- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
Ich möchte die Hausprofile separat erfassen und als unabhängige Spalten im Wörterbuch speichern, aber es gibt keine Möglichkeit, die Inline-Elemente direkt mithilfe einer for-Schleife zu extrahieren.
Das ist mein Code:
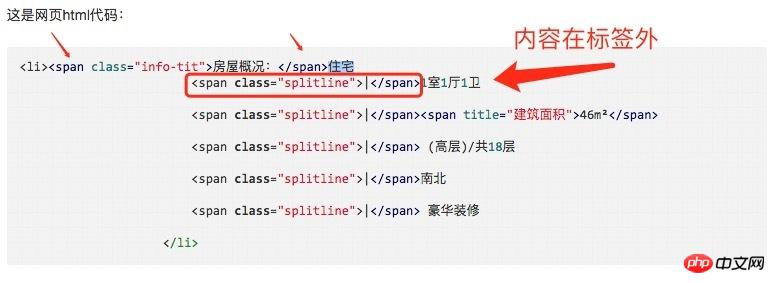
soup.select('.house-info li')[1].text.strip()Dies ist der HTML-Code der Webseite:
<li><span class="info-tit">房屋概况:</span>住宅
<span class="splitline">|</span>1室1厅1卫
<span class="splitline">|</span><span title="建筑面积">46m²</span>
<span class="splitline">|</span> (高层)/共18层
<span class="splitline">|</span>南北
<span class="splitline">|</span> 豪华装修
</li>曾经蜡笔没有小新2017-05-18 10:54:42
其实还是很有简单的,你看这个还是有规律的,规律在于有分隔符|,我写了个DEMO
something = '''<li><span class="info-tit">房屋概况:</span>住宅 <span class="splitline">|</span>1室1厅1卫<span class="splitline">|</span><span title="建筑面积">46m²</span><span class="splitline">|</span> (高层)/共18层
<span class="splitline">|</span>南北
<span class="splitline">|</span> 豪华装修
</li>''';
soup = BeautifulSoup(something, 'lxml')
plaintext = soup.select('li')[0].get_text().strip()通过get_text()得到内在所有内容,然后去除空格。后面你就用split进行分割吧,后面的不写了。
如果有问题再交流。

黄舟2017-05-18 10:54:42
用pyquery吧
from pyquery import PyQuery as Q
Q(text).find('.house-info li').text()