

知方可补不足~SQL中的count命令的一些优化措施(百万以上数据明显)

SQL中对于求表记录总数的有count这个聚合命令,这个命令给我们感觉就是快,比一般的查询要快,但是,当你的数据表记录比较多时,如百万条,千万条时,对于count来说,就不是那么快了,我们需要掌握一些技巧,来优化这个count。 有人说: select count(1)
SQL中对于求表记录总数的有count这个聚合命令,这个命令给我们感觉就是快,比一般的查询要快,但是,当你的数据表记录比较多时,如百万条,千万条时,对于count来说,就不是那么快了,我们需要掌握一些技巧,来优化这个count。
有人说:
select count(1) from table
select count(primarykey) from table
比较快,一定不要用
select count(*) from table
可我要说的是,count(*)更快一些,为什么呢,count(*)是什么意思?事实上,它真正的含义是找一个占用空间最小的索引字段,然后对它进行记数,不要一看到*就认为“大”,在count命令中,它指的是“任意一个“。
对于一个大表来说,如果你的字段有bit类型,,如性别字段,表示真假关系的字段,我们需要为它加上索引,加上之后,我们的count速度就提交几十倍,真的,呵呵
首先为我们的bit类型字段加索引IsSync添加聚集索引
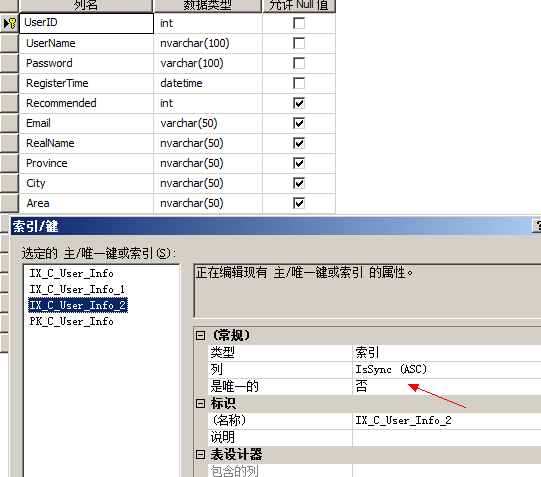
如果数据表太大,我们需要在命令行中去运行

 How Do I Drop or Modify an Existing View in MySQL?May 16, 2025 am 12:11 AM
How Do I Drop or Modify an Existing View in MySQL?May 16, 2025 am 12:11 AMTodropaviewinMySQL,use"DROPVIEWIFEXISTSview_name;"andtomodifyaview,use"CREATEORREPLACEVIEWview_nameASSELECT...".Whendroppingaview,considerdependenciesanduse"SHOWCREATEVIEWview_name;"tounderstanditsstructure.Whenmodifying
 MySQL Views: Which design patterns can I use with it?May 16, 2025 am 12:10 AM
MySQL Views: Which design patterns can I use with it?May 16, 2025 am 12:10 AMMySQLViewscaneffectivelyutilizedesignpatternslikeAdapter,Decorator,Factory,andObserver.1)AdapterPatternadaptsdatafromdifferenttablesintoaunifiedview.2)DecoratorPatternenhancesdatawithcalculatedfields.3)FactoryPatterncreatesviewsthatproducedifferentda
 What Are the Advantages of Using Views in MySQL?May 16, 2025 am 12:09 AM
What Are the Advantages of Using Views in MySQL?May 16, 2025 am 12:09 AMViewsinMySQLarebeneficialforsimplifyingcomplexqueries,enhancingsecurity,ensuringdataconsistency,andoptimizingperformance.1)Theysimplifycomplexqueriesbyencapsulatingthemintoreusableviews.2)Viewsenhancesecuritybycontrollingdataaccess.3)Theyensuredataco
 How Can I Create a Simple View in MySQL?May 16, 2025 am 12:08 AM
How Can I Create a Simple View in MySQL?May 16, 2025 am 12:08 AMTocreateasimpleviewinMySQL,usetheCREATEVIEWstatement.1)DefinetheviewwithCREATEVIEWview_nameAS.2)SpecifytheSELECTstatementtoretrievedesireddata.3)Usetheviewlikeatableforqueries.Viewssimplifydataaccessandenhancesecurity,butconsiderperformance,updatabil
 MySQL Create User Statement: Examples and Common ErrorsMay 16, 2025 am 12:04 AM
MySQL Create User Statement: Examples and Common ErrorsMay 16, 2025 am 12:04 AMTocreateusersinMySQL,usetheCREATEUSERstatement.1)Foralocaluser:CREATEUSER'localuser'@'localhost'IDENTIFIEDBY'securepassword';2)Foraremoteuser:CREATEUSER'remoteuser'@'%'IDENTIFIEDBY'strongpassword';3)Forauserwithaspecifichost:CREATEUSER'specificuser'@
 What Are the Limitations of Using Views in MySQL?May 14, 2025 am 12:10 AM
What Are the Limitations of Using Views in MySQL?May 14, 2025 am 12:10 AMMySQLviewshavelimitations:1)Theydon'tsupportallSQLoperations,restrictingdatamanipulationthroughviewswithjoinsorsubqueries.2)Theycanimpactperformance,especiallywithcomplexqueriesorlargedatasets.3)Viewsdon'tstoredata,potentiallyleadingtooutdatedinforma
 Securing Your MySQL Database: Adding Users and Granting PrivilegesMay 14, 2025 am 12:09 AM
Securing Your MySQL Database: Adding Users and Granting PrivilegesMay 14, 2025 am 12:09 AMProperusermanagementinMySQLiscrucialforenhancingsecurityandensuringefficientdatabaseoperation.1)UseCREATEUSERtoaddusers,specifyingconnectionsourcewith@'localhost'or@'%'.2)GrantspecificprivilegeswithGRANT,usingleastprivilegeprincipletominimizerisks.3)
 What Factors Influence the Number of Triggers I Can Use in MySQL?May 14, 2025 am 12:08 AM
What Factors Influence the Number of Triggers I Can Use in MySQL?May 14, 2025 am 12:08 AMMySQLdoesn'timposeahardlimitontriggers,butpracticalfactorsdeterminetheireffectiveuse:1)Serverconfigurationimpactstriggermanagement;2)Complextriggersincreasesystemload;3)Largertablesslowtriggerperformance;4)Highconcurrencycancausetriggercontention;5)M


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

Dreamweaver Mac version
Visual web development tools

SublimeText3 Chinese version
Chinese version, very easy to use

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 English version
Recommended: Win version, supports code prompts!

