
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
结构数据是这样的:
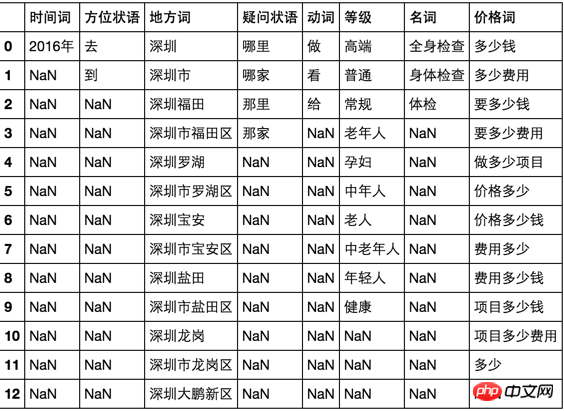
要求按照这样的公式:组合一: 时间词+地方词+动词+等级+名词+价格词;
比如
2016年深圳大鹏新区给健康全身检查要多少钱
就是按照这样的公式组合出来的关键词
那么有什么办法用最短的办法来实现,我下面是我的算法,用pandas的算法:
for times in df[df["时间词"].notnull()]["时间词"]:
for area in df[df["地方词"].notnull()]["地方词"]:
for dong in df[df["动词"].notnull()]["动词"]:
for leave in df[df["等级"].notnull()]["等级"]:
for name in df[df["名词"].notnull()]["名词"]:
for price in df[df["价格词"].notnull()]["价格词"]:
data = (times+area+dong+leave+name+price)但是这样的代码太不优雅,而且封装成函数太难~
我想要的效果是这样的:
比如:
我写一个公式
cols = ["时间词","地方词","动词","等级","名词","价格词"]
#或则是
cols = ["地方词","动词","等级","名词","价格词"]然后把这个列表传入一个函数中,就可以得出我上面的效果~
这个要如何实现?
补充一下,如果看不懂提问的人可以这样理解这个题目
我有3个列表:
a = ["1","2","3","4","5"]
b = ["a","b","c"]
c = ["A","B"]我要这样的组合: a中的每个元素和b,c中的每个元素都进行组合
这个一个很简单的多重循环就可以解决:
for A in a:
for B in b:
for C in c:
print (A+B+C)这当然很简单,但是假如我有10000个这样的列表要重组?
难不成要手工复制黏贴每个循环10000次?这显然不太现实
在python中有没有比较好的函数或是比较好的方法来实现这个东西?
Taku的解答.完全符合需求附上我修改后的代码
import itertools
def zuhe(cols):
b = pd.Series()
for col in cols:
b = b.append(pd.Series({col:list(df[df[col].notnull()][col])}))
for x in itertools.product(*(b.values)):
print (x)
zuhe(cols = ["时间词","地方词","动词"])只需要传入需要组合的列表词,就可以得到结果!!
巴扎黑2017-04-18 09:07:34
试试itertools
import itertools
for x in itertools.product([1,2,3,4],[2,3,4],[1,1,2,2,3,3]):
print x哈哈,其实就是一个求笛卡尔积的问题
要学会组织关键词,善用搜索

高洛峰2017-04-18 09:07:34
我來表演 重複發明輪子:
一個用 iteration 的版本:
def product(*iterables):
START = 0
END = 1
se_idxs = [(0, len(iterable)) for iterable in iterables]
curr_idxs = [0 for iterable in iterables]
def next():
curr_idxs[-1] += 1
for k in reversed(range(len(iterables))):
if curr_idxs[k]==se_idxs[k][END]:
if k==0:
return False
curr_idxs[k] = 0
curr_idxs[k-1] += 1
else:
break
return True
while True:
yield [iterable[idx] for idx, iterable in zip(curr_idxs, iterables)]
if not next():
return一個 recursive 的版本:
def product_core(result, *iterables):
if len(iterables)==0:
yield result
else:
for item in iterables[0]:
yield from product_core(result+[item], *iterables[1:])
def product(*iterables):
return product_core([], *iterables)測試:
a = [1, 2, 3]
b = [4, 5, 6]
c = [7, 8, 9]
for p in product(a, b, c):
print(p)結果:
[1, 4, 7]
[1, 4, 8]
[1, 4, 9]
[1, 5, 7]
[1, 5, 8]
[1, 5, 9]
[1, 6, 7]
[1, 6, 8]
[1, 6, 9]
[2, 4, 7]
[2, 4, 8]
[2, 4, 9]
[2, 5, 7]
[2, 5, 8]
...人生苦短 別傻傻的自己做重複的事情啊...
我回答過的問題: Python-QA

天蓬老师2017-04-18 09:07:34
列表生成式可以吗?
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']