
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
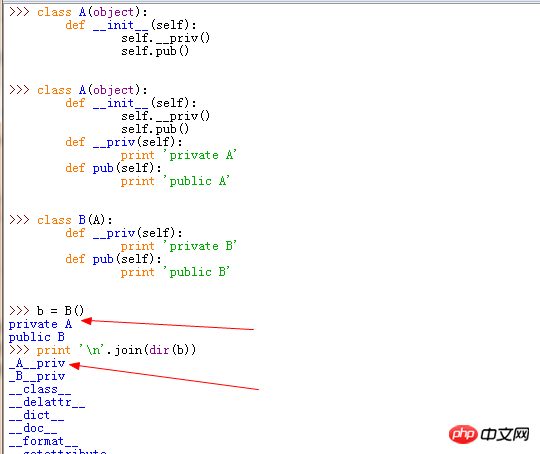
如图所示,B 类继承了 A 类;
当实例化对象时,B 类中没有构造函数, 应该调用父类的构造函数 __init__
但是里边的 self.__pirv() 为啥调用到父类 A 的 __priv, 而 self.pub() 又调到 B 中的 pub
求解?

ringa_lee2017-04-18 10:30:50
在Python从__开始的方法名称不是private,__的意思就让Python做name mangling,name mangling的结果就是_A__priv。这样的方法你应该不要overwrite。如果你想让子类overwrite一个方法你只用_,不用__

大家讲道理2017-04-18 10:30:50
想了一下这个问题,我是这样理解的:
class A(object):
def __init__(self):
self.__priv() # _A__priv()
self.pub()
def __priv(self):
print("private A")
def pub(self):
print("public A")
class B(A):
def __init__(self):
self.__priv() # 调用_B__priv()对比
super(B, self).__init__() # 在这里显式调用父类的`__init__()`方法
def __priv(self):
print("private B")
def pub(self):
print("public B")
if __name__ == '__main__':
b = B()在子类的实例调用__init__()方法时,从子类B本身中查找pub()方法,显然是存在的,因此会调用B类自身的pub()方法;然而在调用__priv()方法时,由于Python对私有成员进行了名称改编,你实际调用的是_A__priv()方法,而B类中并没有这个方法,有的只有_B__priv(),因此调用父类A中的_A__priv(),于是产生了这样的结果。这是我个人的理解,如果有误欢迎指正,谢谢。
巴扎黑2017-04-18 10:30:50
關於問題本身, @Xavier 和 @Christoph 已經有詳細的說明了
如果你還不明白可以試著這樣做:
原本的代碼:
class A:
def __init__(self):
self.__priv() # 等等改成 self._A__priv()
self.public()
def __priv(self): # 等等改成 def _A__priv(self):
print('private of A')
def public(self):
print('public of A')
class B(A):
def __priv(self): # 等等改成 self._B__priv(self):
print('private of B')
def public(self):
print('public of B')
b = B()自行手動進行 name mangling:
class A:
def __init__(self):
self._A__priv()
self.public()
def _A__priv(self):
print('private of A')
def public(self):
print('public of A')
class B(A):
def _B__priv(self):
print('private of B')
def public(self):
print('public of B')
b = B()B 在這裡繼承了 A 的所有屬性包含:
__init__
_A__priv
public
而 B 自己定義了:
_B__priv
public (此處覆寫了 A 的 public)
所以最後你會看到 dir(b) 裡面有:
__init__ (從 A 繼承的)
_A__priv (從 A 繼承的)
_B__priv (自己定義的)
public (自己定義的)
最後當 __init__ 被呼叫時, 會調用 _A__priv, 而 B 裡面的確有這個方法
囉唆補充一下, Python 本身並沒有真正的 private 機制, 因為了解 name mangling 的人就能對以雙底線開頭的屬性做存取, 比如說我可以很輕易地寫出:
a = A()
a._A__priv() # 防都防不住簡單來說這個機制是個:
防呆 的機制, 不是個 防小人 的機制,
防止意外 存取的機制, 不是個防止 刻意存取 的機制
但是這個機制並非所有人都覺得好(個人就不喜歡, 使用雙底線開頭命名既麻煩也沒太多實際的幫助), 所以你可以在很多的 python 代碼中發現: 大家比較常使用以 單個底線 開頭的保護方式, 這種做法是個公認的慣例(註1), 對於稍有經驗的程序員來說足以防呆, 且不會有任何額外的效果和意外的狀況發生
Ian Bicking 有一段話是這樣說的 (Ian Bicking 是 Python 大神, 這段話我是在 Luciano Ramalho 的的 Fluent Python 中看到的):
永遠不要在前面使用兩個底線. 這是很讓人生氣的自私行為, 如果你不希望造成名稱衝突(註2), 可以明確地重整名稱(例如: _MyThing_blahblah). 實質上這與使用雙底線是同一件事情, 不過他是公開的, 雙底線是私下的行為.
所以我的建議是, 使用 _priv 會是更好的選擇.
註1: 以單底線開頭的屬性不會具有任何特殊的性質, 他僅僅是依靠 Python 程序員的共識而產生的具有象徵意義的符號性手法, 就好像有些語言會使用 const 來標明常量, 而我們也可以僅依賴 常量使用大寫命名 的共識來避免意外的狀況發生
註2: 之所以想要以 private 性質來保護屬性, 最常見的就是因為名稱衝突引起的意外存取
我回答過的問題: Python-QA
