
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
文件如下:
import socket
HOST, PORT = '127.0.0.1', 8888
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(1)
print ('Serving HTTP on port %s ...' % PORT)
while True:
client_connection, client_address = listen_socket.accept()
request = client_connection.recv(1024)
print (request.decode('utf-8'))
http_response = """
HTTP/1.1 200 OK
Hello, World!
""".encode("utf-8")
client_connection.sendall(http_response)
client_connection.close()
其中的 print (request.decode('utf-8'))不加decode()还能运行,一转码不管decode()括号里面写任何东西或者空着就会报错。。
错误如下所示: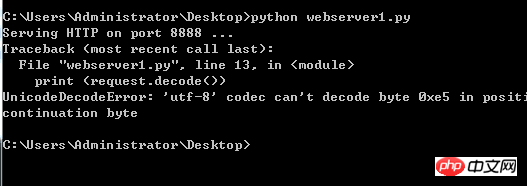
websercer1.py文件我确定是utf-8编码格式的,真心不知道这是什么回事了。。
哪位知道麻烦告知,拜谢。。。

阿神2017-04-18 09:23:47
decode 是解码.
不关websercer1.py文件编码的事情.
request.decode('编码') #指的是请求过来你用什么编码来解码...
你那个错误可能 传过来就已经是UTF-8的编码了

伊谢尔伦2017-04-18 09:23:47
虽然你很确定是utf-8编码,但建议你先保存到txt文件中看看
我爬数据经常用的一个笨方法就是先把东西无脑写进txt里,看看里面是什么,这样比较好debug
import codecs
with codecs.open('abc.txt','w','utf-8') as f:
#do your encode decode
f.write(request) # 可能是request.content? request.text?
#then do something with abc.txt如果用codecs的utf-8形式无法保存为txt,那你的内容就应该不是utf-8的了

迷茫2017-04-18 09:23:47
你的编码原本就是utf-8的,不需要encode,decode。那个encode就是多余的,(并且你也写错了,需要先decode,再encode,所以是多余的)
http_response = """HTTP/1.1 200 OK Hello, World!""".decode('utf-8').encode("utf-8")
最后运行不出来,可能是socket代码写的有问题了,你再检查检查
