
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
Jedes Mal, wenn es etwa eine halbe Stunde läuft, friert es sofort ein. Es gibt keinen Fehler im Protokoll. Wenn es einfriert, ist die CPU-Auslastung sehr hoch
Ich habe das Download-Timeout in Setting.py festgelegt, aber das ist nicht der Grund für das TimeoutStrg-C kann nicht normal beendet werden, das gleiche Problem bleibt bestehen, wenn die Ausführung nach einer halben Stunde wieder einfriert
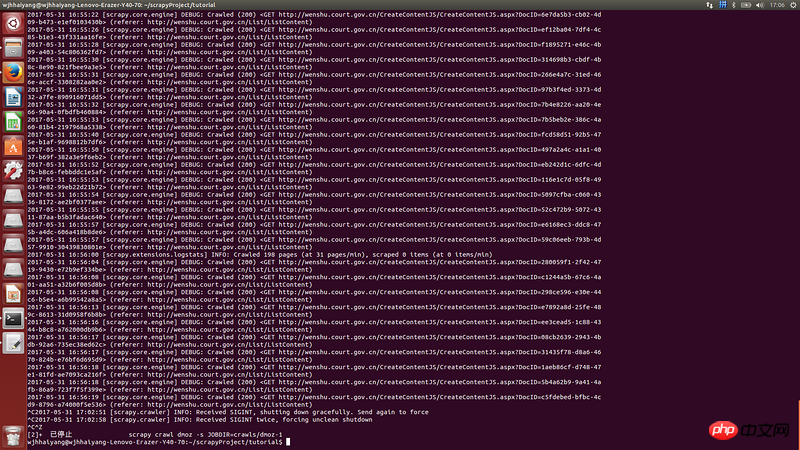

高洛峰2017-06-12 09:29:08
先TOP看看是内否过高,还是CPU过高,再找到是被哪些进程占用了
如果都是你的爬虫进程,那就得排查代码,看看是不是哪里一直未被释放
总之从各方面去排查吧
