



biapps是基于obiee的 BIAPPS开发概要 1. 搭建数据仓库 2. 数据抽取(ETL) 3. 搭建数据模型 4. 搭建报表系统 1、数据仓库 数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化
biapps是基于obiee的
BIAPPS开发概要
1. 搭建数据仓库
2. 数据抽取(ETL)
3. 搭建数据模型
4. 搭建报表系统
1、数据仓库
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。详见百度百科。2、ETL
在biapps的ETL过程中,有使用到Stage层,其实Stage层就是一些临时表内容,用于临时存储一些需要处理的数据。
因为时间维的数据不会随着时间的推移而发生变化,这里就再为时间维创建Stage临时表了。
WID
一般是将主键设置为WID,在SIL层进行WID的转换(维表也可能在SDE转换)事实表的维表代理键使用lookup组件进行关联写入(可见下图事实表)SDE和DIL实际上是在同一个用户下
增量和全量
从EBS源抽取数据的SDE过程的增量(这个增量过程的过滤条件可以在SQ中的Source Filter中写代码或者在Sql Query中写代买)全量是用 CUX_OM_CN_DOWN_USE_HEADER_ALL.LAST_UPDATE_DATE >= TO_DATE('$$LAST_EXTRACT_DATE', 'MM/DD/YYYY HH24:MI:SS') 区分即时间戳方式,变量在DAC中维护具体增量和全量的运行体现在不同的会话,运行全量时可以将增量的过滤条件拿掉或者在sql query中去掉where条件SIL是从中间表到目标表的过程用UPDATE_FLAG(主键进行lookup并打上插入更新标记和时间,可见下图)标识在目标表里面数据是否存在即全表比对方式;有的时候SIL层的增量和全量是一样的,区分在于是否truncate,前提是要使用更新组件全量则只需在新的会话中放开这些过滤条件即可

练习SIL层增量全量还有问题?
OK,可参考虚拟机的demo,主要是组件的使用和增量操作,组件包括LKP组件、EXP组件、UPD组件和FLT组件的使用;
增量操作则是在SDE比较好实现即通过时间戳的方式,在SIL则通过和目标表的数据比对;
全量操作在SDE则去掉时间戳勾选truncate,在SIL则勾选truncate即可;
数据抽取方式?
数据抽取方式?
从数据库中抽取数据一般有以下几种方式:
1) 全量抽取
全量抽取类似于数据迁移或数据复制,它将数据源中的表或视图的数据原封不动的从数
据库中抽取出来,并转换成自己的ETL 工具可以识别的格式。全量抽取比较简单。
2) 增量抽取
增量抽取只抽取自上次抽取以来数据库中要抽取的表中新增或修改的数据。在ETL 使用过程中,增量抽取较全量抽取应用更广。如何捕获变化的数据是增量抽取的关键。对捕获方法一般有两点要求:准确性,能够将业务系统中的变化数据按一定的频率准确地捕获到;性能,不能对业务系统造成太大的压力,影响现有业务。目前增量数据抽取中常用的捕获变化数据的方法有:
a) 触发器方式(又称快照式) 在要抽取的表上建立需要的触发器,一般要建立插入、修改、删除三个触发器,每当源表中的数据 发生变化,就被相应的触发器将变化的数据写入一个临时表,抽取线程从临时表中抽取数据,临时表中抽取过的数据被标记或删除。
优点:数据抽取的性能高,ETL 加载规则简单,速度快,不需要修改业务系统表结构,可以实现数据的递增加载。
缺点:要求业务表建立触发器,对业务系统有一定的影响,容易对源数据库构成威胁。
b) 时间戳方式 它是一种基于快照比较的变化数据捕获方式,在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值。当进行数据抽取时,通过比较上次抽取时间与时间戳字段的值来决定抽取哪些数据。有的数据库的时间戳支持自动更新,即表的其它字段的数据发生改变时,自动更新时间戳字段的值。有的数据库不支持时间戳的自动更新,这就要求业务系统在更新业务数据时,手工更新时间戳字段。
优点:同触发器方式一样,时间戳方式的性能也比较好,ETL 系统设计清晰,源数据抽取相对清楚简单,可以实现数据的递增加载。
缺点:时间戳维护需要由业务系统完成,对业务系统也有很大的倾入性(加入额外的时间戳字段),特别是对不支持时间戳的自动更新的数据库,还要求业务系统进行额外的更新时间戳操作;另外,无法捕获对时间戳以前数据的delete和update 操作,在数据准确性上受到了一定的限制。
c) 全表删除插入方式 每次ETL 操作均删除目标表数据,由ETL 全新加载数据。
优点:ETL 加载规则简单,速度快。
缺点:对于维表加外键不适应,当业务系统产生删除数据操作时,综合数据库将不会记录到所删除的历史数据,不可以实现数据的递增加载;同时对于目标表所建立的关联关系,需要重新进行创建。
d) 全表比对方式 全表比对的方式是ETL 工具事先为要抽取的表建立一个结构类似的临时表,该临时表记录源表主键以及根据所有字段的数据计算出来,每次进行数据抽取时,对源表和临时表进行的比对,如有不同,进行Update 操作,如目标表没有存在该主键值,表示该记录还没有,即进行Insert 操作。
优点:对已有系统表结构不产生影响,不需要修改业务操作程序,所有抽取规则由ETL完成,管理维护统一,可以实现数据的递增加载,没有风险。
缺点:ETL 比对较复杂,设计较为复杂,速度较慢。与触发器和时间戳方式中的主动通知不同,全表比对方式是被动的进行全表数据的比对,性能较差。当表中没有主键或唯一列且含有重复记录时,全表比对方式的准确性较差。
e) 日志表方式 在业务系统中添加系统日志表,当业务数据发生变化时,更新维护日志表内容,当作ETL 加载时,通过读日志表数据决定加载那些数据及如何加载。
优点:不需要修改业务系统表结构,源数据抽取清楚,速度较快。可以实现数据的递增加载。
缺点:日志表维护需要由业务系统完成,需要对业务系统业务操作程序作修改,记录日志信息。日志表维护较为麻烦,对原有系统有较大影响。工作量较大,改动较大,有一定风险。
f) Oracle 变化数据捕捉(CDC 方式) 通过分析数据库自身的日志来判断变化的数据。Oracle 的改变数据捕获(CDC,Changed Data Capture)技术是这方面的代表。CDC 特性是在Oracle9i 数据库中引入的。CDC 能够帮助你识别从上次抽取之后发生变化的数据。利用CDC,在对源表进行insert、update 或 delete 等操作的同时就可以提取数据,并且变化的数据被保存在数据库的变化表中。这样就可以捕获发生变化的数据,然后利用数据库视图以一种可控的方式提供给目标系统。CDC 体系结构基于发布/订阅模型。发布者捕捉变化数据并提供给订阅者。订阅者使用从发布者那里获得的变化数据。通常,CDC 系统拥有一个发布者和多个订阅者。发布者首先需要识别捕获变化数据所需的源表。然后,它捕捉变化的数据并将其保存在特别创建的变化表中。它还使订阅者能够控制对变化数据的访问。订阅者需要清楚自己感兴趣的是哪些变化数据。一个订阅者可能不会对发布者发布的所有数据都感兴趣。订阅者需要创建一个订阅者视图来访问经发布者授权可以访问的变化数据。CDC 分为同步模式和异步模式,同步模式实时的捕获变化数据并存储到变化表中,发布者与订阅都位于同一数据库中;异步模式则是基于Oracle 的流复制技术。
优点:提供了易于使用的API 来设置CDC 环境,缩短ETL 的时间。不需要修改业务系统表结构,可以实现数据的递增加载。
缺点:业务系统数据库版本与产品不统一,难以统一实现,实现过程相对复杂,并且需深入研究方能实现。或者通过第三方工具实现,价格昂贵。
衍生度量
选择 函数 -> 时间序列函数 -> ToDate
|
ToDate(《度量》,《级别》) |
选择 逻辑表 -> F-销售事实 -> 销售金额 替换ToDate(《度量》,《级别》)中的《度量》
选择 时间维 -> Dim-时间维 -> 月份 替换ToDate(《度量》,《级别》)中的《级别》
|
ToDate("ATData"."F-销售事实"."销售金额" , "ATData"."Dim_时间维"."月份" ) |
衍生度量 销售数量MTD:
|
ToDate("ATData"."F-销售事实"."销售数量" , "ATData"."Dim_时间维"."月份" ) |
衍生度量 销售金额QTD:
|
ToDate("ATData"."F-销售事实"."销售金额" , "ATData"."Dim_时间维"."季度" ) |
衍生度量 销售数量QTD:
|
ToDate("ATData"."F-销售事实"."销售数量" , "ATData"."Dim_时间维"."季度" ) |
衍生度量 销售金额YTD:
|
ToDate("ATData"."F-销售事实"."销售金额" , "ATData"."Dim_时间维"."年份" ) |
衍生度量 销售数量YTD:
|
ToDate("ATData"."F-销售事实"."销售数量" , "ATData"."Dim_时间维"."年份" ) |
衍生度量 销售数量去年同期:
|
Ago("ATData"."F-销售事实"."销售数量" , "ATData"."Dim_时间维"."年份" , 1) |
衍生度量 销售金额去年同期:
|
Ago("ATData"."F-销售事实"."销售金额" , "ATData"."Dim_时间维"."年份" , 1) |
衍生度量 销售数量MTD去年同期:
|
Ago("ATData"."F-销售事实"."销售数量MTD" , "ATData"."Dim_时间维"."月份" , 12) |
衍生度量 销售金额MTD去年同期:
|
Ago("ATData"."F-销售事实"."销售金额MTD" , "ATData"."Dim_时间维"."月份" , 12) |
衍生度量 销售数量QTD去年同期:
|
Ago("ATData"."F-销售事实"."销售数量QTD" , "ATData"."Dim_时间维"."季度" , 4) |
衍生度量 销售金额QTD去年同期:
|
Ago("ATData"."F-销售事实"."销售金额QTD" , "ATData"."Dim_时间维"."季度" , 4) |
衍生度量 销售数量YTD去年同期:
|
Ago("ATData"."F-销售事实"."销售数量YTD" , "ATData"."Dim_时间维"."年份" , 1) |
衍生度量 销售金额YTD去年同期:
|
Ago("ATData"."F-销售事实"."销售金额YTD" , "ATData"."Dim_时间维"."年份" , 1) |
衍生度量 销售数量MTD上期:
|
Ago("ATData"."F-销售事实"."销售金额MTD" , "ATData"."Dim_时间维"."月份" , 1) |
衍生度量 销售数量MTD上期:
|
Ago("ATData"."F-销售事实"."销售数量MTD" , "ATData"."Dim_时间维"."月份" , 1) |
衍生度量 销售数量MTD环比增长率:
|
("ATData"."F-销售事实"."销售数量MTD" /"ATData"."F-销售事实"."销售数量MTD上期" -1) * 100 |
衍生度量 销售金额MTD环比增长率:
|
("ATData"."F-销售事实"."销售金额MTD" /"ATData"."F-销售事实"."销售金额MTD上期" -1) * 100 |
衍生度量 销售数量MTD同比增长率:
|
("ATData"."F-销售事实"."销售数量MTD" /"ATData"."F-销售事实"."销售数量MTD去年同期" -1)*100 |
衍生度量 销售金额MTD同比增长率:
|
("ATData"."F-销售事实"."销售金额MTD" /"ATData"."F-销售事实"."销售金额MTD去年同期" -1)*100 |
衍生度量 销售数量QTD同比增长率:
|
("ATData"."F-销售事实"."销售数量QTD" /"ATData"."F-销售事实"."销售数量QTD去年同期" -1)*100 |
衍生度量 销售金额QTD同比增长率:
|
("ATData"."F-销售事实"."销售金额QTD" /"ATData"."F-销售事实"."销售金额QTD去年同期" -1)*100 |
衍生度量 销售数量YTD同比增长率:
|
("ATData"."F-销售事实"."销售数量YTD" /"ATData"."F-销售事实"."销售数量YTD去年同期"-1)*100 |
衍生度量 销售金额YTD同比增长率:
|
("ATData"."F-销售事实"."销售金额YTD" /"ATData"."F-销售事实"."销售金额YTD去年同期"-1)*100 |

 Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM
Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM译者 | 李睿审校 | 孙淑娟随着Python越来越受欢迎,其局限性也越来越明显。一方面,编写Python应用程序并将其分发给没有安装Python的人员可能非常困难。解决这一问题的最常见方法是将程序与其所有支持库和文件以及Python运行时打包在一起。有一些工具可以做到这一点,例如PyInstaller,但它们需要大量的缓存才能正常工作。更重要的是,通常可以从生成的包中提取Python程序的源代码。在某些情况下,这会破坏交易。第三方项目Nuitka提供了一个激进的解决方案。它将Python程序编
 ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PM
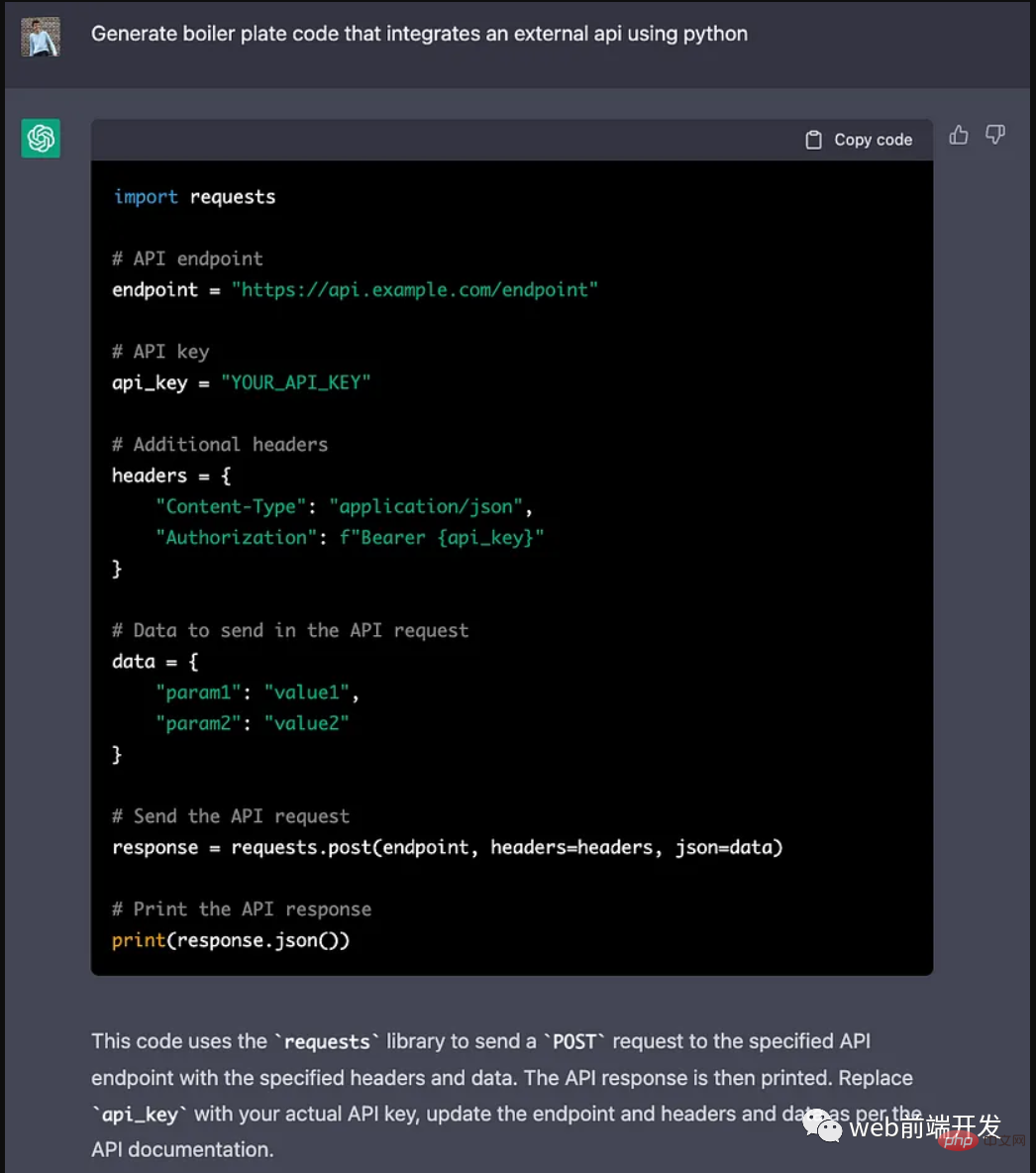
ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PMChatGPT 目前彻底改变了开发代码的方式,然而,大多数软件开发人员和数据专家仍然没有使用 ChatGPT 来改进和简化他们的工作。这就是为什么我在这里概述 5 个不同的功能,以提高我们的日常工作速度和质量。我们可以在日常工作中使用它们。现在,我们一起来了解一下吧。注意:切勿在 ChatGPT 中使用关键代码或信息。01.生成项目代码的框架从头开始构建新项目时,ChatGPT 是我的秘密武器。只需几个提示,它就可以生成我需要的代码框架,包括我选择的技术、框架和版本。它不仅为我节省了至少一个小时
 我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM
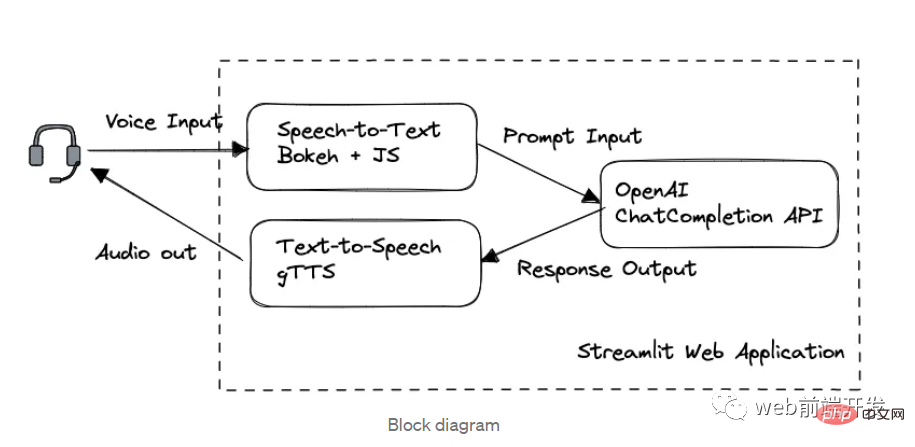
我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM今天这篇文章的重点是使用 ChatGPT API 创建私人语音 Chatbot Web 应用程序。目的是探索和发现人工智能的更多潜在用例和商业机会。我将逐步指导您完成开发过程,以确保您理解并可以复制自己的过程。为什么需要不是每个人都欢迎基于打字的服务,想象一下仍在学习写作技巧的孩子或无法在屏幕上正确看到单词的老年人。基于语音的 AI Chatbot 是解决这个问题的方法,就像它如何帮助我的孩子要求他的语音 Chatbot 给他读睡前故事一样。鉴于现有可用的助手选项,例如,苹果的 Siri 和亚马
 解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM
解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM测试时自适应(Test-TimeAdaptation,TTA)方法在测试阶段指导模型进行快速无监督/自监督学习,是当前用于提升深度模型分布外泛化能力的一种强有效工具。然而在动态开放场景中,稳定性不足仍是现有TTA方法的一大短板,严重阻碍了其实际部署。为此,来自华南理工大学、腾讯AILab及新加坡国立大学的研究团队,从统一的角度对现有TTA方法在动态场景下不稳定原因进行分析,指出依赖于Batch的归一化层是导致不稳定的关键原因之一,另外测试数据流中某些具有噪声/大规模梯度的样本
 摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM
摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM哈喽,大家好。之前给大家分享过摔倒识别、打架识别,今天以摔倒识别为例,我们看看能不能完全交给ChatGPT来做。让ChatGPT来做这件事,最核心的是如何向ChatGPT提问,把问题一股脑的直接丢给ChatGPT,如:用 Python 写个摔倒检测代码 是不可取的, 而是要像挤牙膏一样,一点一点引导ChatGPT得到准确的答案,从而才能真正让ChatGPT提高我们解决问题的效率。今天分享的摔倒识别案例,与ChatGPT对话的思路清晰,代码可用度高,按照GPT返回的结果完全可以开
 17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM
17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM自 2020 年以来,内容开发领域已经感受到人工智能工具的存在。1.Jasper AI网址:https://www.jasper.ai在可用的 AI 文案写作工具中,Jasper 作为那些寻求通过内容生成赚钱的人来讲,它是经济实惠且高效的选择之一。该工具精通短格式和长格式内容均能完成。Jasper 拥有一系列功能,包括无需切换到模板即可快速生成内容的命令、用于创建文章的高效长格式编辑器,以及包含有助于创建各种类型内容的向导的内容工作流,例如,博客文章、销售文案和重写。Jasper Chat 是该
 为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM
为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM1970年,机器人专家森政弘(MasahiroMori)首次描述了「恐怖谷」的影响,这一概念对机器人领域产生了巨大影响。「恐怖谷」效应描述了当人类看到类似人类的物体,特别是机器人时所表现出的积极和消极反应。恐怖谷效应理论认为,机器人的外观和动作越像人,我们对它的同理心就越强。然而,在某些时候,机器人或虚拟人物变得过于逼真,但又不那么像人时,我们大脑的视觉处理系统就会被混淆。最终,我们会深深地陷入一种对机器人非常消极的情绪状态里。森政弘的假设指出:由于机器人与人类在外表、动作上相似,所以人类亦会对
 如何使用Azure Bot Services创建聊天机器人的分步说明Apr 11, 2023 pm 06:34 PM
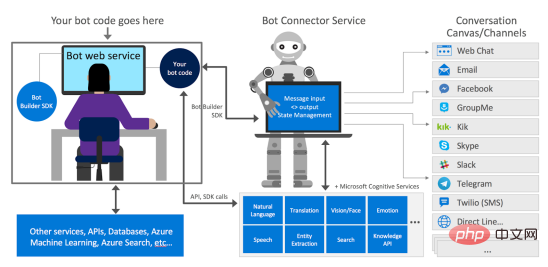
如何使用Azure Bot Services创建聊天机器人的分步说明Apr 11, 2023 pm 06:34 PM译者 | 李睿审校 | 孙淑娟信使、网络服务和其他软件都离不开机器人(bot)。而在软件开发和应用中,机器人是一种应用程序,旨在自动执行(或根据预设脚本执行)响应用户请求创建的操作。在本文中, NIX United公司的.NET开发人员Daniil Mikhov介绍了使用微软Azure Bot Services创建聊天机器人的一个例子。本文将对想要使用该服务开发聊天机器人的开发人员有所帮助。 为什么使用Azure Bot Services? 在Azure Bot Services上开发聊


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

Dreamweaver Mac version
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

Notepad++7.3.1
Easy-to-use and free code editor

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

