Heim > Fragen und Antworten > Hauptteil
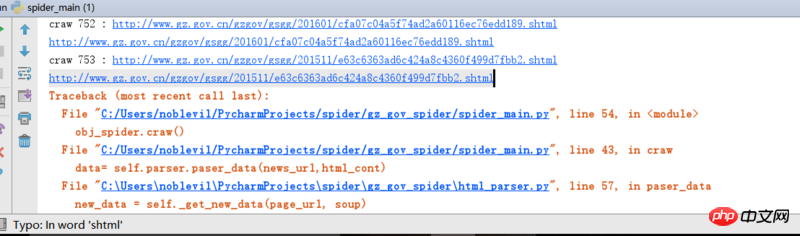
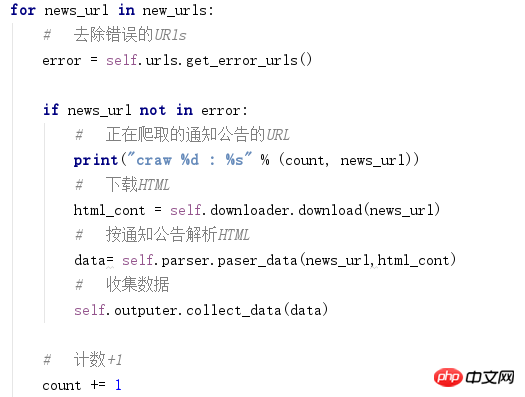
1.抓取到一个错误的URl
2.我的比蠢笨的办法:
伊谢尔伦2017-04-18 10:23:58
curl里面有个可以设置返回header的,如果取到的数据非200状态,直接跳过处理就好了。