
Home >Backend Development >Python Tutorial >使用Python抓取模板之家的CSS模板
使用Python抓取模板之家的CSS模板

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-06-10 15:17:111453browse
Python版本是2.7.9,在win8上测试成功,就是抓取有点慢,本来想用多线程的,有事就罢了。模板之家的网站上的url参数与页数不匹配,懒得去做分析了,就自己改代码中的url吧。大神勿喷!
复制代码 代码如下:
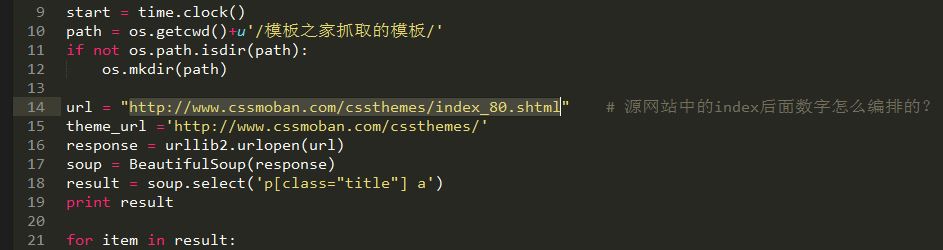
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# by ustcwq
# 2015-03-15
import urllib,urllib2,os,time
from bs4 import BeautifulSoup
start = time.clock()
path = os.getcwd()+u'/模板之家抓取的模板/'
if not os.path.isdir(path):
os.mkdir(path)
url = "http://www.cssmoban.com/cssthemes/index_80.shtml" # 源网站中的index后面数字怎么编排的?
theme_url ='http://www.cssmoban.com/cssthemes/'
response = urllib2.urlopen(url)
soup = BeautifulSoup(response)
result = soup.select('p[class="title"] a')
print result
for item in result:
link = item['href']
# down_name = item.text # 文件名称
new_url = theme_url+link.split('/')[-1]
response = urllib2.urlopen(new_url)
soup = BeautifulSoup(response)
result = soup.select('.btn a')
down_url = result[1]['href'] # 文件链接
local = path+time.strftime('%Y%m%d%H%M%S',time.localtime(time.time()))+'.zip'
urllib.urlretrieve(down_url, local) # 远程保存函数
end = time.clock()
print u'模板抓取完成!'
print u'一共用时:',end-start,u'秒'
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# by ustcwq
# 2015-03-15
import urllib,urllib2,os,time
from bs4 import BeautifulSoup
start = time.clock()
path = os.getcwd()+u'/模板之家抓取的模板/'
if not os.path.isdir(path):
os.mkdir(path)
url = "http://www.cssmoban.com/cssthemes/index_80.shtml" # 源网站中的index后面数字怎么编排的?
theme_url ='http://www.cssmoban.com/cssthemes/'
response = urllib2.urlopen(url)
soup = BeautifulSoup(response)
result = soup.select('p[class="title"] a')
print result
for item in result:
link = item['href']
# down_name = item.text # 文件名称
new_url = theme_url+link.split('/')[-1]
response = urllib2.urlopen(new_url)
soup = BeautifulSoup(response)
result = soup.select('.btn a')
down_url = result[1]['href'] # 文件链接
local = path+time.strftime('%Y%m%d%H%M%S',time.localtime(time.time()))+'.zip'
urllib.urlretrieve(down_url, local) # 远程保存函数
end = time.clock()
print u'模板抓取完成!'
print u'一共用时:',end-start,u'秒'
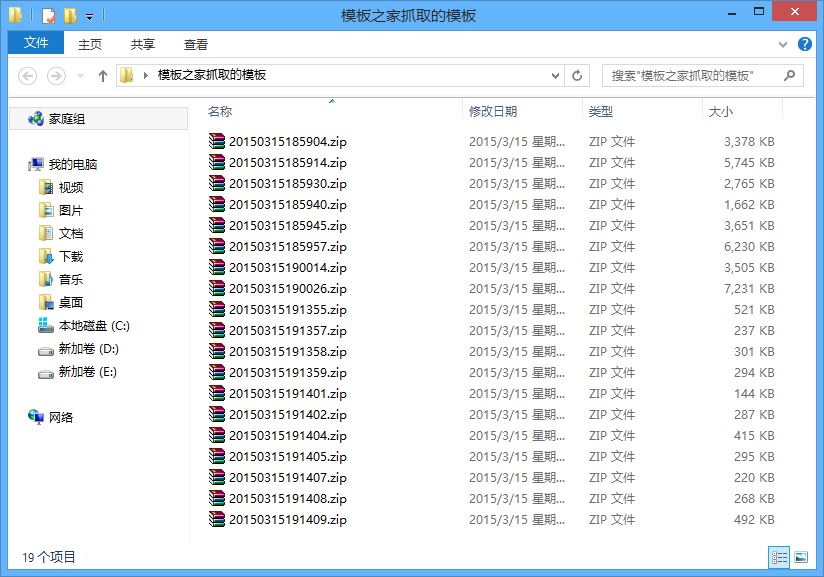
以上所述就是本文的全部内容了,希望大家能够喜欢。
Statement:
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn
Previous article:python实现从一组颜色中找出与给定颜色最接近颜色的方法Next article:python获取图片颜色信息的方法