
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
Website: https://www.nvshens.com/g/22377/. Öffnen Sie die Website direkt mit dem Browser und klicken Sie dann mit der rechten Maustaste auf das Bild, um es herunterzuladen. Dann wurde das von meinem Crawler direkt angeforderte Bild blockiert Dann habe ich die Header geändert und einen IP-Proxy eingerichtet, aber es hat immer noch nicht funktioniert. Aber wenn man sich die Paketerfassung ansieht, handelt es sich nicht um dynamisch geladene Daten! ! ! Bitte antworten Sie = =
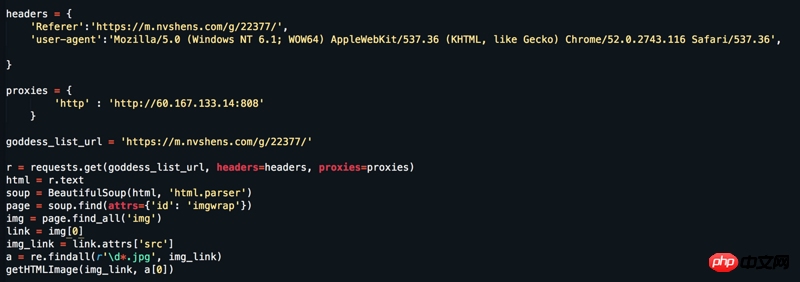
过去多啦不再A梦2017-06-12 09:29:51
妹子挺漂亮的哈。
右键确实能打开,但是刷新一下就成盗链图片了。一般防盗链,服务器端是会检查请求头里面的Referer字段,这就是为什么刷新后就不是原图的原因(刷新后Referer变了)。
img_url = "https://t1.onvshen.com:85/gallery/21501/22377/s/003.jpg"
r = requests.get(img_url, headers={'Referer':"https://www.nvshens.com/g/22377/"}).content
with open("00.jpg",'wb') as f:
f.write(r)

女神的闺蜜爱上我2017-06-12 09:29:51
Referer 照这网站的设计应该是各别的页面会比较符合假装是人的行为,而并不是用单一的Referer
以下是完整能跑的代码,抓18页所有的图片
# Putting all together
def url_guess_src_large (u):
return ("https://www.nvshens.com/img.html?img=" + '/'.join(u.split('/s/')))
# 下载函数
def get_img_using_requests(url, fn ):
import shutil
headers ['Referer'] = url_guess_src_large(url) #"https://www.nvshens.com/g/22377/"
print (headers)
response = requests.get(url, headers = headers, stream=True)
with open(fn, 'wb') as out_file:
shutil.copyfileobj(response.raw, out_file)
del response
import requests
# 用xpath擷取內容
from lxml import etree
url_ = 'https://www.nvshens.com/g/22377/{p}.html'
headers = {
"Connection" : "close", # one way to cover tracks
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2900.1 Iron Safari/537.36}"
}
for i in range(1,18+1):
url = url_.format(p=i)
r = requests.get(url, headers=headers)
html = requests.get(url,headers=headers).content.decode('utf-8')
selector = etree.HTML(html)
xpaths = '//*[@id="hgallery"]/img/@src'
content = [x for x in selector.xpath(item)]
urls_2get = [url_guess_src_large(x) for x in content]
filenames = [os.path.split(x)[0].split('/gallery/')[1].replace("/","_") + "_" + os.path.split(x)[1] for x in urls_2get]
for i, x in enumerate(content):
get_img_using_requests (content[i], filenames[i])
