
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
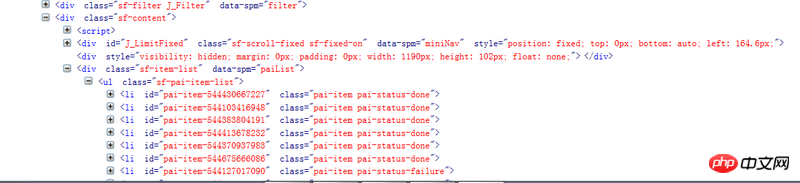
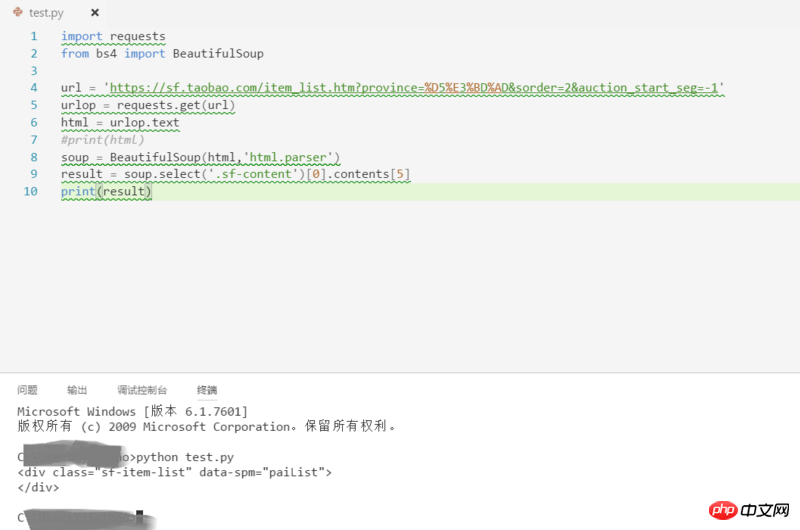
待解析页面的部分代码如第一幅图所示,我自己写的代码及运行结果如第二幅图所示。看到已经有答主提问解析页面丢失是因为用的是lxml的解析方式,我想说我一直用的是html.parser的方式。希望各位大神不吝赐教~


伊谢尔伦2017-04-18 10:20:51
题主,如果你用Chrome F12看的话,里面是会有动态加载的内容的,而这些内容你直接请求页面的url是拿不到的。建议你点右键查看网页源代码,对照着F12里面的内容来看,源代码里没有的内容,就去查看Network里的其他请求,看有没有你需要的数据。
