- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
Nach dem Klicken auf die Download-Schaltfläche auf der Seite „http://www.chinadrugtrials.or…“ wird eine DOC-Datei heruntergeladen. Ich hoffe, dass die Datei derzeit automatisch heruntergeladen werden kann es lässt sich nicht öffnen
Persönlich dachte ich, dass es möglicherweise nicht möglich ist, den erhaltenen Inhalt direkt in eine Datei zu schreiben, oder dass es sich um ein Umleitungsproblem handeln könnte, aber nach einer Suche bei Google stellte ich fest, dass es keinen anderen Weg gab und die Suche nichts brachte bei der Dokumentation
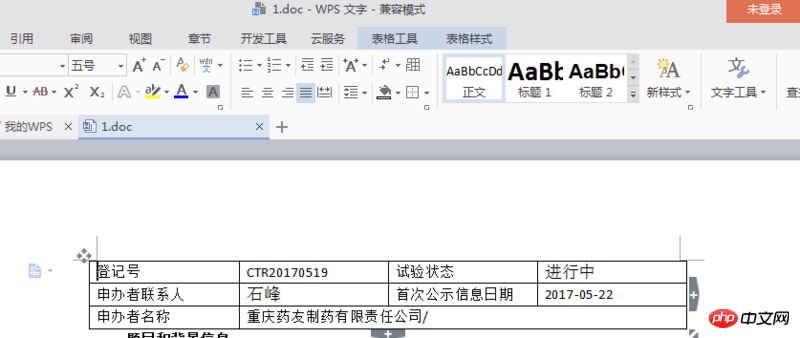
Das Folgende ist ein Screenshot der Webseite und der Download-Erklärung. Können Sie mir bitte helfen, herauszufinden, was schief gelaufen ist?
[Die Webseite sieht wie folgt aus] Wenn auf der Webseite nichts angezeigt wird, klicken Sie einfach auf die Abfrage in der oberen rechten Ecke, um die Informationen zu erhalten. Sie müssen sich nicht registrieren oder anmelden.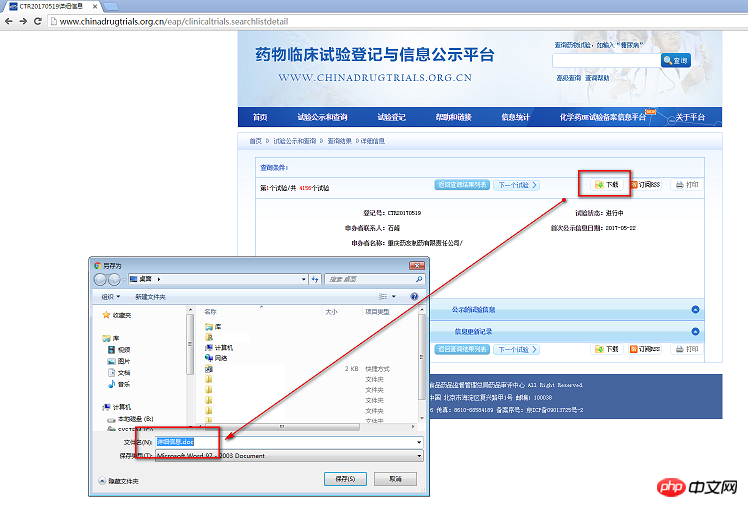
import requests
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36'}
url = 'http://www.chinadrugtrials.org.cn/exportdoc/clinicaltrials.searchlistdetail'
data = {'ckm_id': 'eda4593539334baea5f58828360d5dd8',
'ckm_index': 1,
'button2': ''}
ses = requests.session()
get = ses.post(url, headers=header, data=data)
with open('./1.doc', 'wb') as file:
file.write(get.content)
print('Done!')