
- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
Ich habe einen kleinen Code geschrieben, um die Bilder im Blog Park zu crawlen. Dieser Code ist für einige Links wirksam, aber einige Links melden Fehler, sobald sie gecrawlt werden.
#coding=utf-8
import urllib
import re
from lxml import etree
#解析地址
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#获取地址并建树
url = "http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html"
html = getHtml(url)
html = html.decode("utf-8")
tree = etree.HTML(html)
#保存图片至本地
reg = r'src="(.*?)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl, '%s.jpg' % x)
x += 1Wie im Bild gezeigt, kann das Bild korrekt gecrawlt werden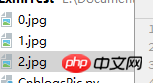
Wenn Sie die URL in
ändernurl = "http://www.cnblogs.com/baronzhang/p/6861258.html"Dann wird ein Fehler sofort gemeldet

Bitte lösen Sie es, danke!
我想大声告诉你2017-05-18 10:47:39
错误提示已经很明显了,你去看下网页源代码,匹配到的第一张图片是一个GIF格式的,并且还是相对路径,所以你是下载不到的,故提示IOerror,就算你下载到了,因为你指定了格式为JPG,你也打不开。 因此你需要做的就是判断和筛选
for imgurl in imglist:
if "gif" not in imgurl:
urllib.urlretrieve(imgurl, '%s.jpg' % x)
x += 1
看下我增加的地方,当然这只是最简单的判断,但可以保证你第二个程序不会报错,也是给你一个思路!