
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
http://apk.hiapk.com/appinfo/...
我想要爬取这个网页中的用户评论
但是却发现使用urllib2.urlopen(request)获取的html页面不完整
代码如图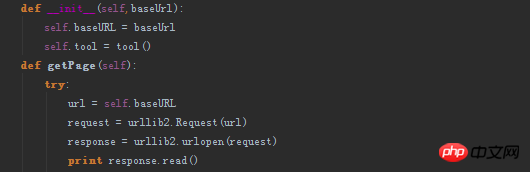

输出如图
但是实际上这个页面里面是有东西的
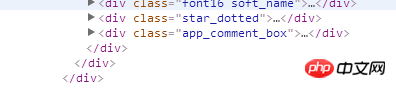
请问一下为什么获取到的html不全呢

PHP中文网2017-04-18 09:58:27
不是获取不全,这个页面的评论 是通过javascript后期加载生成的,urllib2.urlopen中返回请求的html,并不会执行页面中的javascript
你直接请求 http://apk.hiapk.com/web/api.... 这个地址就可以返回所有评论了,还是json的,好处理的很
