
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
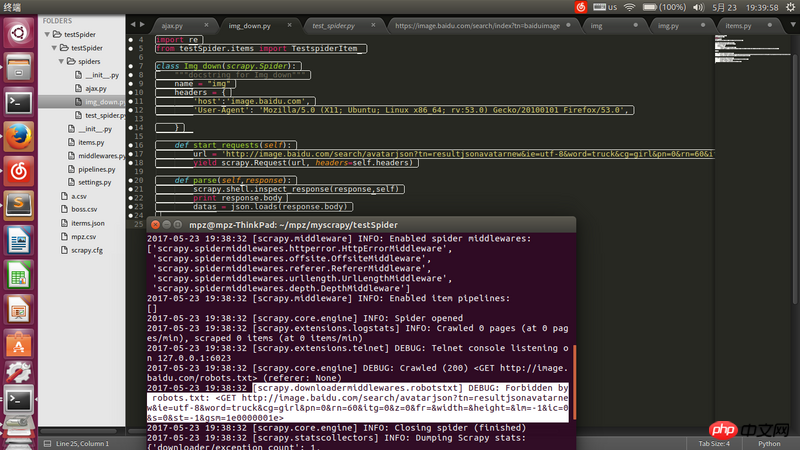
Die URL der Anforderungsadresse ist die über Firefox erhaltene JSON-Adresse. Sie kann mit einem Browser geöffnet werden, wurde jedoch beim Crawlen mit Scrapy gesperrt.
https://image.baidu.com/searc...
