



mapreduce 与mysql 交互 MapReduce与MySQL交互 分类:?hadoop之旅 2012-08-29 16:12 ? 377人阅读 ? 评论(0) ? 收藏 ? 举报 mapreducemysql数据库hadoopstringjdbc? 目录(?) [+] ? MapReduce技术推出后,曾遭到关系数据库研究者的挑剔和批评,认为MapReduce不
mapreduce 与mysql 交互MapReduce与MySQL交互
分类:?hadoop之旅2012-08-29 16:12?377人阅读?评论(0)?收藏?举报 mapreducemysql数据库hadoopstringjdbc ?目录(?)[+]
?MapReduce技术推出后,曾遭到关系数据库研究者的挑剔和批评,认为MapReduce不具备有类似于关系数据库中的结构化数据存储和处理能力。为此,Google和MapReduce社区进行了很多努力。一方面,他们设计了类似于关系数据中结构化数据表的技术(Google的BigTable,Hadoop的HBase)提供一些粗粒度的结构化数据存储和处理能力;另一方面,为了增强与关系数据库的集成能力,Hadoop MapReduce提供了相应的访问关系数据库库的编程接口。
MapReduce与MySQL交互的整体架构如下图所示。
?

图2-1整个环境的架构
具体到MapReduce框架读/写数据库,有2个主要的程序分别是?DBInputFormat和DBOutputFormat,DBInputFormat 对应的是SQL语句select,而DBOutputFormat 对应的是?Inster/update,使用DBInputFormat和DBOutputForma时候需要实现InputFormat这个抽象类,这个抽象类含有getSplits()和createRecordReader()抽象方法,在DBInputFormat类中由 protected String getCountQuery() 方法传入结果集的个数,getSplits()方法再确定输入的切分原则,利用SQL中的 LIMIT 和 OFFSET 进行切分获得数据集的范围 ,请参考DBInputFormat源码中public InputSplit[] getSplits(JobConf job, int chunks) throws IOException的方法,在DBInputFormat源码中createRecordReader()则可以按一定格式读取相应数据。
??????1)建立关系数据库连接
- DBConfiguration:提供数据库配置和创建连接的接口。
????? DBConfiguration类中提供了一个静态方法创建数据库连接:
?
public static void configureDB(Job?job,String?driverClass,String?dbUrl,String?userName,String?Password)
?
????? 其中,job为当前准备执行的作业,driverClasss为数据库厂商提供的访问其数据库的驱动程序,dbUrl为运行数据库的主机的地址,userName和password分别为数据库提供访问地用户名和相应的访问密码。
??????2)相应的从关系数据库查询和读取数据的接口
- DBInputFormat:提供从数据库读取数据的格式。
- DBRecordReader:提供读取数据记录的接口。
3)相应的向关系数据库直接输出结果的编程接口
- DBOutputFormat:提供向数据库输出数据的格式。
- DBRecordWrite:提供数据库写入数据记录的接口。
数据库连接完成后,即可完成从MapReduce程序向关系数据库写入数据的操作。为了告知数据库将写入哪个表中的哪些字段,DBOutputFormat中提供了一个静态方法来指定需要写入的数据表和字段:
?
public static void setOutput(Job job,String tableName,String ... fieldName)
?
????? 其中,tableName指定即将写入的数据表,后续参数将指定哪些字段数据将写入该表。
1.1 从数据库中输入数据
??????虽然Hadoop允许从数据库中直接读取数据记录作为MapReduce的输入,但处理效率较低,而且大量频繁地从MapReduce程序中查询和读取关系数据库可能会大大增加数据库的访问负载,因此DBInputFormat仅适合读取小量数据记录的计算和应用,不适合数据仓库联机数据分析大量数据的读取处理。
????? 读取大量数据记录一个更好的解决办法是:用数据库中的Dump工具将大量待分析数据输出为文本数据文件,并上载到HDFS中进行处理。
?
??????1)首先创建要读入的数据
- Windows环境
首先创建数据库"school",使用下面命令进行:
?
create database school;
?

????? 然后通过以下几句话,把我们事先准备好的sql语句(student.sql事先放到了D盘目录)导入到刚创建的"school"数据库中。用到的命令如下:
?
use school;
source d:\student.sql
?
????? "student.sql"中的内容如下所示:
?
DROP TABLE IF EXISTS `school`.`student`;
?
CREATE TABLE `school`.`student` (
`id` int(11) NOT NULL default '0',
`name` varchar(20) default NULL,
`sex` varchar(10) default NULL,
`age` int(10) default NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
?
INSERT INTO `student` VALUES ('201201', '张三', '男', '21');
INSERT INTO `student` VALUES ('201202', '李四', '男', '22');
INSERT INTO `student` VALUES ('201203', '王五', '女', '20');
INSERT INTO `student` VALUES ('201204', '赵六', '男', '21');
INSERT INTO `student` VALUES ('201205', '小红', '女', '19');
INSERT INTO `student` VALUES ('201206', '小明', '男', '22');
?
????? 执行结果如下所示:
?

?
????? 查询刚才创建的数据库表"student"的内容。
?

?
????? 结果发现显示是乱码,记得我当时是设置的UTF-8,怎么就出现乱码了呢?其实我们使用的操作系统的系统为中文,且它的默认编码是gbk,而MySQL的编码有两种,它们分别是:
【client】:客户端的字符集。客户端默认字符集。当客户端向服务器发送请求时,请求以该字符集进行编码。
【mysqld】:服务器字符集,默认情况下所采用的。
?
????? 找到安装MySQL目录,比如我们的安装目录为:
?
E:\HadoopWorkPlat\MySQL Server 5.5
?
????? 从中找到"my.ini"配置文件,最终发现my.ini里的2个character_set把client改成gbk,把server改成utf8就可以了。
??? 【client】端:
?
[client]
port=3306
[mysql]
default-character-set=gbk
?
??? 【mysqld】端:
?
[mysqld]
# The default character set that will be used when a new schema or table is
# created and no character set is defined
character-set-server=utf8
?
????? 按照上面修改完之后,重启MySQL服务。
?

?
????? 此时在Windows下面的数据库表已经准备完成了。
?
- Linux环境
首先通过"FlashFXP"把我们刚才的"student.sql"上传到"/home/hadoop"目录下面,然后按照上面的语句创建"school"数据库。
?

????? 查看我们上传的"student.sql"内容:
?

??? ? 创建"school"数据库,并导入"student.sql"语句。
?

?
????? 显示数据库"school"中的表"student"信息。
?

??? ?显示表"student"中的内容。
?

?
????? 到此为止在"Windows"和"Linux"两种环境下面都创建了表"student"表,并初始化了值。下面就开始通过MapReduce读取MySQL库中表"student"的信息。
??????2)使MySQL能远程连接
????? MySQL默认是允许别的机器进行远程访问地,为了使Hadoop集群能访问MySQL数据库,所以进行下面操作。
- 用MySQL用户"root"登录。
?
mysql -u root -p
?
- 使用下面语句进行授权,赋予任何主机访问数据的权限。
?
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
?
- 刷新,使之立即生效。
?
FLUSH PRIVILEGES;
?
????? 执行结果如下图。
????? Windows下面:
?

????? Linux下面:
?

???? ?到目前为止,如果连接Win7上面的MySQL数据库还不行,大家还应该记得前面在Linux下面关掉了防火墙,但是我们在Win7下对防火墙并没有做任何处理,如果不对防火墙做处理,即使执行了上面的远程授权,仍然不能连接。下面是设置Win7上面的防火墙,使远程机器能通过3306端口访问MySQL数据库。
??????解决方法:只要在'入站规则'上建立一个3306端口即可。
执行顺序:控制面板à管理工具à高级安全的Windows防火墙à入站规则
然后新建规则à选择'端口'à在'特定本地端口'上输入一个'3306'?à选择'允许连接'=>选择'域'、'专用'、'公用'=>给个名称,如:MySqlInput
?

??????3)对JDBC的Jar包处理
???? ?因为程序虽然用Eclipse编译运行但最终要提交到Hadoop集群上,所以JDBC的jar必须放到Hadoop集群中。有两种方式:
????? (1)在每个节点下的${HADOOP_HOME}/lib下添加该包,重启集群,一般是比较原始的方法。
????? 我们的Hadoop安装包在"/usr/hadoop",所以把Jar放到"/usr/hadoop/lib"下面,然后重启,记得是Hadoop集群中所有的节点都要放,因为执行分布式是程序是在每个节点本地机器上进行。
???? ?(2)在Hadoop集群的分布式文件系统中创建"/lib"文件夹,并把我们的的JDBC的jar包上传上去,然后在主程序添加如下语句,就能保证Hadoop集群中所有的节点都能使用这个jar包。因为这个jar包放在了HDFS上,而不是本地系统,这个要理解清楚。
?
DistributedCache.addFileToClassPath(new Path("/lib/mysql-connector-java-5.1.18-bin.jar"), conf);
?
?? ?? 我们用的JDBC的jar如下所示:
?
mysql-connector-java-5.1.18-bin.jar
?
???? ?通过Eclipse下面的DFS Locations进行创建"/lib"文件夹,并上传JDBC的jar包。执行结果如下:

??????备注:我们这里采用了第二种方式。
???? ?4)源程序代码如下所示
?
package?com.hebut.mr;
?
import?java.io.IOException;
import?java.io.DataInput;
import?java.io.DataOutput;
import?java.sql.Connection;
import?java.sql.DriverManager;
import?java.sql.PreparedStatement;
import?java.sql.ResultSet;
import?java.sql.SQLException;
?
import?org.apache.hadoop.filecache.DistributedCache;
import?org.apache.hadoop.fs.Path;
import?org.apache.hadoop.io.LongWritable;
import?org.apache.hadoop.io.Text;
import?org.apache.hadoop.io.Writable;
import?org.apache.hadoop.mapred.JobClient;
import?org.apache.hadoop.mapred.JobConf;
import?org.apache.hadoop.mapred.MapReduceBase;
import?org.apache.hadoop.mapred.Mapper;
import?org.apache.hadoop.mapred.OutputCollector;
import?org.apache.hadoop.mapred.FileOutputFormat;
import?org.apache.hadoop.mapred.Reporter;
import?org.apache.hadoop.mapred.lib.IdentityReducer;
import?org.apache.hadoop.mapred.lib.db.DBWritable;
import?org.apache.hadoop.mapred.lib.db.DBInputFormat;
import?org.apache.hadoop.mapred.lib.db.DBConfiguration;
?
public?class?ReadDB {
?
????public?static?class?Map?extends?MapReduceBase?implements
??????????? Mapper
{ ?
????????//?实现map函数
????????public?void?map(LongWritable key, StudentRecord value,
??????? OutputCollector
collector, Reporter reporter) ????????????????throws?IOException {
??????????? collector.collect(new?LongWritable(value.id),
????????????????????new?Text(value.toString()));
??????? }
?
??? }
?
????public?static?class?StudentRecord?implements?Writable, DBWritable {
????????public?int?id;
????????public?String?name;
????????public?String?sex;
????????public?int?age;
?
????????@Override
????????public?void?readFields(DataInput in)?throws?IOException {
????????????this.id?= in.readInt();
????????????this.name?= Text.readString(in);
????????????this.sex?= Text.readString(in);
????????????this.age?= in.readInt();
??????? }
?
????????@Override
????????public?void?write(DataOutput out)?throws?IOException {
??????????? out.writeInt(this.id);
??????????? Text.writeString(out,?this.name);
??????????? Text.writeString(out,?this.sex);
??????????? out.writeInt(this.age);
??????? }
?
????????@Override
????????public?void?readFields(ResultSet result)?throws?SQLException {
????????????this.id?= result.getInt(1);
????????????this.name?= result.getString(2);
????????????this.sex?= result.getString(3);
????????????this.age?= result.getInt(4);
??????? }
?
????????@Override
????????public?void?write(PreparedStatement stmt)?throws?SQLException {
??????????? stmt.setInt(1,?this.id);
??????????? stmt.setString(2,?this.name);
??????????? stmt.setString(3,?this.sex);
??????????? stmt.setInt(4,?this.age);
??????? }
?
????????@Override
????????public?String toString() {
????????????return?new?String("学号:"?+?this.id?+?"_姓名:"?+?this.name
??????????????????? +?"_性别:"+?this.sex?+?"_年龄:"?+?this.age);
??????? }
??? }
?
????public?static?void?main(String[] args)?throws?Exception {
?
??????? JobConf conf =?new?JobConf(ReadDB.class);
?
????????//?这句话很关键
??????? conf.set("mapred.job.tracker",?"192.168.1.2:9001");
?
??????? //?非常重要,值得关注
??????? DistributedCache.addFileToClassPath(new?Path(
?????????"/lib/mysql-connector-java-5.1.18-bin.jar"), conf);
?
????????//?设置输入类型
??????? conf.setInputFormat(DBInputFormat.class);
?
????????//?设置输出类型
??????? conf.setOutputKeyClass(LongWritable.class);
??????? conf.setOutputValueClass(Text.class);
?
????????//?设置Map和Reduce类
??????? conf.setMapperClass(Map.class);
??????? conf.setReducerClass(IdentityReducer.class);
?
????????//?设置输出目录
??????? FileOutputFormat.setOutputPath(conf,?new?Path("rdb_out"));
?
????????//?建立数据库连接
??????? DBConfiguration.configureDB(conf,?"com.mysql.jdbc.Driver",
????????????"jdbc:mysql://192.168.1.24:3306/school",?"root",?"hadoop");
?
????????//?读取"student"表中的数据
??????? String[] fields = {?"id",?"name",?"sex",?"age"?};
??????? DBInputFormat.setInput(conf, StudentRecord.class,?"student",?null,"id", fields);
?
??????? JobClient.runJob(conf);
??? }
}
?
???? ?备注:由于Hadoop1.0.0新的API对关系型数据库暂不支持,只能用旧的API进行,所以下面的"向数据库中输出数据"也是如此。
?
???? ?5)运行结果如下所示
???? ?经过上面的设置后,已经通过连接Win7和Linux上的MySQL数据库,执行结果都一样。唯独变得就是代码中"DBConfiguration.configureDB"中MySQL数据库所在机器的IP地址。
?

?
1.2 向数据库中输出数据
???? ?基于数据仓库的数据分析和挖掘输出结果的数据量一般不会太大,因而可能适合于直接向数据库写入。我们这里尝试与"WordCount"程序相结合,把单词统计的结果存入到关系型数据库中。
???? ?1)创建写入的数据库表
??? ? 我们还使用刚才创建的数据库"school",只是在里添加一个新的表"wordcount",还是使用下面语句执行:
?
use school;
source?sql脚本全路径
?
??? ? 下面是要创建的"wordcount"表的sql脚本。
?
DROP TABLE IF EXISTS `school`.`wordcount`;
?
CREATE TABLE `school`.`wordcount` (
`id` int(11) NOT NULL auto_increment,
`word` varchar(20) default NULL,
`number` int(11) default NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
?
???? ?执行效果如下所示:
- Windows环境

- Linux环境

?
??????2)程序源代码如下所示
?
package?com.hebut.mr;
?
import?java.io.IOException;
import?java.io.DataInput;
import?java.io.DataOutput;
import?java.sql.PreparedStatement;
import?java.sql.ResultSet;
import?java.sql.SQLException;
import?java.util.Iterator;
import?java.util.StringTokenizer;
?
import?org.apache.hadoop.filecache.DistributedCache;
import?org.apache.hadoop.fs.Path;
import?org.apache.hadoop.io.IntWritable;
import?org.apache.hadoop.io.Text;
import?org.apache.hadoop.io.Writable;
import?org.apache.hadoop.mapred.FileInputFormat;
import?org.apache.hadoop.mapred.JobClient;
import?org.apache.hadoop.mapred.JobConf;
import?org.apache.hadoop.mapred.MapReduceBase;
import?org.apache.hadoop.mapred.Mapper;
import?org.apache.hadoop.mapred.OutputCollector;
import?org.apache.hadoop.mapred.Reducer;
import?org.apache.hadoop.mapred.Reporter;
import?org.apache.hadoop.mapred.TextInputFormat;
import?org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import?org.apache.hadoop.mapred.lib.db.DBWritable;
import?org.apache.hadoop.mapred.lib.db.DBConfiguration;
?
public?class?WriteDB {
????// Map处理过程
????public?static?class?Map?extends?MapReduceBase?implements
??????????? Mapper
?
????????private?final?static?IntWritable?one?=?new?IntWritable(1);
????????private?Text?word?=?new?Text();
?
????????@Override
????????public?void?map(Object key, Text value,
??????????? OutputCollector
output, Reporter reporter) ????????????????throws?IOException {
??????????? String line = value.toString();
??????????? StringTokenizer tokenizer =?new?StringTokenizer(line);
????????????while?(tokenizer.hasMoreTokens()) {
????????????????word.set(tokenizer.nextToken());
??????????????? output.collect(word,?one);
??????????? }
??????? }
??? }
?
????// Combine处理过程
????public?static?class?Combine?extends?MapReduceBase?implements
??????????? Reducer
{ ?
????????@Override
????????public?void?reduce(Text key, Iterator
values, ??????????? OutputCollector
output, Reporter reporter) ????????????????throws?IOException {
????????????int?sum = 0;
????????????while?(values.hasNext()) {
??????????????? sum += values.next().get();
??????????? }
??????????? output.collect(key,?new?IntWritable(sum));
??????? }
??? }
?
????// Reduce处理过程
????public?static?class?Reduce?extends?MapReduceBase?implements
??????????? Reducer
{ ?
????????@Override
????????public?void?reduce(Text key, Iterator
values, ??????????? OutputCollector
collector, Reporter reporter) ????????????????throws?IOException {
?
????????????int?sum = 0;
????????????while?(values.hasNext()) {
??????????????? sum += values.next().get();
??????????? }
?
??????????? WordRecord wordcount =?new?WordRecord();
??????????? wordcount.word?= key.toString();
??????????? wordcount.number?= sum;
?
??????????? collector.collect(wordcount,?new?Text());
??????? }
??? }
?
????public?static?class?WordRecord?implements?Writable, DBWritable {
????????public?String?word;
????????public?int?number;
?
????????@Override
????????public?void?readFields(DataInput in)?throws?IOException {
????????????this.word?= Text.readString(in);
????????????this.number?= in.readInt();
??????? }
?
????????@Override
????????public?void?write(DataOutput out)?throws?IOException {
??????????? Text.writeString(out,?this.word);
??????????? out.writeInt(this.number);
??????? }
?
????????@Override
????????public?void?readFields(ResultSet result)?throws?SQLException {
????????????this.word?= result.getString(1);
????????????this.number?= result.getInt(2);
??????? }
?
????????@Override
????????public?void?write(PreparedStatement stmt)?throws?SQLException {
??????????? stmt.setString(1,?this.word);
??????????? stmt.setInt(2,?this.number);
??????? }
??? }
?
????public?static?void?main(String[] args)?throws?Exception {
?
??????? JobConf conf =?new?JobConf(WriteDB.class);
?
????????//?这句话很关键
??????? conf.set("mapred.job.tracker",?"192.168.1.2:9001");
?
??????? DistributedCache.addFileToClassPath(new?Path(
????????????????"/lib/mysql-connector-java-5.1.18-bin.jar"), conf);
?
????????//?设置输入输出类型
??????? conf.setInputFormat(TextInputFormat.class);
??????? conf.setOutputFormat(DBOutputFormat.class);
????????//?不加这两句,通不过,但是网上给的例子没有这两句。
??????? conf.setOutputKeyClass(Text.class);
??????? conf.setOutputValueClass(IntWritable.class);
?
????????//?设置Map和Reduce类
??????? conf.setMapperClass(Map.class);
??????? conf.setCombinerClass(Combine.class);
??????? conf.setReducerClass(Reduce.class);
?
????????//?设置输如目录
??????? FileInputFormat.setInputPaths(conf,?new?Path("wdb_in"));
?
????????//?建立数据库连接
??????? DBConfiguration.configureDB(conf,?"com.mysql.jdbc.Driver",
????????????"jdbc:mysql://192.168.1.24:3306/school",?"root",?"hadoop");
?
????????//?写入"wordcount"表中的数据
??????? String[] fields = {?"word",?"number"?};
??????? DBOutputFormat.setOutput(conf,?"wordcount", fields);
?
??????? JobClient.runJob(conf);
??? }
}
?
???? ?3)运行结果如下所示
- Windows环境
测试数据:
(1)file1.txt
?
hello word
hello hadoop
?
????(2)file2.txt
?
虾皮 hadoop
虾皮 word
软件 软件
?
???? ?运行结果:
?

???? ?我们发现上图中出现了"?",后来查找原来是因为我的测试数据时在Windows用记事本写的然后保存为"UTF-8",在保存时为了区分编码,自动在前面加了一个"BOM",但是不会显示任何结果。然而我们的代码把它识别为"?"进行处理。这就出现了上面的结果,如果我们在每个要处理的文件前面的第一行加一个空格,结果就成如下显示:
?

?? ?? 接着又做了一个测试,在Linux上面用下面命令创建了一个文件,并写上中文内容。结果显示并没有出现"?",而且网上说不同的记事本软件(EmEditor、UE)保存为"UTF-8"就没有这个问题。经过修改之后的Map类,就能够正常识别了。
?
????// Map处理过程
????public?static?class?Map?extends?MapReduceBase?implements
??????????? Mapper
?
????????private?final?static?IntWritable?one?=?new?IntWritable(1);
????????private?Text?word?=?new?Text();
?
????????@Override
????????public?void?map(Object key, Text value,
??????????? OutputCollector
output, Reporter reporter) ????????????????throws?IOException {
??????????? String line = value.toString();
???????????
????????????//处理记事本UTF-8的BOM问题
????????????if?(line.getBytes().length?> 0) {
????????????????if?((int) line.charAt(0) == 65279) {
??????????????????? line = line.substring(1);
??????????????? }
??????????? }
???????????
??????????? StringTokenizer tokenizer =?new?StringTokenizer(line);
????????????while?(tokenizer.hasMoreTokens()) {
????????????????word.set(tokenizer.nextToken());
??????????????? output.collect(word,?one);
??????????? }
??????? }
??? }
?
???? ?处理之后的结果:
?

?
???? ?从上图中得知,我们的问题已经解决了,因此,在编辑、更改任何文本文件时,请务必使用不会乱加BOM的编辑器。Linux下的编辑器应该都没有这个问题。Windows下,请勿使用记事本等编辑器。推荐的编辑器是: Editplus 2.12版本以上; EmEditor; UltraEdit(需要取消'添加BOM'的相关选项); Dreamweaver(需要取消'添加BOM'的相关选项) 等。
对于已经添加了BOM的文件,要取消的话,可以用以上编辑器另存一次。(Editplus需要先另存为gb,再另存为UTF-8。) DW解决办法如下: 用DW打开指定文件,按Ctrl+Jà标题/编码à编码选择"UTF-8",去掉"包括Unicode签名(BOM)"勾选à保存/另存为,即可。
??? 国外有一个牛人已经把这个问题解决了,使用"UnicodeInputStream"、"UnicodeReader"。
??? 地址:http://koti.mbnet.fi/akini/java/unicodereader/
??? 示例:Java读带有BOM的UTF-8文件乱码原因及解决方法
??? 代码:http://download.csdn.net/detail/xia520pi/4146123
?
- Linux环境
测试数据:
????(1)file1.txt
?
MapReduce is simple
?
????(2)file2.txt
?
MapReduce is powerful is simple
?
????(3)file2.txt
?
Hello MapReduce bye MapReduce
?
??? ? 运行结果:
?

?
?? ?? 到目前为止,MapReduce与关系型数据库交互已经结束,从结果中得知,目前新版的API还不能很好的支持关系型数据库的操作,上面两个例子都是使用的旧版的API。关于更多的MySQL操作。?
??????终于完成,期间遇到的关键问题如下:
?
- MySQL的JDBC的jar存放问题。
- Win7对MySQL防火墙的设置。
- Linux中MySQL变更目录不能启动。
- MapReduce处理带BOM的UTF-8问题。
- 设置MySQL可以远程访问。
- MySQL处理中文乱码问题。
?
从这几天对MapReduce的了解,发现其实Hadoop对关系型数据库的处理还不是很强,主要是Hadoop和关系型数据做的事不是同一类型,各有所特长。下面几期我们将对Hadoop里的HBase和Hive进行全面了解。
更多0- 上一篇MapReduce探索

 如何在iPhone中使Google地图成为默认地图Apr 17, 2024 pm 07:34 PM
如何在iPhone中使Google地图成为默认地图Apr 17, 2024 pm 07:34 PMiPhone上的默认地图是Apple专有的地理位置提供商“地图”。尽管地图越来越好,但它在美国以外的地区运行不佳。与谷歌地图相比,它没有什么可提供的。在本文中,我们讨论了使用Google地图成为iPhone上的默认地图的可行性步骤。如何在iPhone中使Google地图成为默认地图将Google地图设置为手机上的默认地图应用程序比您想象的要容易。请按照以下步骤操作–先决条件步骤–您必须在手机上安装Gmail。步骤1–打开AppStore。步骤2–搜索“Gmail”。步骤3–点击Gmail应用旁
 mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM
mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM在mysql中,可以利用char()和REPLACE()函数来替换换行符;REPLACE()函数可以用新字符串替换列中的换行符,而换行符可使用“char(13)”来表示,语法为“replace(字段名,char(13),'新字符串') ”。
 如何在uniapp中使用地图和定位功能Oct 16, 2023 am 08:01 AM
如何在uniapp中使用地图和定位功能Oct 16, 2023 am 08:01 AM如何在uniapp中使用地图和定位功能一、背景介绍随着移动应用的普及和定位技术的迅猛发展,地图和定位功能已经成为了现代移动应用中不可缺少的一部分。uniapp是一种基于Vue.js开发的跨平台应用开发框架,可以方便开发者在多个平台上共用代码。本文将介绍如何在uniapp中使用地图和定位功能,并提供具体的代码示例。二、使用uniapp-amap组件实现地图功能
 小红书如何把店铺地址加入地图?店铺地址设置怎么填?Mar 29, 2024 am 09:41 AM
小红书如何把店铺地址加入地图?店铺地址设置怎么填?Mar 29, 2024 am 09:41 AM随着小红书越来越受到年轻人的喜爱,越来越多的人选择在小红书上开店。许多新手卖家在设置店铺地址时遇到了困难,不知道如何把店铺地址加入地图。一、小红书如何把店铺地址加入地图?1.首先,确保您的店铺在小红书上有注册账号,并且已经成功开设店铺。2.登录小红书账号,进入店铺后台,找到“店铺设置”选项。3.在店铺设置页面,找到“店铺地址”一栏,点击“添加地址”。4.在弹出的地址添加页面,填写店铺的详细地址信息,包括省份、城市、区县、街道、门牌号等。5.填写完毕后,点击“确认添加”按钮。小红书会对您提供的地址
 如何使用Highcharts创建地图热力图Dec 17, 2023 pm 04:06 PM
如何使用Highcharts创建地图热力图Dec 17, 2023 pm 04:06 PM如何使用Highcharts创建地图热力图,需要具体代码示例热力图是一种可视化的数据展示方式,能够通过不同颜色深浅来表示各个区域的数据分布情况。在数据可视化领域,Highcharts是一个非常受欢迎的JavaScript库,它提供了丰富的图表类型和交互功能。本文将介绍如何使用Highcharts创建地图热力图,并提供具体的代码示例。首先,我们需要准备一些数据
 MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM
MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于MySQL复制技术的相关问题,包括了异步复制、半同步复制等等内容,下面一起来看一下,希望对大家有帮助。
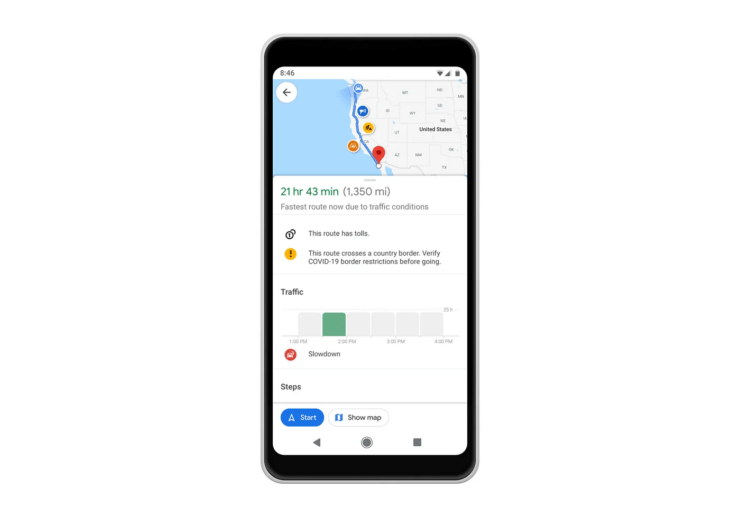 如何在谷歌地图上使用一目了然的方向Jun 13, 2024 pm 09:40 PM
如何在谷歌地图上使用一目了然的方向Jun 13, 2024 pm 09:40 PM在发布一年后,谷歌地图推出了一项新的功能。一旦您在地图上设置了目的地的路线,它就会总结您的旅行路线。旅程开始后,您可以从手机锁定屏幕“浏览”路线导航。您可以使用Google地图来查看您的预计到达时间和路线。在整个旅行期间,您可以在锁定屏幕上查看导航信息,通过解锁手机,无需访问Google地图即可查看导航信息。通过解锁手机,无需访问Google地图即可查看导航信息。通过解锁手机,无需访问Google地图,您即可查看导航信息,解锁手机,无需访问Google地图,您即可查看导航信息,解锁手机,无需访问
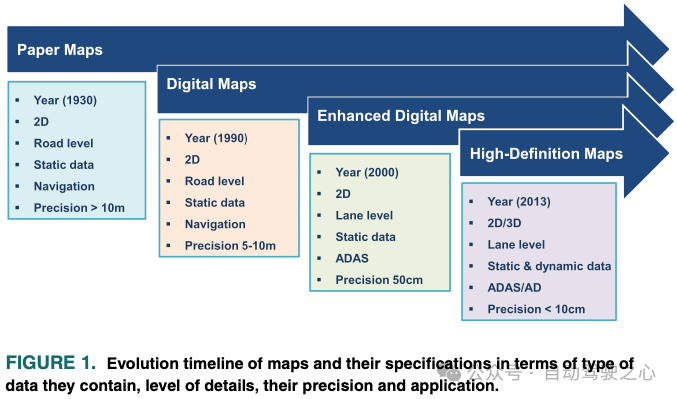 云端车端MapNeXt全搞定!面向下一代在线高精地图构建Jan 31, 2024 pm 06:06 PM
云端车端MapNeXt全搞定!面向下一代在线高精地图构建Jan 31, 2024 pm 06:06 PM写在前面&笔者的个人理解在协作、互联和自动化移动(CCAM)中,智能驾驶车辆对周围环境的感知、建模和分析能力越强,它们就越能意识到并能够理解、做出决策,以及安全高效地执行复杂的驾驶场景。高精(HD)地图以厘米级精度和车道级语义信息表示道路环境,使其成为智能移动系统的核心组件,也是CCAM技术的关键推动者。这些地图为自动化车辆提供了了解周围环境的强大优势。高精地图也被视为隐藏的或虚拟的传感器,因为它汇集了来自物理传感器的知识(地图),即激光雷达、相机、GPS和IMU,以建立道路环境的模型。高精地图


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Zend Studio 13.0.1
Powerful PHP integrated development environment

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

