- Gemeinschaft
- Lernen
- Tools-Bibliothek
- Freizeit
Heim > Fragen und Antworten > Hauptteil
Beim Zugriff auf öffentliche WeChat-Kontoartikel unter Linux treten Verifizierungsprobleme auf! ! ! ! ! ! ! !
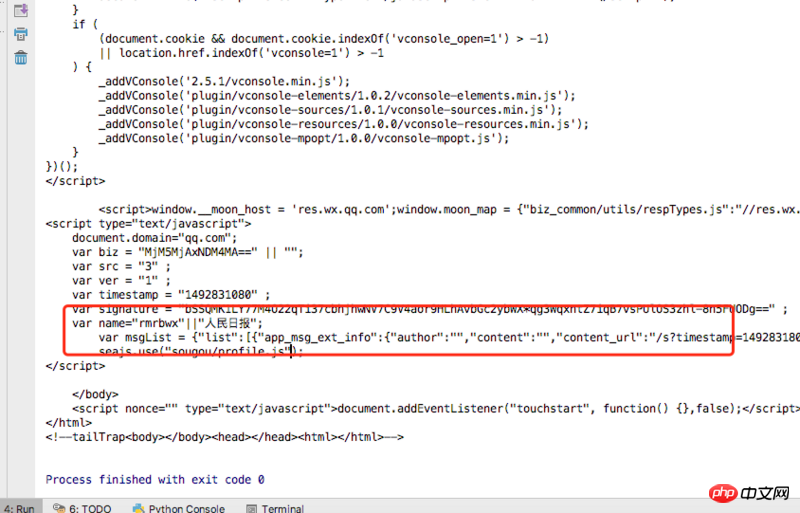
Das ist der Link zur People’s Daily, den ich mir schnappen möchte: http://mp.weixin.qq.com/profile?src=3×tamp=1492739045&ver=1&signature=bSSQMK1LY77M4O22qTi37cbhjhwNV7C9V4aor9HLhAvbGc2ybWX*qg3WqxntZ7iq0kvYe87oPpcSJKFdmGMx5g==
1: Zunächst einmal ist es normal, im Browser darauf zuzugreifen.
2: Die Zugriffsaufforderung unter Linux erfordert eine Überprüfung. Das Folgende ist ein einfacher Code
url = http://mp.weixin.qq.com/profile?src=3×tamp=1492738883&ver=1&signature=bSSQMK1LY77M4O22qTi37cbhjhwNV7C9V4aor9HLhAvbGc2ybWX*qg3WqxntZ7iq2xTLUTfxAMzK79UGvalY1A==
response = urllib2.urlopen(url)
print response.read()
1: Besuchen Sie zuerst den Link: http://weixin.sogou.com/weixi...
2: Holen Sie sich dann den Link zum offiziellen Konto von People's Daily springen.
某草草2017-05-16 13:35:44
# coding: utf-8
import requests
headers = {}
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
url = 'http://mp.weixin.qq.com/profile?src=3×tamp=1492739045&ver=1&signature=bSSQMK1LY77M4O22qTi37cbhjhwNV7C9V4aor9HLhAvbGc2ybWX*qg3WqxntZ7iq0kvYe87oPpcSJKFdmGMx5g=='
r = requests.get(url, headers=headers)
print r.text習慣沉默2017-05-16 13:35:44
import requests
headers = {'user-agent' : 'Mozilla/5.0'}
respon = requests.get('http://mp.weixin.qq.com/profile?src=3×tamp=1492831080&ver=1&signature=bSSQMK1LY77M4O22qTi37cbhjhwNV7C9V4aor9HLhAvbGc2ybWX*qg3WqxntZ7iqB7vsPUlOS3zhl-8n5FUODg==', headers = headers)
respon.encoding = 'utf-8'
print(respon.text)