


php生成 google map代码
<script><br /> var MyMar;<br /> function monitoring()<br /> {<br /> if(document.readyState =='complete')<br /> {<br /> window.location='?i='+query_get();<br /> }<br /> }<br /> <br /> function query_get()<br /> { <br /> var querystr = window.location.href.split("=");<br /> <br /> if(!Number(querystr[1]))<br /> {<br /> var value=0;<br /> }else{<br /> var value=Number(querystr[1]);<br /> }<br /> <br /> return Number(value)+1; <br /> }<br /> <br /> MyMar=setInterval('monitoring()',3000);<br /> </script>
正在检索:
/*===========================================================
= 版权协议:
= GPL ()
=------------------------------------------------------------
= 摘 要:URL收集函数 PHP5
= 版 本:1.0
=------------------------------------------------------------
= 开源stal 项目组
= 更新作者:jd808
= 最后日期:2008-4-18
============================================================*/
$file='sitemap.xml'; //GOOGLE 需要的文件 执行时则做首页的临时URL存储文件
$temp_file='temp.xml';//内页URL临时存储文件
$url="http://www.gyqpw.com/"; //要搜索的网站
$timea=time();//开始时间 用户无需理它 只管上面3个参数即可
if(!$_GET['i'])
{
file_put_contents($file,'');
file_put_contents($temp_file,'');
file_put_contents($file,con($url,$timea));
echo "<script><br /> window.location='?i=bak';<br /> </script>";
}else{
consts($_GET['i'],$timea,$file,$url);
}
function con($url,$timea) //控制
{
echo "<script><br /> document.getElementById('link').innerHTML='正在收集 ".$url." 的信息!';<br /> </script>";
$str = file_get_contents($url);
$collection_url=collection_url($str,$url);
$collection_url=array_flip($collection_url);
foreach($collection_url as $key=>$value)
{
if(count(explode($url,$key))==2)
{
$strurl.=$key."\n";
}
}
return $strurl;
}
function consts($i,$timea,$file,$urlys)
{
$str =file_get_contents($file); //读取页面数据并生产字符串
$url=explode("\n",$str);
$sum=count($url)-1;
if($i=='bak')
{
$i=0;
}
/*进度条*/
$wid=round($i/$sum*100,2)."%";
$div="
echo '<script><br /> document.getElementById("scroll").innerHTML="'.$div.'";<br /> </script>';
ob_flush();//释放缓存
flush(); //将不再缓存里的数据发送到浏览器去
/*进度条END */
for($j=$i;$j {
if(!$url[$j])
{
continue;
}
if(!detection_url($url[$j])) //检测URL是否合法
{
continue;
}
$timeb=time();//跟踪时间
if(($timeb-$timea)>=25)
{
memory($collection_url,$j); //存储数据
}
/* URL显示跟踪*/
echo "<script><br /> document.getElementById('link').innerHTML='".$url[$j]."';<br /> </script>";
ob_flush();//释放缓存
flush(); //将不再缓存里的数据发送到浏览器去
/* URL显示跟踪END*/
$urlstr=@file_get_contents($url[$j]);
$collection_url[]=collection_url($urlstr,$urlys);
$timec=time();//跟踪时间
if(($timec-$timea)>=25)
{
memory($collection_url,$j); //存储数据
}
if($j==$sum-1)
{
memorys(); //存储数据 主要是生成正式的xml
}
}
}
function collection_url($str,$url) //收集URL并返回一个数组(以页面为主)
{
preg_match_all('/
$urlexp=$matches[1];
for($j=0;$j
$urlexp[$j]=ltrim(str_replace("\r\n",'',$urlexp[$j]));
$urlexp[$j]=ltrim(str_replace("\n",'',$urlexp[$j]));
$urlexp[$j]=ltrim(str_replace("\r",'',$urlexp[$j]));
if($urlexp[$j]=='#')
{
continue;
}
if($urlexp[$j]=='/#')
{
continue;
}
if(!strchr($urlexp[$j],'http://'))
{//没有http://
$urlall[]=$url.$urlexp[$j];
echo $url.$urlexp[$j].'
';
print "<script>document.getElementById('logs').scrollTop = document.getElementById('logs').scrollHeight;</script>";
ob_flush();//释放缓存
flush(); //将不再缓存里的数据发送到浏览器去
}else{
if(count(explode($url,$urlexp[$j]))==2)
{
$urlall[]=$urlexp[$j];
echo $urlexp[$j].'
';
print "<script>document.getElementById('logs').scrollTop = document.getElementById('logs').scrollHeight;</script>";
ob_flush();//释放缓存
flush(); //将不再缓存里的数据发送到浏览器去
}else{
unset($urlexp[$j]);
}
}
}
return $urlall; //返回本页面搜索所得到的数组
}
function memory($collection_url,$i)
{
global $temp_file;
if(is_array($collection_url))
{
for($h=0;$h
for($l=0;$l
$strts.=$collection_url[$h][$l]."\n";
}
}
$wstr=file_get_contents($temp_file);
file_put_contents($temp_file,$wstr.$strts);
if($i==0)
{
$i=2;
}
$k=$i-1;
echo "<script><br /> window.location='?i=".$k."';<br /> </script>";
exit;
}
}
function memorys() //主要是生成正式的xml
{
global $temp_file,$file;
$file_arr=array_flip(file($file));
$temp_file_arr=array_flip(file($temp_file));
$xmla=''."\r\n".'
$xmlc="\r\n
foreach($file_arr as $keya=>$valuea)
{
$keya=ltrim(str_replace("\r\n",'',$keya));
$keya=ltrim(str_replace("\n",'',$keya));
$keya=ltrim(str_replace("\r",'',$keya));
$xml.='
}
foreach($temp_file_arr as $keyb=>$valueb)
{
$keyb=ltrim(str_replace("\r\n",'',$keyb));
$keyb=ltrim(str_replace("\n",'',$keyb));
$keyb=ltrim(str_replace("\r",'',$keyb));
$xml.='
}
$strts=$xmla.$xml.$xmlc;
file_put_contents($file,$strts);
echo "<script><br /> clearInterval(MyMar);<br /> document.getElementById('link').innerHTML='URL已经收集完成!';<br /> document.getElementById('all_a').innerHTML='<b>XML生成已完成!';<br /> </script>";
}
function detection_url($url)
{
if(strrchr($url,'='))
{
return true;
}
if(substr($url,strlen($url)-1,1)=='/')
{
return true;
}
$postfix= strrchr($url,'.');
switch ($postfix)
{
case ".php":
return true;
break;
case ".html":
return true;
break;
case ".htm":
return true;
break;
case ".asp":
return true;
break;
case ".aspx":
return true;
break;
case ".shtml":
return true;
break;
}
return false;
}
?>

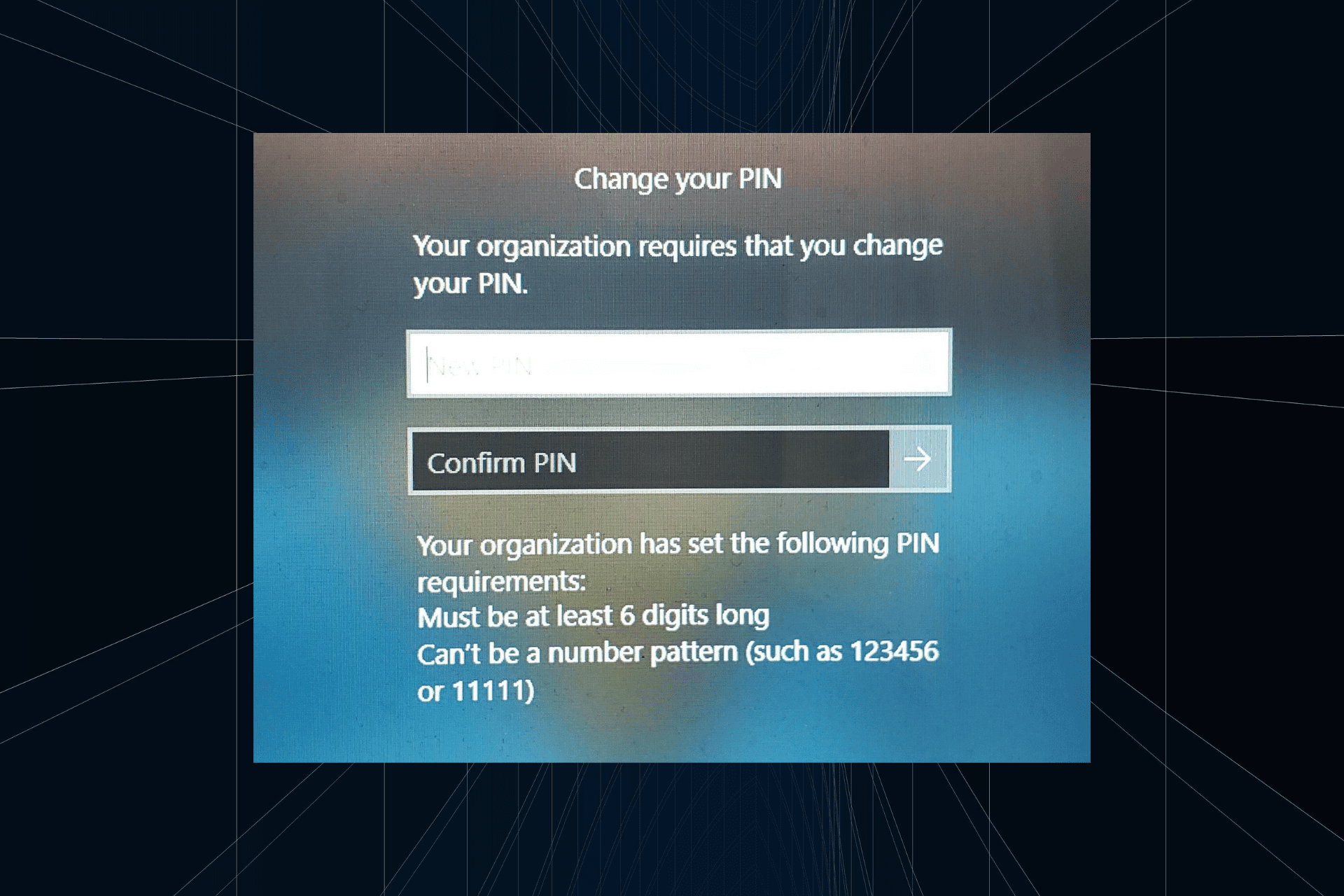 解决方法:您的组织要求您更改 PIN 码Oct 04, 2023 pm 05:45 PM
解决方法:您的组织要求您更改 PIN 码Oct 04, 2023 pm 05:45 PM“你的组织要求你更改PIN消息”将显示在登录屏幕上。当在使用基于组织的帐户设置的电脑上达到PIN过期限制时,就会发生这种情况,在该电脑上,他们可以控制个人设备。但是,如果您使用个人帐户设置了Windows,则理想情况下不应显示错误消息。虽然情况并非总是如此。大多数遇到错误的用户使用个人帐户报告。为什么我的组织要求我在Windows11上更改我的PIN?可能是您的帐户与组织相关联,您的主要方法应该是验证这一点。联系域管理员会有所帮助!此外,配置错误的本地策略设置或不正确的注册表项也可能导致错误。即
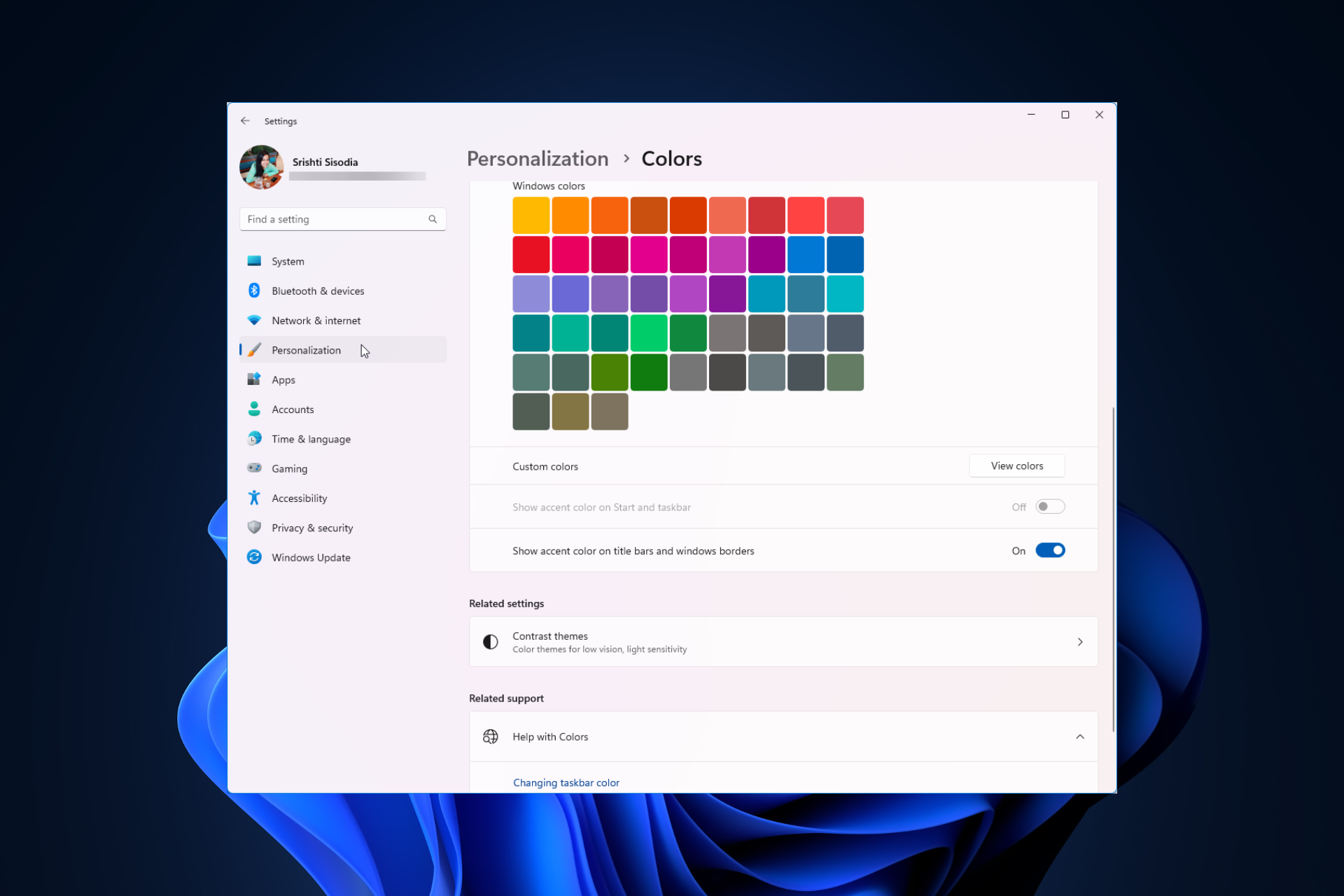 Windows 11 上调整窗口边框设置的方法:更改颜色和大小Sep 22, 2023 am 11:37 AM
Windows 11 上调整窗口边框设置的方法:更改颜色和大小Sep 22, 2023 am 11:37 AMWindows11将清新优雅的设计带到了最前沿;现代界面允许您个性化和更改最精细的细节,例如窗口边框。在本指南中,我们将讨论分步说明,以帮助您在Windows操作系统中创建反映您的风格的环境。如何更改窗口边框设置?按+打开“设置”应用。WindowsI转到个性化,然后单击颜色设置。颜色更改窗口边框设置窗口11“宽度=”643“高度=”500“>找到在标题栏和窗口边框上显示强调色选项,然后切换它旁边的开关。若要在“开始”菜单和任务栏上显示主题色,请打开“在开始”菜单和任务栏上显示主题
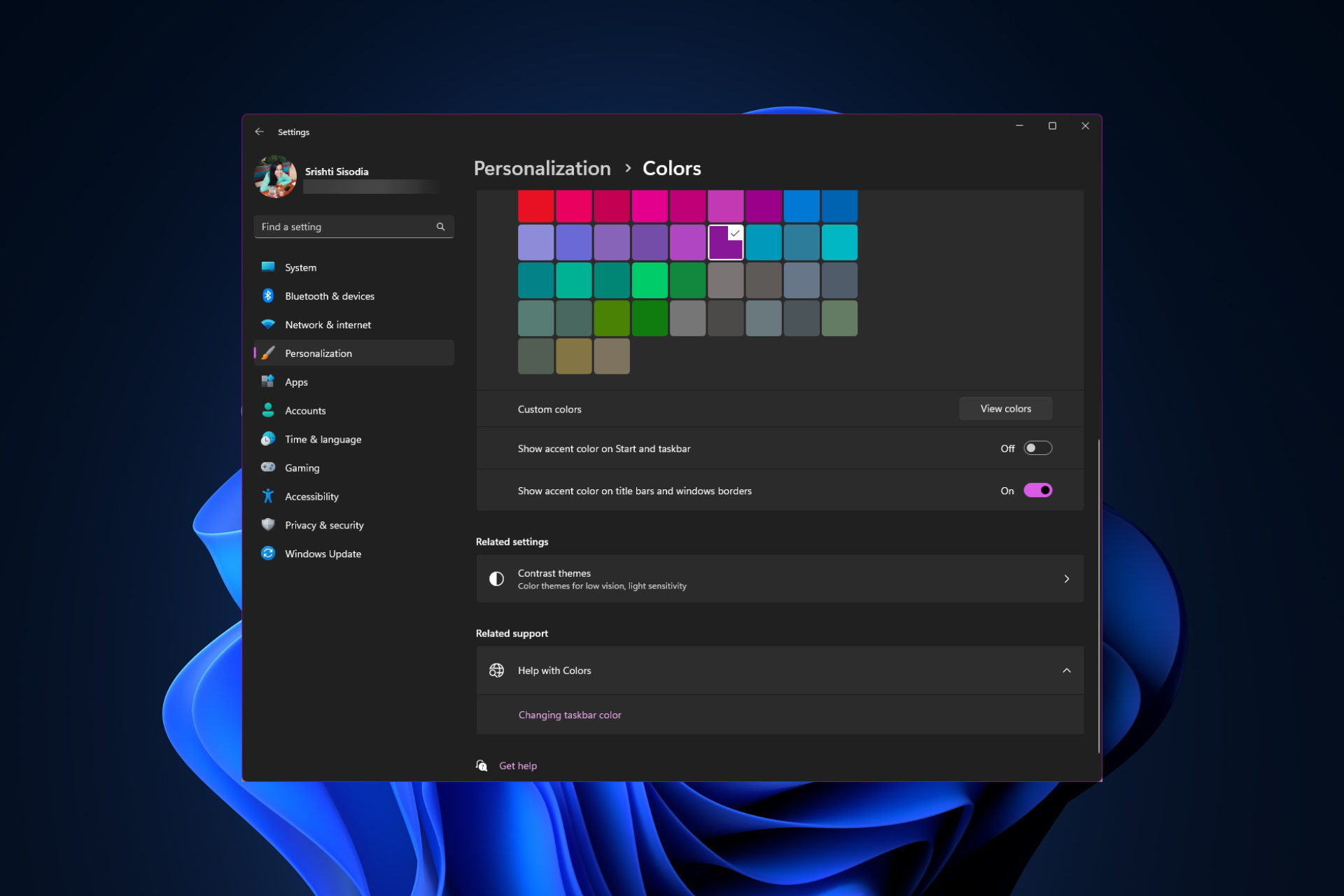 如何在 Windows 11 上更改标题栏颜色?Sep 14, 2023 pm 03:33 PM
如何在 Windows 11 上更改标题栏颜色?Sep 14, 2023 pm 03:33 PM默认情况下,Windows11上的标题栏颜色取决于您选择的深色/浅色主题。但是,您可以将其更改为所需的任何颜色。在本指南中,我们将讨论三种方法的分步说明,以更改它并个性化您的桌面体验,使其具有视觉吸引力。是否可以更改活动和非活动窗口的标题栏颜色?是的,您可以使用“设置”应用更改活动窗口的标题栏颜色,也可以使用注册表编辑器更改非活动窗口的标题栏颜色。若要了解这些步骤,请转到下一部分。如何在Windows11中更改标题栏的颜色?1.使用“设置”应用按+打开设置窗口。WindowsI前往“个性化”,然
 OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题Jul 16, 2023 pm 03:29 PM您是否在Windows安装程序页面上看到“出现问题”以及“OOBELANGUAGE”语句?Windows的安装有时会因此类错误而停止。OOBE表示开箱即用的体验。正如错误提示所表示的那样,这是与OOBE语言选择相关的问题。没有什么可担心的,你可以通过OOBE屏幕本身的漂亮注册表编辑来解决这个问题。快速修复–1.单击OOBE应用底部的“重试”按钮。这将继续进行该过程,而不会再打嗝。2.使用电源按钮强制关闭系统。系统重新启动后,OOBE应继续。3.断开系统与互联网的连接。在脱机模式下完成OOBE的所
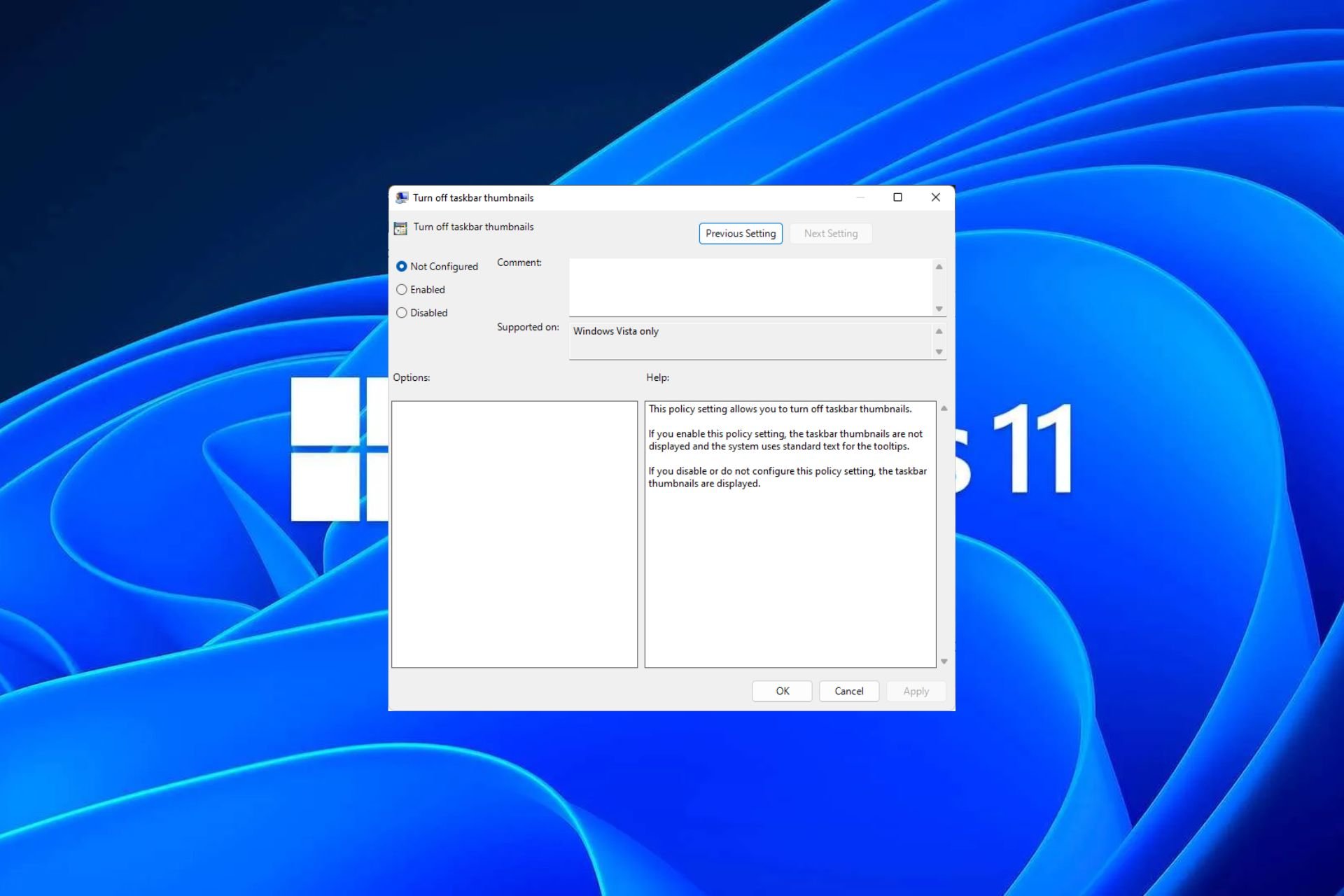 Windows 11 上启用或禁用任务栏缩略图预览的方法Sep 15, 2023 pm 03:57 PM
Windows 11 上启用或禁用任务栏缩略图预览的方法Sep 15, 2023 pm 03:57 PM任务栏缩略图可能很有趣,但它们也可能分散注意力或烦人。考虑到您将鼠标悬停在该区域的频率,您可能无意中关闭了重要窗口几次。另一个缺点是它使用更多的系统资源,因此,如果您一直在寻找一种提高资源效率的方法,我们将向您展示如何禁用它。不过,如果您的硬件规格可以处理它并且您喜欢预览版,则可以启用它。如何在Windows11中启用任务栏缩略图预览?1.使用“设置”应用点击键并单击设置。Windows单击系统,然后选择关于。点击高级系统设置。导航到“高级”选项卡,然后选择“性能”下的“设置”。在“视觉效果”选
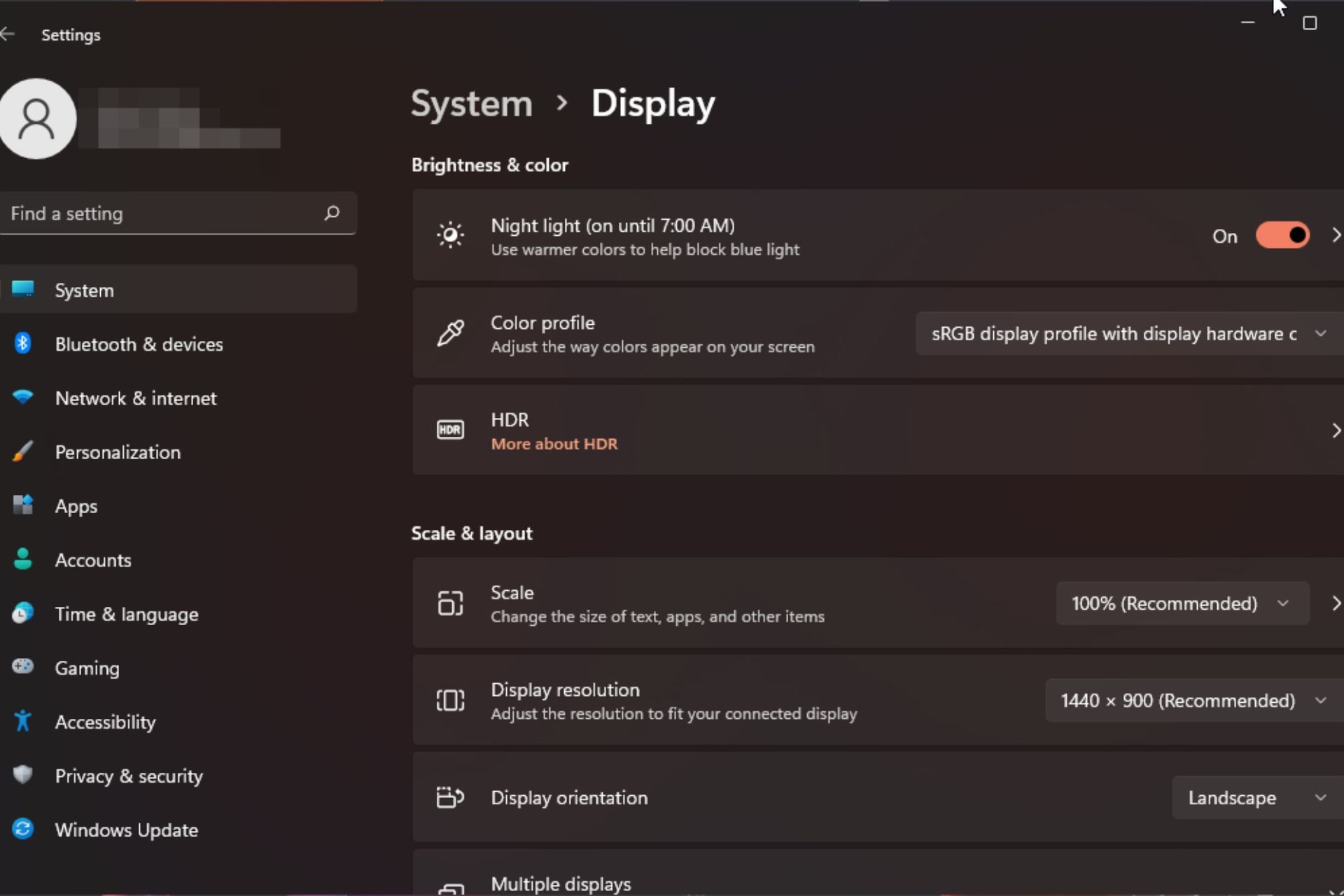 Windows 11 上的显示缩放比例调整指南Sep 19, 2023 pm 06:45 PM
Windows 11 上的显示缩放比例调整指南Sep 19, 2023 pm 06:45 PM在Windows11上的显示缩放方面,我们都有不同的偏好。有些人喜欢大图标,有些人喜欢小图标。但是,我们都同意拥有正确的缩放比例很重要。字体缩放不良或图像过度缩放可能是工作时真正的生产力杀手,因此您需要知道如何对其进行自定义以充分利用系统功能。自定义缩放的优点:对于难以阅读屏幕上的文本的人来说,这是一个有用的功能。它可以帮助您一次在屏幕上查看更多内容。您可以创建仅适用于某些监视器和应用程序的自定义扩展配置文件。可以帮助提高低端硬件的性能。它使您可以更好地控制屏幕上的内容。如何在Windows11
 10种在 Windows 11 上调整亮度的方法Dec 18, 2023 pm 02:21 PM
10种在 Windows 11 上调整亮度的方法Dec 18, 2023 pm 02:21 PM屏幕亮度是使用现代计算设备不可或缺的一部分,尤其是当您长时间注视屏幕时。它可以帮助您减轻眼睛疲劳,提高易读性,并轻松有效地查看内容。但是,根据您的设置,有时很难管理亮度,尤其是在具有新UI更改的Windows11上。如果您在调整亮度时遇到问题,以下是在Windows11上管理亮度的所有方法。如何在Windows11上更改亮度[10种方式解释]单显示器用户可以使用以下方法在Windows11上调整亮度。这包括使用单个显示器的台式机系统以及笔记本电脑。让我们开始吧。方法1:使用操作中心操作中心是访问
 如何修复Windows服务器中的激活错误代码0xc004f069Jul 22, 2023 am 09:49 AM
如何修复Windows服务器中的激活错误代码0xc004f069Jul 22, 2023 am 09:49 AMWindows上的激活过程有时会突然转向显示包含此错误代码0xc004f069的错误消息。虽然激活过程已经联机,但一些运行WindowsServer的旧系统可能会遇到此问题。通过这些初步检查,如果这些检查不能帮助您激活系统,请跳转到主要解决方案以解决问题。解决方法–关闭错误消息和激活窗口。然后,重新启动计算机。再次从头开始重试Windows激活过程。修复1–从终端激活从cmd终端激活WindowsServerEdition系统。阶段–1检查Windows服务器版本您必须检查您使用的是哪种类型的W


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Atom editor mac version download
The most popular open source editor

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 English version
Recommended: Win version, supports code prompts!

