
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
Ich habe gerade gelernt, JSON-Inhalte abzurufen, aber die Website, die ich heute gecrawlt habe, gibt keine JSON-Inhalte zurück und nach jedem Anforderungslink wird eine Zufallszahl generiert
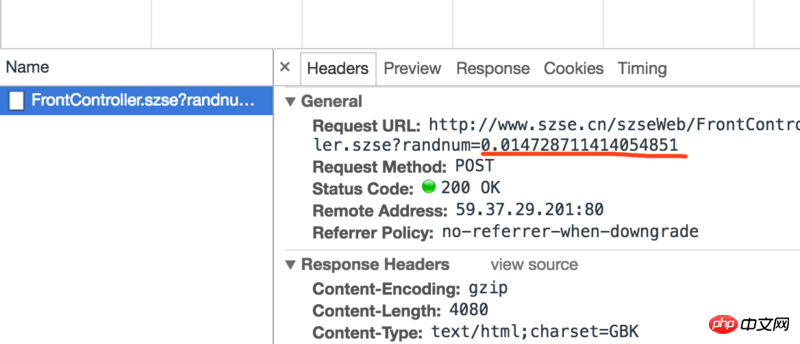
Ich weiß nicht, ob es Auswirkungen auf den Inhalt hat, den ich crawlen möchte
Der Inhalt, den Sie benötigen, ist der Inhalt in der Mitte des Bildes unten
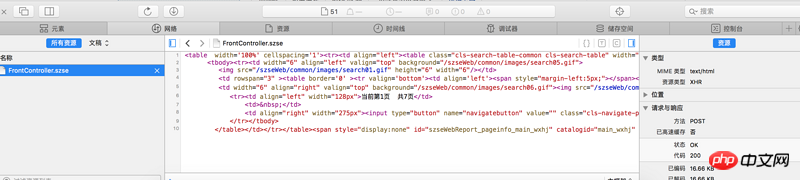
Website-Link http://www.szse.cn/main/discl...
Code, den ich selbst ausprobiert habe:
import requests
dir = '/Users/S1Lence/Desktop/new_html/szse/许可类重组问询函'
headers = {'Host': 'www.szse.cn',
'Referer': 'http://www.szse.cn/main/disclosure/jgxxgk/wxhj/',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36'
}
payload= {'ACTIONID': '7',
'AJAX': 'AJAX-TRUE',
'CATALOGID': 'main_wxhj',
'TABKEY': 'tab1',
'selecthjlb': '许可类重组问询函',
'tab1PAGENO': '1',
'tab1PAGECOUNT': '7',
'tab1RECORDCOUNT': '63',
'REPORT_ACTION': 'navigate'}
res = requests.post('http://www.szse.cn/szseWeb/FrontControllere', data=payload)
print(res.text)
Der Ausgabeinhalt entspricht nicht meinen Wünschen. Wie soll ich crawlen?

