
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
Ich möchte den vollständigen Inhalt unter dem Tag a unter h3 erhalten (Ersparnis von 5 % auf Ripleys Believe It or Not London-Tickets). Wie kann ich das mit xpath erhalten? Bitte um Expertenrat
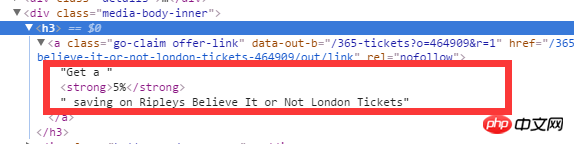


黄舟2017-05-24 11:37:18
之前的答案并没有针对楼主的问题,因为楼主没有将问题描述清楚,我想楼主想说的是直接用text() 方法或text属性得不到子标签内的内容(假设你已经看过了xpath的基本语法)。
Google搜索xpath get all text, 第一个就是答案。
楼主可以这样提问:xpath如何取出被标签包含的文字内容(虽然这里的答案并不能让人满意)
漂亮男人2017-05-24 11:37:18
你试试
response.xpath('//h3/a/descendant-or-self::text()[normalize-space()]')
descendant-or-self表明当前node和子代nodes
normal-space()去掉whitespace-only nodes的子代nodes(这个可要可不要)
参考链接:
http://stackoverflow.com/ques...
