


oracle中默认的索引类型是B树索引。还有位图索引,反向键索引,hash索引,基于函数的索引。 本篇主要介绍B树索引,通过转储分析。对于索引的扫描类型,索引的基本操作不做详细的介绍。 系统信息: [oracle@localhost ~]$ cat /etc/issue Enterprise Linux Ent
oracle中默认的索引类型是B树索引。还有位图索引,反向键索引,hash索引,基于函数的索引。本篇主要介绍B树索引,通过转储分析。对于索引的扫描类型,索引的基本操作不做详细的介绍。
系统信息:
[oracle@localhost ~]$ cat /etc/issue
Enterprise Linux Enterprise Linux Server release 5.5 (Carthage)
Kernel \r on an \m
数据库版本:
SQL> select * from v$version where rownum =1 ;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
SQL> show user;
USER 为 "HR"
SQL> desc tt;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
ID NUMBER
NAME VARCHAR2(10)
SQL> select count(rownum) from tt;
COUNT(ROWNUM)
-------------
3670016
基于ID创建索引index_t
SQL> create index index_t on tt(id) tablespace users;
索引已创建。
SQL> select object_id from dba_objects where object_name=
2 'INDEX_T';
数据库中segment有数据段,索引段,undo段,它们和表名,索引名不是同一概念,但是名字是相同的。
OBJECT_ID
----------
76332
转储索引:
SQL> alter session set events 'immediate trace name treedump level 76332';
会话已更改。
----- begin tree dump branch: 0x10038ab 16791723 (0: nrow: 15, level: 2) branch: 0x100540b 16798731 (-1: nrow: 503, level: 1) leaf: 0x10038ac 16791724 (-1: nrow: 512 rrow: 512) leaf: 0x10038ad 16791725 (0: nrow: 512 rrow: 512) leaf: 0x10038ae 16791726 (1: nrow: 512 rrow: 512) leaf: 0x10038af 16791727 (2: nrow: 512 rrow: 512) leaf: 0x10038b0 16791728 (3: nrow: 512 rrow: 512) leaf: 0x10038b1 16791729 (4: nrow: 512 rrow: 512) leaf: 0x10038b2 16791730 (5: nrow: 512 rrow: 512) leaf: 0x10038b3 16791731 (6: nrow: 512 rrow: 512) leaf: 0x10038b4 16791732 (7: nrow: 512 rrow: 512) leaf: 0x10038b5 16791733 (8: nrow: 512 rrow: 512) leaf: 0x10038b6 16791734 (9: nrow: 512 rrow: 512) leaf: 0x10038b7 16791735 (10: nrow: 512 rrow: 512) leaf: 0x10038b9 16791737 (11: nrow: 512 rrow: 512) leaf: 0x10038ba 16791738 (12: nrow: 512 rrow: 512) leaf: 0x10038bb 16791739 (13: nrow: 512 rrow: 512) leaf: 0x10038bc 16791740 (14: nrow: 512 rrow: 512) leaf: 0x10038bd 16791741 (15: nrow: 512 rrow: 512) leaf: 0x10038be 16791742 (16: nrow: 512 rrow: 512) leaf: 0x10038bf 16791743 (17: nrow: 512 rrow: 512) leaf: 0x10038c0 16791744 (18: nrow: 512 rrow: 512) leaf: 0x10038c1 16791745 (19: nrow: 512 rrow: 512) leaf: 0x10038c2 16791746 (20: nrow: 512 rrow: 512) leaf: 0x10038c3 16791747 (21: nrow: 512 rrow: 512) leaf: 0x10038c4 16791748 (22: nrow: 512 rrow: 512) leaf: 0x10038c5 16791749 (23: nrow: 512 rrow: 512) leaf: 0x10038c6 16791750 (24: nrow: 512 rrow: 512) leaf: 0x10038c7 16791751 (25: nrow: 512 rrow: 512) leaf: 0x10038c9 16791753 (26: nrow: 512 rrow: 512) leaf: 0x10038ca 16791754 (27: nrow: 512 rrow: 512) leaf: 0x10038cb 16791755 (28: nrow: 512 rrow: 512) leaf: 0x10038cc 16791756 (29: nrow: 512 rrow: 512) leaf: 0x10038cd 16791757 (30: nrow: 512 rrow: 512) leaf: 0x10038ce 16791758 (31: nrow: 512 rrow: 512) leaf: 0x10038cf 16791759 (32: nrow: 512 rrow: 512) leaf: 0x10038d0 16791760 (33: nrow: 512 rrow: 512) leaf: 0x10038d1 16791761 (34: nrow: 512 rrow: 512) leaf: 0x10038d2 16791762 (35: nrow: 512 rrow: 512) leaf: 0x10038d3 16791763 (36: nrow: 512 rrow: 512) leaf: 0x10038d4 16791764 (37: nrow: 512 rrow: 512) leaf: 0x10038d5 16791765 (38: nrow: 512 rrow: 512) leaf: 0x10038d6 16791766 (39: nrow: 512 rrow: 512) leaf: 0x10038d7 16791767 (40: nrow: 512 rrow: 512) leaf: 0x10038d9 16791769 (41: nrow: 512 rrow: 512) leaf: 0x10038da 16791【本文来自鸿网互联 (http://www.68idc.cn)】770 (42: nrow: 512 rrow: 512) leaf: 0x10038db 16791771 (43: nrow: 512 rrow: 512) leaf: 0x10038dc 16791772 (44: nrow: 512 rrow: 512) leaf: 0x10038dd 16791773 (45: nrow: 512 rrow: 512) leaf: 0x10038de 16791774 (46: nrow: 512 rrow: 512) ........................................................................... .... .... .... ----- end tree dump
这是一棵平衡树,因为平衡树的查找效率很高,根节点到所有的叶子节点的高度相同。 branch表示的是根节点。以上选取了一部分,已经按从左向右拍好序了。
leaf: 0x10038ac 16791724 (-1: nrow: 512 rrow: 512) 我们选取这一列:
把十六进制,和十进制数相互转换:
SQL> select to_number('10038ac','xxxxxxxxxxxxxxxx') from dual; TO_NUMBER('10038AC','XXXXXXXXXXXXXXXX') --------------------------------------- 16791724 SQL> select to_char('16791724','xxxxxxxxxxxxxxxx') from dual; TO_CHAR('16791724','XXXXXXXXXXXXXX ---------------------------------- 10038ac
我们利用oracle中提供的一个包可以求得索引所在的文件号,块号:
SQL> select dbms_utility.data_block_address_file(16791724) from dual; DBMS_UTILITY.DATA_BLOCK_ADDRESS_FILE(16791724) ---------------------------------------------- 4 SQL> select dbms_utility.data_block_address_block(16791724) from dual; DBMS_UTILITY.DATA_BLOCK_ADDRESS_BLOCK(16791724) ----------------------------------------------- 14508
通过查视图dba_extends,索引存储在数据文件4,块14508在起始块范围内。

此时我们dump数据文件4,块14508:
SQL> alter system dump datafile 4 block 14508;
系统已更改。
row#0[8020] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 01 row#1[8008] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 03 row#2[7996] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 08 row#3[7984] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 0a row#4[7972] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 0f row#5[7960] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 11 row#6[7948] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 16 row#7[7936] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 18 row#8[7924] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 1d row#9[7912] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 1f row#10[7900] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 24 row#11[7888] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 26 row#12[7876] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 2b row#13[7864] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 2d row#14[7852] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 32 row#15[7840] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 34 row#16[7828] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 39 row#17[7816] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 3b row#18[7804] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 40 row#19[7792] flag: ------, lock: 0, len=12 col 0; len 2; (2): c1 02 col 1; len 6; (6): 01 00 1b ab 00 42 row#20[7780] flag: ------, lock: 0, len=12 ...............................................................
.......
选取这一行为例:
row#0[8020] flag: ------, lock: 0, len=12
col 0; len 2; (2): c1 02
col 1; len 6; (6): 01 00 1b ab 00 01
col 0 表示第一列,长度为2,c1 02表示是多少呢?
SQL> select * from tt where rownum<4 order by id; ID NAME ---------- -------------------- 1 wO 2 wang 6 hong SQL> select dump(1,16) from dual; DUMP(1,16) ----------------------------------
Typ=2 Len=2: c1,2 ==>这里是c1 02,0省略了
这下清楚了吧,第一行第一列存储的是1,orale存储数据的方法很复杂。
col 1表示的是第二列,长度是6, 01 00 1b ab 00 01就是索引的值,是十六进制数,我们可以转化为二进制数:
00000001 00000000 00011011 10101011 00000000 00000001
-----------------------------------------------------------------------------------------------------------------------------------------------------------
00000001 00 ==>1x2x2=4 前10位表示了数据文件号
000000 00011011 10101011 ==>4096+2048+512+256+128+32+8+2+1=7083 这里的22位表示了块号
00000000 00000001==>1 16位代表着行号
此时排序并查rowid:

此时用第一列的rowid,
通过oracle提供的一个包,可以求出对象编号,文件号,块号:
执行如下图:

上面从索引存储的段以及数据段进行分析。
我们知道索引不一定会提高查询效率,往往乱建索引会严重影响查询效率,系统用不用索引,我们不能干预(但是dba可以手动改变),是oracle CBO选择的结果。
下面我们可以做一个小实验:
SQL> select count(rowid) from t; COUNT(ROWID) ------------ 4718644 SQL> select count(rowid) from t where id=1; COUNT(ROWID) ------------ 4718592 SQL> select count(rowid) from t where id=2; COUNT(ROWID) ------------ 26 SQL> select count(rowid) from t where id=3; COUNT(ROWID) ------------ 26 SQL> set autotrace traceonly; SQL> select * from tt;
执行计划
---------------------------------------------------------- Plan hash value: 264906180 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3556K| 67M| 1742 (2)| 00:00:21 | | 1 | TABLE ACCESS FULL| TT | 3556K| 67M| 1742 (2)| 00:00:21 | -------------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement (level=2)
此时是全表扫描读取,是多块读取,,这样读取比较快,如果此时用索引,则效率会低。
SQL> select * from tt where id=5;
执行计划
----------------------------------------------------------
Plan hash value: 3103123359
--------------------------------------------------------------------------------
-------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Tim
e |
--------------------------------------------------------------------------------
-------
| 0 | SELECT STATEMENT | | 5 | 100 | 4 (0)| 00:
00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TT | 5 | 100 | 4 (0)| 00:
00:01 |
|* 2 | INDEX RANGE SCAN | INDEX_T | 5 | | 3 (0)| 00:
00:01 |
--------------------------------------------------------------------------------
-------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=5)
Note
-----
- dynamic sampling used for this statement (level=2)
此时是索引读取。
SQL> select * from tt where id=1;
执行计划
----------------------------------------------------------
Plan hash value: 264906180
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2121K| 40M| 3644 (2)| 00:00:44 |
|* 1 | TABLE ACCESS FULL| TT | 2121K| 40M| 3644 (2)| 00:00:44 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=1)
Note
-----
- dynamic sampling used for this statement (level=2)
看到了吧,此时是全表扫描读取,数据库是很聪明的吧!

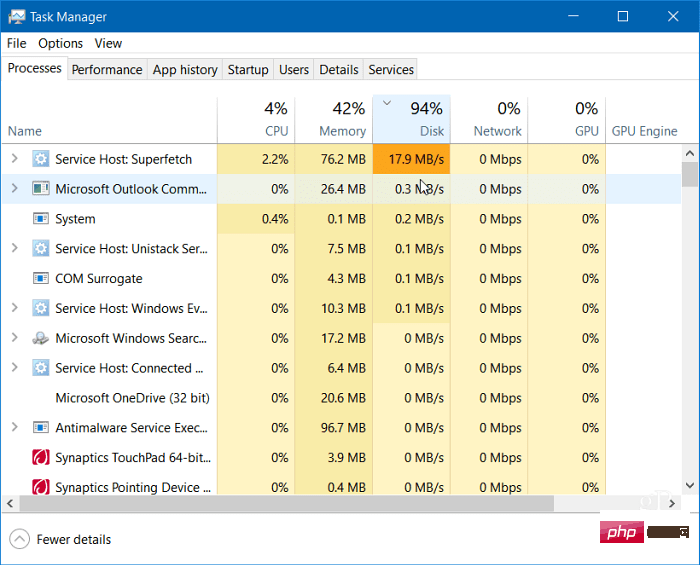 如何在 Windows 11 上修复 100% 的磁盘使用率Apr 20, 2023 pm 12:58 PM
如何在 Windows 11 上修复 100% 的磁盘使用率Apr 20, 2023 pm 12:58 PM如何在Window11上修复100%的磁盘使用率查找导致100%磁盘使用的有问题的应用程序或服务的直接方法是使用任务管理器。要打开任务管理器,请右键单击开始菜单并选择任务管理器。单击磁盘列标题,查看占用最多资源的内容。从那里开始,您将很好地了解从哪里开始。但是,问题可能比仅仅关闭应用程序或禁用服务更严重。继续阅读以查找问题的更多潜在原因以及如何解决这些问题。禁用SuperfetchSuperfetch功能(在Windows11中也称为SysMain)有助于通过访问预取文件来减少启动时
 如何在 Windows 11 中隐藏文件和文件夹并从搜索中移除?Apr 26, 2023 pm 11:07 PM
如何在 Windows 11 中隐藏文件和文件夹并从搜索中移除?Apr 26, 2023 pm 11:07 PM<h2>如何在Windows11上从搜索中隐藏文件和文件夹</h2><p>我们首先要看的是自定义Windows搜索文件的位置。通过跳过这些特定位置,您应该可以更快地看到结果,同时还可以隐藏您想要保护的任何文件。</p><p>如果要从Windows11上的搜索中排除文件和文件夹,请使用以下步骤:</p><ol&
 dump文件是什么文件Jan 12, 2024 pm 04:58 PM
dump文件是什么文件Jan 12, 2024 pm 04:58 PMdump文件通常是指一种二进制文件,也被称为转储文件或核心转储文件。这种文件是计算机系统在遇到严重错误或异常情况时生成的,用于存储系统或应用程序的状态、堆栈、寄存器、内存映像、日志等信息。
 以下是6种修复Windows 11搜索栏不可用的方法。May 08, 2023 pm 10:25 PM
以下是6种修复Windows 11搜索栏不可用的方法。May 08, 2023 pm 10:25 PM如果您的搜索栏在Windows11中不起作用,有几种快速方法可以立即启动并运行!任何微软操作系统有时都可能遇到故障,最新的操作系统不能免除该规则。此外,正如Reddit上的用户u/zebra_head1所指出的那样,同样的错误出现在Windows11的22H2Build22621.1413上。用户抱怨切换任务栏搜索框的选项随机消失。因此,您必须为任何情况做好准备。为什么我无法在计算机上的搜索栏中键入内容?无法在计算机上键入可归因于不同的因素和过程。以下是您应该注意的一些事项:Ctfmon.
 Windows 11 Outlook 搜索不工作:6 个修复方法Apr 22, 2023 pm 09:46 PM
Windows 11 Outlook 搜索不工作:6 个修复方法Apr 22, 2023 pm 09:46 PM在Outlook中运行搜索和索引疑难解答您可以开始的更直接的修复之一是运行搜索和索引疑难解答。要在Windows11上运行疑难解答,请执行以下操作:单击开始按钮或按Windows键并从菜单中选择设置。当设置打开时,选择系统>疑难解答>其他疑难解答。在右侧向下滚动,找到SearchandIndexing,然后单击Run按钮。选择Outlook搜索不返回结果并继续屏幕上的说明。当您运行它时,疑难解答程序将自动识别并修复问题。运行疑难解答后,打开Outlook并查看搜索是否正常。如
 Python程序将多个元素插入到数组中的指定索引位置Sep 03, 2023 pm 10:13 PM
Python程序将多个元素插入到数组中的指定索引位置Sep 03, 2023 pm 10:13 PM数组是以有组织的方式存储的同类数据元素的集合。数组中的每个数据元素都由一个索引值来标识。Python中的数组Python没有原生的数组数据结构。因此,我们可以使用列表数据结构来替代数组。[10,4,11,76,99]同时我们可以使用PythonNumpy模块来处理数组。由numpy模块定义的数组是−array([1,2,3,4])Python中的索引从0开始,因此可以使用各自的索引值来访问上述数组元素,如0、1、2、直到n-1。在下面的文章中,我们将看到在指定索引处插入多个元素的不同方法。输入输
 深入剖析MySQL索引优化策略Jun 14, 2023 pm 12:01 PM
深入剖析MySQL索引优化策略Jun 14, 2023 pm 12:01 PM作为一种常用的关系型数据库,MySQL在今天的互联网应用中扮演着至关重要的角色。而在MySQL优化策略中,索引的使用更是至关重要。在MySQL中,索引是一种数据结构,用于快速定位数据中的特定行。使用索引可以大大提高查询效率,减少数据库处理数据的时间和资源。但不正确的索引使用方式,同样会导致数据库性能的下降。下面我们来深入剖析MySQL索引的优化策略,帮助您更
 dump在计算机中的意义是什么Jun 10, 2021 am 11:25 AM
dump在计算机中的意义是什么Jun 10, 2021 am 11:25 AM在计算机中,dump的中文意思为“转储”,一般指将数据导出、转存成文件或静态形式,即将动态(易失)的数据,保存为静态的数据(持久数据)。像程序这种本来就保存在存储介质(如硬盘)中的数据,是没有必要dump。


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

