
 Web Front-endJS TutorialDetailed explanation of the interpreter mode of javascript design patterns_javascript skills
Web Front-endJS TutorialDetailed explanation of the interpreter mode of javascript design patterns_javascript skillsDetailed explanation of the interpreter mode of javascript design patterns_javascript skills

What is "interpreter mode"?
First open "GOF" and look at Definition:
Given a language, define a representation of its grammar, and define an interpreter that uses this representation to interpret sentences in the language.
Before I start, I still need to popularize a few concepts:
Abstract syntax tree:
The interpreter mode does not explain how to create an abstract syntax tree. It does not involve syntax analysis. The abstract syntax tree can be completed by a table-driven parser, or it can be created by a handwritten (usually recursive descent) parser, or provided directly by the client.
Parser:
refers to a program that parses expressions describing client call requirements to form an abstract syntax tree.
Interpreter:
refers to the program that interprets the abstract syntax tree and executes the function corresponding to each node.
To use the interpreter mode, an important prerequisite is to define a set of grammatical rules, also called a grammar. Regardless of whether the rules of this grammar are simple or complex, these rules must be in place because the interpreter mode parses and performs corresponding functions according to these rules.
Let’s first take a look at the structure diagram and description of the interpreter mode:

AbstractExpression: Define the interface of the interpreter and agree on the interpretation operation of the interpreter.
TerminalExpression: Terminal interpreter is used to implement operations related to terminal symbols in grammar rules. It no longer contains other interpreters. If the combination mode is used to build an abstract syntax tree, it is quite For leaf objects in composite mode, there can be multiple terminal interpreters.
NonterminalExpression: Nonterminal interpreter, used to implement operations related to non-terminal symbols in grammar rules. Usually one interpreter corresponds to a grammar rule and can include other interpreters. If combined mode is used To build an abstract syntax tree, it is equivalent to the combination object in the combination pattern. There can be multiple nonterminal interpreters.
Context: Context usually contains data or public functions required by each interpreter.
Client: The client refers to the client that uses the interpreter. Usually, expressions made according to the grammar of the language are converted into abstract syntax trees described using the interpreter object, and then called Explain the operation.
Below we use an xml example to understand the interpreter mode:
First of all, we need to design a simple grammar for expressions. For universality, use root to represent the root element, abc, etc. to represent elements, a simple xml As follows:
/c>
>d3
🎜>
The grammar of the agreed expression is as follows:
1. Get the value of a single element: starting from the root element and going to the element where you want to get the value. The elements are separated by "/", before the root element. Do not add "/". For example, the expression "root/a/b/c" means to obtain the value of the a element, the a element, the b element, and the c element under the root element.
2. Get the value of the attribute of a single element: of course there are multiple ones. The attribute to get the value must be the attribute of the last element of the expression. Add "." after the last element and then add the name of the attribute. . For example, the expression "root/a/b/c.name" means to obtain the value of the name attribute of the element a, element b, and element c under the root element.
3. Get the value of the same element name, of course there are multiple ones. The element to get the value must be the last element of the expression, add "$" after the last element. For example, the expression "root/a/b/d$" means to obtain the set of values of multiple d elements under the root element, under the a element, and under the b element.
4. Get the value of the attribute with the same element name, of course there are multiple ones: the element to get the attribute value must be the last element of the expression, add "$" after the last element. For example, the expression "root/a/b/d$.id$" means to obtain the set of id attribute values of multiple d elements under the root element, under the a element, and under the b element.
The above xml, the corresponding abstract syntax tree, the possible structure is as shown in the figure:
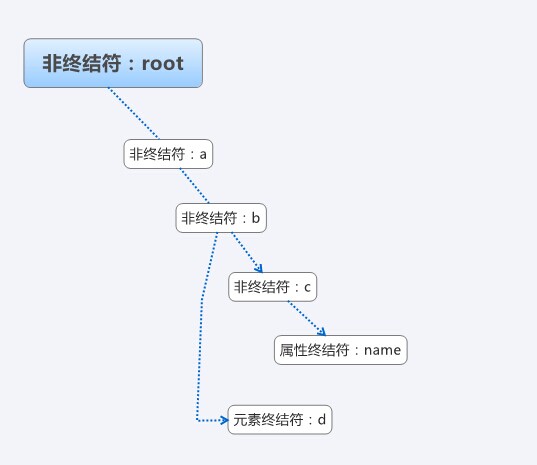
Let’s take a look at the specific code:
1. Define context:
/**
* Context, used to contain some global information needed by the interpreter
* @param {String} filePathName [the path and name of the xml that needs to be read]
*/
function Context(filePathName) {
// Previous processed element
this.preEle = null;
// xml Document object
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// Re-initialize the context
reInit: function () {
this.preEle = null;
},
/**
* Methods commonly used by various Expressions
* Get the current element based on the name of the parent element and the current element
* @param {Element} pEle [Parent element]
* @param {String} eleName [Current element name]
* @return {Element|null} [Current element found]
*/
getNowEle: function (pEle, eleName) {
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i if ((nowEle = tempNodeList[i]).nodeType === 1)
if (nowEle .nodeName === eleName)
return nowEle;
return null;
getPreEle: function () {
return this.preEle;
},
setPreEle: function (preEle) {
this.preEle = preEle;
},
getDocument: function () {
return this.document;
}
};
// Tool object
// Parse xml and obtain the corresponding Document object
var ;
var xmldom = parser.parseFromString('
return xmldom;
The following is the interpreter code:
Copy code
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i])
this.eles.splice(i--, 1);
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEle = context.getPreEle();
if (!pEle) {
// 说明现在获取的是根元素
context.setPreEle(context.getDocument().documentElement);
} else {
// 根据父级元素和要查找的元素的名称来获取当前的元素
var nowEle = context.getNowEle(pEle, this.eleName);
// 把当前获取的元素放到上下文中
context.setPreEle(nowEle);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
// 返回最后一个解释器的解释结果,一般最后一个解释器就是终结符解释器了
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEle = context.getPreEle();
var ele = null;
if (!pEle) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEle(pEle, this.eleName);
context.setPreEle(ele);
}
Get the value of the element
/**
* The interpreter corresponding to the attribute as a terminal symbol
* @param {String} propName [Name of the attribute]
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// Directly get the value of the last element attribute
}
};
Let’s first look at how to use the interpreter to get the value of a single element:
Copy code
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var cEle = new ElementTerminalExpression ('c');
// Combination
root.addEle(aEle);
aEle.addEle(bEle); bEle.addEle(cEle);
console.log('The value of c is = ' root.interpret(c));
}();
Output: The value of c is = 12345
Copy code
void function () {
var c = new Context();
// Want to get the id attribute of the d element, which is the value of the following expression: "a/b/c .name"
// c is not terminated at this time, you need to modify c to ElementExpression
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var cEle = new ElementExpression('c');
var prop = new PropertyTerminalExpression('name');
// Combination
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(cEle);
cEle.addEle(prop);
console.log('The attribute name value of c is = ' root.interpret(c));
// If you want to use the same context for continuous parsing, you need to re-initialize the context object
// For example, if you want to continuously re-obtain the value of the attribute name, of course you can recombine the elements
/ / Re-parse, as long as you are using the same context, you need to re-initialize the context object
c.reInit(); ));
}();
输出: c的属性name值是 = testC 重新获取c的属性name值是 = testC
讲解:
1.解释器模式功能:
解释器模式使用解释器对象来表示和处理相应的语法规则,一般一个解释器处理一条语法规则。理论上来说,只要能用解释器对象把符合语法的表达式表示出来,而且能够构成抽象的语法树,就可以使用解释器模式来处理。
2.语法规则和解释器
语法规则和解释器之间是有对应关系的,一般一个解释器处理一条语法规则,但是反过来并不成立,一条语法规则是可以有多种解释和处理的,也就是一条语法规则可以对应多个解释器。
3.上下文的公用性
上下文在解释器模式中起着非常重要的作用。由于上下文会被传递到所有的解释器中。因此可以在上下文中存储和访问解释器的状态,比如,前面的解释器可以存储一些数据在上下文中,后面的解释器就可以获取这些值。
另外还可以通过上下文传递一些在解释器外部,但是解释器需要的数据,也可以是一些全局的,公共的数据。
上下文还有一个功能,就是可以提供所有解释器对象的公共功能,类似于对象组合,而不是使用继承来获取公共功能,在每个解释器对象中都可以调用
4.谁来构建抽象语法树
在前面的示例中,是自己在客户端手工构建抽象语法树,是很麻烦的,但是在解释器模式中,并没有涉及这部分功能,只是负责对构建好的抽象语法树进行解释处理。后面会介绍可以提供解析器来实现把表达式转换成为抽象语法树。
还有一个问题,就是一条语法规则是可以对应多个解释器对象的,也就是说同一个元素,是可以转换成多个解释器对象的,这也就意味着同样一个表达式,是可以构成不用的抽象语法树的,这也造成构建抽象语法树变得很困难,而且工作量非常大。
5.谁负责解释操作
只要定义好了抽象语法树,肯定是解释器来负责解释执行。虽然有不同的语法规则,但是解释器不负责选择究竟用哪个解释器对象来解释执行语法规则,选择解释器的功能在构建抽象语法树的时候就完成了。
6.解释器模式的调用顺序
1)创建上下文对象
2)创建多个解释器对象,组合抽象语法树
3)调用解释器对象的解释操作
3.1)通过上下文来存储和访问解释器的状态。
对于非终结符解释器对象,递归调用它所包含的子解释器对象。
解释器模式的本质:*分离实现,解释执行*
解释器模使用一个解释器对象处理一个语法规则的方式,把复杂的功能分离开;然后选择需要被执行的功能,并把这些功能组合成为需要被解释执行的抽象语法树;再按照抽象语法树来解释执行,实现相应的功能。
从表面上看,解释器模式关注的是我们平时不太用到的自定义语法的处理;但从实质上看,解释器模式的思想然后是分离,封装,简化,和很多模式是一样的。
比如,可以使用解释器模式模拟状态模式的功能。如果把解释器模式要处理的语法简化到只有一个状态标记,把解释器看成是对状态的处理对象,对同一个表示状态的语法,可以有很多不用的解释器,也就是有很多不同的处理状态的对象,然后再创建抽象语法树的时候,简化成根据状态的标记来创建相应的解释器,不用再构建树了。
同理,解释器模式可以模拟实现策略模式的功能,装饰器模式的功能等,尤其是模拟装饰器模式的功能,构建抽象语法树的过程,自然就对应成为组合装饰器的过程。
解释器模式执行速度通常不快(大多数时候非常慢),而且错误调试比较困难(附注:虽然调试比较困难,但事实上它降低了错误的发生可能性),但它的优势是显而易见的,它能有效控制模块之间接口的复杂性,对于那种执行频率不高但代码频率足够高,且多样性很强的功能,解释器是非常适合的模式。此外解释器还有一个不太为人所注意的优势,就是它可以方便地跨语言和跨平台。
解释器模式的优缺点:
优点:
1.易于实现语法
在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。 2.易于扩展新的语法
It is precisely because of the way that an interpreter object is responsible for a grammar rule that it is very easy to extend new grammars. To extend the new syntax, you only need to create the corresponding interpreter object and use this new interpreter object when creating the abstract syntax tree.
Disadvantages:
Not suitable for complex syntax
If the grammar is particularly complex, the work of building the abstract syntax tree required for the interpreter mode is very arduous, and multiple abstract syntax trees may need to be built. So the interpreter mode is not suitable for complex grammars. It might be better to use a parser or compiler generator.
When to use?
When there is a language that needs to be interpreted and executed, and the sentences in the language can be represented as an abstract syntax tree, you can consider using the interpreter mode.
When using the interpreter mode, there are two other characteristics that need to be considered. One is that the syntax should be relatively simple. Grammar that is too responsible is not suitable for using the interpreter mode. The other is that the efficiency requirements are not very high; High, not suitable for use.
The previous article introduced how to obtain the value of a single element and the value of a single element attribute. Let’s take a look at how to obtain the value of multiple elements, as well as the values of the names of multiple elements, as well as the previous tests. For the artificially assembled abstract syntax tree, we also implemented the following simple parser to convert expressions that conform to the previously defined grammar into the abstract syntax tree of the previously implemented interpreter: I posted the code directly:
// 读取多个元素或属性的值
(function () {
/**
* 上下文,用来包含解释器需要的一些全局信息
* @param {String} filePathName [需要读取的xml的路径和名字]
*/
function Context(filePathName) {
// 上一个被处理的多个元素
this.preEles = [];
// xml的Document对象
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// 重新初始化上下文
reInit: function () {
this.preEles = [];
},
/**
* 各个Expression公共使用的方法
* 根据父元素和当前元素的名称来获取当前元素
* @param {Element} pEle [父元素]
* @param {String} eleName [当前元素名称]
* @return {Element|null} [找到的当前元素]
*/
getNowEles: function (pEle, eleName) {
var elements = [];
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i if ((nowEle = tempNodeList[i]).nodeType === 1) {
if (nowEle.nodeName === eleName) {
elements.push(nowEle);
}
}
}
return elements;
},
getPreEles: function () {
return this.preEles;
},
setPreEles: function (nowEles) {
this.preEles = nowEles;
},
getDocument: function () {
return this.document;
}
};
// 工具对象
// 解析xml,获取相应的Document对象
var XmlUtil = {
getRoot: function (filePathName) {
var parser = new DOMParser();
var xmldom = parser.parseFromString('
return xmldom;
}
};
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEles = context.getPreEles();
var ele = null;
var nowEles = [];
if (!pEles.length) {
// 说明现在获取的是根元素
ele = context.getDocument().documentElement;
pEles.push(ele);
context.setPreEles(pEles);
} else {
var tempEle;
for (var i = 0, len = pEles.length; i tempEle = pEles[i];
nowEles = nowEles.concat(context.getNowEles(tempEle, this.eleName));
// 找到一个就停止
if (nowEles.length) break;
}
context.setPreEles([nowEles[0]]);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var ele = null;
if (!pEles.length) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEles(pEles[0], this.eleName)[0];
}
// 获取元素的值
return ele.firstChild.nodeValue;
}
};
/**
* 属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// 直接获取最后的元素属性的值
return context.getPreEles()[0].getAttribute(this.propName);
}
};
/**
* 多个属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertysTerminalExpression(propName) {
this.propName = propName;
}
PropertysTerminalExpression.prototype = {
interpret: function (context) {
var eles = context.getPreEles();
var ss = [];
for (var i = 0, len = eles.length; i ss.push(eles[i].getAttribute(this.propName));
}
return ss;
}
};
/**
* 以多个元素作为终结符的解释处理对象
* @param {[type]} name [description]
*/
function ElementsTerminalExpression(name) {
this.eleName = name;
}
ElementsTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
var ss = [];
for (i = 0, len = nowEles.length; i ss.push(nowEles[i].firstChild.nodeValue);
}
return ss;
}
};
/**
* 多个元素作为非终结符的解释处理对象
*/
function ElementsExpression(name) {
this.eleName = name;
this.eles = [];
}
ElementsExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
context.setPreEles(nowEles);
var ss;
for (i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
},
addEle: function (ele) {
this.eles.push(ele);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
}
};
void function () {
// "root/a/b/d$"
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsTerminalExpression('d');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的值是 = ' + ss[i]);
}
}();
void function () {
// a/b/d$.id$
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsExpression('d');
var prop = new PropertysTerminalExpression('id');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
dEle.addEle(prop);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的属性id的值是 = ' + ss[i]);
}
}();
// 解析器
/**
* 解析器的实现思路
* 1.把客户端传递来的表达式进行分解,分解成为一个一个的元素,并用一个对应的解析模型来封装这个元素的一些信息。
* 2.根据每个元素的信息,转化成相对应的解析器对象。
* 3.按照先后顺序,把这些解析器对象组合起来,就得到抽象语法树了。
*
* 为什么不把1和2合并,直接分解出一个元素就转换成相应的解析器对象?
* 1.功能分离,不要让一个方法的功能过于复杂。
* 2.为了今后的修改和扩展,现在语法简单,所以转换成解析器对象需要考虑的东西少,直接转换也不难,但要是语法复杂了,直接转换就很杂乱了。
*/
/**
* 用来封装每一个解析出来的元素对应的属性
*/
function ParserModel() {
// 是否单个值
this.singleValue;
// 是否属性,不是属性就是元素
this.propertyValue;
// 是否终结符
this.end;
}
ParserModel.prototype = {
isEnd: function () {
return this.end;
},
setEnd: function (end) {
this.end = end;
},
isSingleValue: function () {
return this.singleValue;
},
setSingleValue: function (oneValue) {
this.singleValue = oneValue;
},
isPropertyValue: function () {
return this.propertyValue;
},
setPropertyValue: function (propertyValue) {
this.propertyValue = propertyValue;
}
};
var Parser = function () {
var BACKLASH = '/';
var DOT = '.';
var DOLLAR = '$';
// 按照分解的先后记录需要解析的元素的名称
var listEle = null;
// 开始实现第一步-------------------------------------
/**
* 传入一个字符串表达式,通过解析,组合成为一个抽象语法树
* @param {String} expr [描述要取值的字符串表达式]
* @return {Object} [对应的抽象语法树]
*/
function parseMapPath(expr) {
// 先按照“/”分割字符串
var tokenizer = expr.split(BACKLASH);
// 用来存放分解出来的值的表
var mapPath = {};
var onePath, eleName, propName;
var dotIndex = -1;
for (var i = 0, len = tokenizer.length; i onePath = tokenizer[i];
if (tokenizer[i + 1]) {
// 还有下一个值,说明这不是最后一个元素
// 按照现在的语法,属性必然在最后,因此也不是属性
setParsePath(false, onePath, false, mapPath);
} else {
// 说明到最后了
dotIndex = onePath.indexOf(DOT);
if (dotIndex >= 0) {
// 说明是要获取属性的值,那就按照“.”来分割
// 前面的就是元素名称,后面的是属性的名字
eleName = onePath.substring(0, dotIndex);
propName = onePath.substring(dotIndex + 1);
// 设置属性前面的那个元素,自然不是最后一个,也不是属性
setParsePath(false, eleName, false, mapPath);
// 设置属性,按照现在的语法定义,属性只能是最后一个
setParsePath(true, propName, true, mapPath);
} else {
// 说明是取元素的值,而且是最后一个元素的值
setParsePath(true, onePath, false, mapPath);
}
break;
}
}
return mapPath;
}
/** * /
Function setparsepath (end, ele, propertyValue, mappath) {
var pm = new parseermodel ();
pm.seitend (end); // If there is a "$" symbol, it means it is not a value
/ / Remove "$"
ele = ele.replace(DOLLAR, '');
mapPath[ele] = pm;
listEle.push(ele);
}
// Start to realize the second step ----------------------------------------

 JavaScript Comments: A Guide to Using // and /* */May 13, 2025 pm 03:49 PM
JavaScript Comments: A Guide to Using // and /* */May 13, 2025 pm 03:49 PMJavaScriptusestwotypesofcomments:single-line(//)andmulti-line(//).1)Use//forquicknotesorsingle-lineexplanations.2)Use//forlongerexplanationsorcommentingoutblocksofcode.Commentsshouldexplainthe'why',notthe'what',andbeplacedabovetherelevantcodeforclari
 Python vs. JavaScript: A Comparative Analysis for DevelopersMay 09, 2025 am 12:22 AM
Python vs. JavaScript: A Comparative Analysis for DevelopersMay 09, 2025 am 12:22 AMThe main difference between Python and JavaScript is the type system and application scenarios. 1. Python uses dynamic types, suitable for scientific computing and data analysis. 2. JavaScript adopts weak types and is widely used in front-end and full-stack development. The two have their own advantages in asynchronous programming and performance optimization, and should be decided according to project requirements when choosing.
 Python vs. JavaScript: Choosing the Right Tool for the JobMay 08, 2025 am 12:10 AM
Python vs. JavaScript: Choosing the Right Tool for the JobMay 08, 2025 am 12:10 AMWhether to choose Python or JavaScript depends on the project type: 1) Choose Python for data science and automation tasks; 2) Choose JavaScript for front-end and full-stack development. Python is favored for its powerful library in data processing and automation, while JavaScript is indispensable for its advantages in web interaction and full-stack development.
 Python and JavaScript: Understanding the Strengths of EachMay 06, 2025 am 12:15 AM
Python and JavaScript: Understanding the Strengths of EachMay 06, 2025 am 12:15 AMPython and JavaScript each have their own advantages, and the choice depends on project needs and personal preferences. 1. Python is easy to learn, with concise syntax, suitable for data science and back-end development, but has a slow execution speed. 2. JavaScript is everywhere in front-end development and has strong asynchronous programming capabilities. Node.js makes it suitable for full-stack development, but the syntax may be complex and error-prone.
 JavaScript's Core: Is It Built on C or C ?May 05, 2025 am 12:07 AM
JavaScript's Core: Is It Built on C or C ?May 05, 2025 am 12:07 AMJavaScriptisnotbuiltonCorC ;it'saninterpretedlanguagethatrunsonenginesoftenwritteninC .1)JavaScriptwasdesignedasalightweight,interpretedlanguageforwebbrowsers.2)EnginesevolvedfromsimpleinterpreterstoJITcompilers,typicallyinC ,improvingperformance.
 JavaScript Applications: From Front-End to Back-EndMay 04, 2025 am 12:12 AM
JavaScript Applications: From Front-End to Back-EndMay 04, 2025 am 12:12 AMJavaScript can be used for front-end and back-end development. The front-end enhances the user experience through DOM operations, and the back-end handles server tasks through Node.js. 1. Front-end example: Change the content of the web page text. 2. Backend example: Create a Node.js server.
 Python vs. JavaScript: Which Language Should You Learn?May 03, 2025 am 12:10 AM
Python vs. JavaScript: Which Language Should You Learn?May 03, 2025 am 12:10 AMChoosing Python or JavaScript should be based on career development, learning curve and ecosystem: 1) Career development: Python is suitable for data science and back-end development, while JavaScript is suitable for front-end and full-stack development. 2) Learning curve: Python syntax is concise and suitable for beginners; JavaScript syntax is flexible. 3) Ecosystem: Python has rich scientific computing libraries, and JavaScript has a powerful front-end framework.
 JavaScript Frameworks: Powering Modern Web DevelopmentMay 02, 2025 am 12:04 AM
JavaScript Frameworks: Powering Modern Web DevelopmentMay 02, 2025 am 12:04 AMThe power of the JavaScript framework lies in simplifying development, improving user experience and application performance. When choosing a framework, consider: 1. Project size and complexity, 2. Team experience, 3. Ecosystem and community support.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SublimeText3 Linux new version
SublimeText3 Linux latest version

Dreamweaver CS6
Visual web development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

