


1. 前言 SQL Server 2005开始支持表 分区 ,这种技术允许所有的表 分区 都保存在同一台服务器上。每一个表 分区 都和在某个文件组(filegroup)中的单个文件关联。同样的一个文件/文件组可以容纳多个 分区 表。在这种设计架构下,数据库引擎能够判定查询过程中
1. 前言
SQL Server 2005开始支持表分区,这种技术允许所有的表分区都保存在同一台服务器上。每一个表分区都和在某个文件组(filegroup)中的单个文件关联。同样的一个文件/文件组可以容纳多个分区表。在这种设计架构下,数据库引擎能够判定查询过程中应该访问哪个分区,而不用扫描整个表。如果查询需要的数据行分散在多个分区中,SQL Server使用多个处理器对多个分区进行并行查询。你可以为在创建表的时候就定义分区的索引。对小索引的搜索或者扫描要比扫描整个表或者一张大表上的索引要快很多。因此,当对大表进行查询,表分区可以产生相当大的性能提升通过分别检查同一条返回所有行的、简单SELECT语句在分区表和非分区表上的执行计划,返回的数据范围通过WHERE语句来指定。同一条语句在这两个不同的表上有不同的执行计划。对于分区表的查询显示出一个嵌套的循环和索引的扫描。从本质上来说,SQL Server将两个分区视为独立的表,因此使用一个嵌套循环将它们连接起来。对非分区的表的同一个查询则使用索引扫描来返回同样的列。当你使用同样的分区策略创建多个表,同时在查询中连接这些表,那么性能上的提升会更加明显。
2. 分区三步曲
SQL Server数据库表分区操作过程由三个步骤组成
2.1. 创建分区函数
2.1.1. 创建文件组,一般文件组个数=分区值个数+1
alter database [mydatabase] --创建文件组1 |
2.1.2. 为数据库创建文件
一个文件不能属于两个文件组,一个文件组可以包含多个文件,可以同时指定初始化大小及
增长大小。
alter database [mydatabase] |
2.1.3. 创建分区函数
此分区函数用于定义你希望SQL Server如何对数据进行分区的参数值(how)。这个操作并不涉及任何表格,只是单纯的定义了一项技术来分割数据.
|
create partition function 注意: 这里使用了右分区则表示分区取值范围为 属于第一分区 〉=10000 And 属于第二分区 〉=20000属于第三分区 |
2.2. 创建分区架构
一旦给出描述如何分割数据的分区函数,接着就要创建一个分区架构,用来定义分区位置(where)。
create partition scheme |
2.3. 对表进行分区
定义好一个分区架构后,就可以着手创建一个分区表了。只需要在表创建指令中添加一个
"ON"语句,用来指定分区架构以及应用该架构的表列。因为分区架构已经识别了分区函数,
所以不需要再指定分区函数了。
create table [dbo].[tb_partition1]( |
2.4. 填充测试数据,并进行合并与删除操作
2.4.1. 填充数据
insert tb_partition1 default values |
2.4.2. 查看数据分区状况
select |
2.4.3. 切换分区
alter table [dbo].[tb_partition1] |
2.4.4. 修改分区架构和分区函数
alter partition scheme [sch_tb_partition_id] |
3. 表分区注意事项
3.1. 表分区边界值问题
使用left和right时候需要注意,特别是时间分割上,通常使用以00:00:00.000最可靠,这种分割需要使用right如果使用left需要设置为23:59:59.997。
3.2. 分区值第一个值
符合这个值之前的值会被分配到第一个分区中,使用left和right的区别就是这个分区值是被分配到第一个分区还是第二个分区。
3.3. 通常情况会以ID(自增)或时间字段作为分区字段
这样的好处就是容易区分历史数据库,而且对分区操作隔离也是最明显的。
3.4. 索引分区
对聚集索引进行分区时,聚集键必需包含分区依据列。
对于非唯一的聚集索引进行分区时,如果未在聚集索引键中指定分区依据列,默认情况下SQLServer将在聚集索引键列表中添加分区依据列。如果聚集索引是唯一的,则必需明确指定聚集索引键包含分区依据列。
对唯一的非聚集索引进行分区时,索引键必需包含分区依据列,对非唯一的非聚集索引进行分区,默认情况下SQLServer将分区依据列添加为索引的非键列(包含性列),以确保索引与基表对齐。
3.5. 删除分区
删除的这个边界值属于哪个分区就会删除这个分区,再向临近(以这个边界值为临界点的两个分区)的分区合并。
3.6. 索引对齐
索引对齐:如果你想让数据分开到不同的文件可以使用两个不同的分区方案,使用同一分区函数。
存储位置对齐:数据和索引位于同一文件中
4. 动态生成分区脚本
|
--分区脚本 --定义变量 |

 SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM
SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM本篇文章给大家带来了关于SQL的相关知识,其中主要介绍了SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询的方法,文中通过示例代码介绍的非常详细,下面一起来看一下,希望对大家有帮助。
 SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM
SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM本篇文章给大家带来了关于SQL server的相关知识,其中主要介绍了SQL SERVER没有自带的解析json函数,需要自建一个函数(表值函数),下面介绍关于SQL Server解析/操作Json格式字段数据的相关资料,希望对大家有帮助。
 聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM
聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM如何优化sql中的orderBy语句?下面本篇文章给大家介绍一下优化sql中orderBy语句的方法,具有很好的参考价值,希望对大家有所帮助。
 Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PM
Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i
 一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM
一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM本篇文章给大家带来了关于SQL server的相关知识,开窗函数也叫分析函数有两类,一类是聚合开窗函数,一类是排序开窗函数,下面这篇文章主要给大家介绍了关于SQL中开窗函数的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下。
 如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM
如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM0x01前言概述小编又在MySQL中发现了一个Double型数据溢出。当我们拿到MySQL里的函数时,小编比较感兴趣的是其中的数学函数,它们也应该包含一些数据类型来保存数值。所以小编就跑去测试看哪些函数会出现溢出错误。然后小编发现,当传递一个大于709的值时,函数exp()就会引起一个溢出错误。mysql>selectexp(709);+-----------------------+|exp(709)|+-----------------------+|8.218407461554972
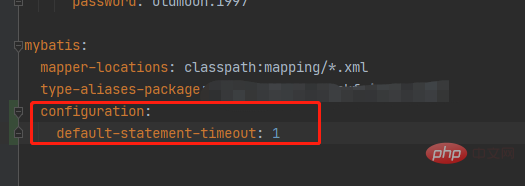 springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM
springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM当某些sql因为不知名原因堵塞时,为了不影响后台服务运行,想要给sql增加执行时间限制,超时后就抛异常,保证后台线程不会因为sql堵塞而堵塞。一、yml全局配置单数据源可以,多数据源时会失效二、java配置类配置成功抛出超时异常。importcom.alibaba.druid.pool.DruidDataSource;importcom.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;importorg.apache.
 Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PM
Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Zend Studio 13.0.1
Powerful PHP integrated development environment

SublimeText3 Chinese version
Chinese version, very easy to use

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

