concepts and skills of Python within 2 hours. 1. Learn variables and data types, 2. Master control flow (conditional statements and loops), 3. Understand the definition and use of functions, 4. Quickly get started with Python programming through simple examples and code snippets.
 Python: Exploring Its Primary ApplicationsApr 10, 2025 am 09:41 AM
Python: Exploring Its Primary ApplicationsApr 10, 2025 am 09:41 AMPython is widely used in the fields of web development, data science, machine learning, automation and scripting. 1) In web development, Django and Flask frameworks simplify the development process. 2) In the fields of data science and machine learning, NumPy, Pandas, Scikit-learn and TensorFlow libraries provide strong support. 3) In terms of automation and scripting, Python is suitable for tasks such as automated testing and system management.
 How Much Python Can You Learn in 2 Hours?Apr 09, 2025 pm 04:33 PM
How Much Python Can You Learn in 2 Hours?Apr 09, 2025 pm 04:33 PMYou can learn the basics of Python within two hours. 1. Learn variables and data types, 2. Master control structures such as if statements and loops, 3. Understand the definition and use of functions. These will help you start writing simple Python programs.
 How to teach computer novice programming basics in project and problem-driven methods within 10 hours?Apr 02, 2025 am 07:18 AM
How to teach computer novice programming basics in project and problem-driven methods within 10 hours?Apr 02, 2025 am 07:18 AMHow to teach computer novice programming basics within 10 hours? If you only have 10 hours to teach computer novice some programming knowledge, what would you choose to teach...
 How to avoid being detected by the browser when using Fiddler Everywhere for man-in-the-middle reading?Apr 02, 2025 am 07:15 AM
How to avoid being detected by the browser when using Fiddler Everywhere for man-in-the-middle reading?Apr 02, 2025 am 07:15 AMHow to avoid being detected when using FiddlerEverywhere for man-in-the-middle readings When you use FiddlerEverywhere...
 What should I do if the '__builtin__' module is not found when loading the Pickle file in Python 3.6?Apr 02, 2025 am 07:12 AM
What should I do if the '__builtin__' module is not found when loading the Pickle file in Python 3.6?Apr 02, 2025 am 07:12 AMError loading Pickle file in Python 3.6 environment: ModuleNotFoundError:Nomodulenamed...


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

WebStorm Mac version
Useful JavaScript development tools

