web - python requests库登录网站脚本 登录失败
想写一个自动登录脚本,拿V2EX做实验。首先分析了下登录提交的表单:
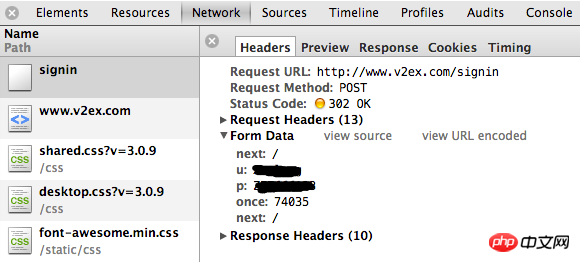
需要分析登陆界面中的html取出next,once,next值,分别为input_next_value_pre、input_once_value、input_next_value_post, 然后用requests请求页面,主要代码如下:
signin_url = "http://www.v2ex.com/signin"
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) \
AppleWebKit/537.31 (KHTML, like Gecko) \
Chrome/26.0.1410.65 Safari/537.31"
headers = {"User-Agent": user_agent}
logininfo = {"next": input_next_value_pre,
"u": usr_name,
"p": passwd,
"once": input_once_value,
"next": input_next_value_post
}
signin_req = requests.post(signin_url,
data=logininfo,
headers=headers,
)
但是响应信息signin_req.content显示并没有成功登录。谁能解释一些这个是为什么呢?
怀疑是v2ex的登录表单中有两个next字段,并且值一样,这样构建post字典第二个next就被忽略,不知道该怎么解决呢?




