- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
写了个爬取手机信息的爬虫,用beautifulsoup解析。查了下资料,发现beautifulsoup最后输出是以unicode编码,把爬取的图片名放入一变量后,该变量不能作为新建文件的文件名。
网站地址 http://product.pconline.com.cn/mobile/
部分代码
import requests
from bs4 import BeautifulSoup
url = 'http://product.pconline.com.cn/mobile/'
header = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0"
}
response = requests.get(url, headers=header)
html = response.text
soup = BeautifulSoup(html, 'html5lib')
items = soup.find_all('p', class_='item-pic')
#对解析出来的每款手机模拟点击,提取手机名字和手机图片
for item in items:
name = item.a.img.get('alt')
link = item.a.get('href')
print name, link
product_page = requests.get(link)
soup2 = BeautifulSoup(product_page.text, 'html5lib')
pic_link = soup2.find_all('img', width="360", height="270", limit=1)[0]
print pic_link
pic_src = pic_link['#src']
pic_name = pic_link['alt']
print pic_src, pic_name #pic_name是从soup2中提取的手机名,pic_src是图片url
# Save the picture
pic = requests.get(pic_src)
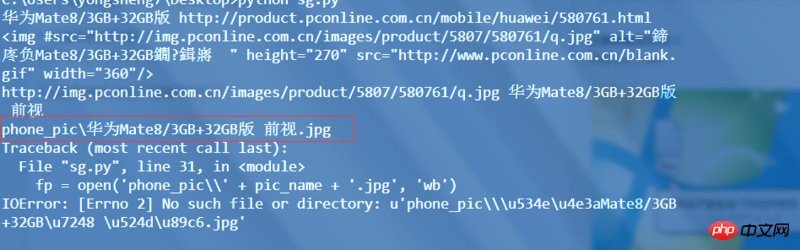
fp = open('phone_pic\\' + pic_name + '.jpg', 'wb')
fp.write(pic.content)
fp.close()运行的结果是无法对文件进行写操作。
报错信息:
fp = open('phone_pic\\' + pic_name + '.jpg', 'wb')
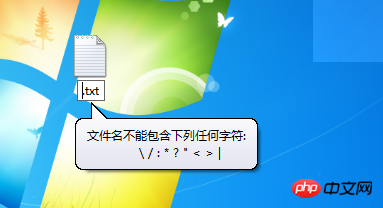
IOError: [Errno 2] No such file or directory: u'phone_pic\\\u534e\u4e3aMate8/3GB+32GB\u7248 \u524d\u89c6.jpg'可以看到是pic_name的中文仍然是Unicode编码。而打印print默认的编码是utf-8,可以成功输出中文。那么怎么把pic_name这些Unicode字符串转换成写操作可以接受的编码?

ringa_lee2017-04-17 17:48:45
pic_name = pic_name.encode("utf-8")注意你的文件名!
你的pic_name:
而windows下文件名要求: