



用的语言是python。目前想要爬的同花顺股票行情(http://q.10jqka.com.cn/stock/fl/#refCountId=db_5093800d_645,db_509381c1_860),又一次被javascript卡住。因为一页中只显示52条信息,想要看全部的股票数据必须点击下面的页码,是用javascript写的,无法直接用urllib2之类的库处理。试过用webkit(ghost.py)来模拟点击,代码如下:
page, resources = ghost.open('http://q.10jqka.com.cn/stock/fl/#refCountId=db_5093800d_645,db_509381c1_860')
page, resources = ghost.evaluate("document.getElementById('hd').nextSibling.getElementsByTagName('div')[13].getElementsByTagName('a')[7].click();", expect_loading = True)
提示Unable to load requested page, 或是返回的page是None。不知道无法解决。求教是代码哪里错了,应该如何解决?(在百度和google找了很久解决方法,不过有关ghost.py的资料不是太多,没能解决。)
以及,求问是否有更好的办法解决爬动态网页的问题?用webkit模拟好像会减慢爬的速度,不是上策。
回复内容:
Headless Webkit,开源的有 PhantomJS 等。能够解析并运行页面上的脚本以索引动态内容是现代爬虫的重要功能之一。
Google's Crawler Now Understands JavaScript: What Does This Mean For You?
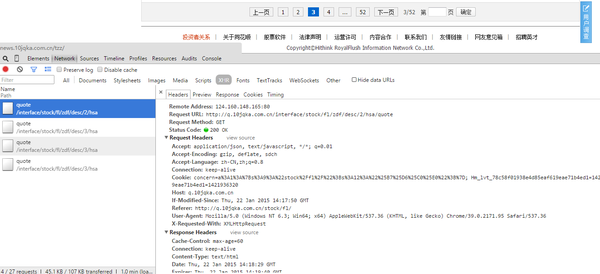

你这个爬虫跟JS关系不大,直接看Network,看发出的网络请求,分析每个URL,找出规律,然后用程序来模拟这样的请求,首先要善于用Chrome的Network功能,我们点几页,看Network如下:
第一页数据URL:
http://q.10jqka.com.cn/interface/stock/fl/zdf/desc/1/hsa/quote
我手上正好有个比较好的例子。需求:爬取爱漫画上的漫画。
问题:图片的名字命名不规则,通过复杂的js代码生成图片的文件名和url,动态加载图片。js代码的模式多样,没有统一的模式。
解决:Py8v库。读取下js代码,加一个全局变量追踪图片的文件名和url,然后Python和这个变量交互,取得某话图片的文件名和url。
全文在此
【原创】最近写的一个比较hack的小爬虫 能说 berserkJS 么……
不过这种玩意可抗不了量啊
╭(╯ε╰)╮ 嫌麻烦的话直接上selenium吧,几乎百分百地模拟用户在浏览器上的操作。也可以用来爬数据,不过速度较慢。 打开Chrome的开发人员控制台或者火狐的FireBug,转到Network那一栏,直接分析ajax访问的url到底是哪些。
对于特定网站的爬虫就不要想着模拟javascript运行了,太费力而且效果还不好。把网站的url结构弄明白了直接构造表单就好。 Selenium with Python 插一句题外话,同花顺好像可以自定义函数,写脚本计算数据,还是挺方便的,一定要自己把数据全部爬下来吗? phantomjs api比较吐血,建议基于之上封装的casperjs吧,写起来比较爽 一个好的爬虫需要解决两个问题:
1、能够解析动态网页,比如瀑布式网站
2、能够规避网站的封锁

 Ghost Spectre Windows 11 Superlite:下载和安装指南May 05, 2023 am 09:10 AM
Ghost Spectre Windows 11 Superlite:下载和安装指南May 05, 2023 am 09:10 AM由于系统要求不足,将操作系统更新到最新的Windows11给许多PC带来了挑战。因此,微软发布了修改版本,GhostSpectreWindows11Superlite,与每台PC兼容。因此,我们将讨论如何下载和安装它。同样,如果您的PC满足Windows11系统要求,您可以进一步阅读有关获取Windows11自定义ISO的信息。什么是幽灵幽灵视窗11?GhostSpectreWindows11是一个修改版本,称为LightWindows11。这是因为安装的
 推荐使用的三个适用于 Windows 11 的最佳自定义 ISO 文件Apr 22, 2023 pm 09:58 PM
推荐使用的三个适用于 Windows 11 的最佳自定义 ISO 文件Apr 22, 2023 pm 09:58 PM在Windows的上下文中,ISO文件是包含程序或操作系统的所有安装文件的东西。Microsoft已在其网站上为想要创建可启动安装媒体的人提供了Windows11的ISO版本。您可以将这些文件保存到闪存驱动器或DVD中,然后将它们带到计算机上安装或使用它创建虚拟机。但是互联网上有些人创建了自定义的ISO文件。什么是自定义ISO文件?有些人发现Windows11有很多不必要的文件和应用程序,这些文件和应用程序只会减慢操作系统的速度。至少对于这些人来说,Windows11
 ghost win10哪个最好?最好用的win10 ghost版本下载Feb 12, 2024 pm 11:40 PM
ghost win10哪个最好?最好用的win10 ghost版本下载Feb 12, 2024 pm 11:40 PM哪个Win10Ghost纯净版最好相信是很多用户们都在询问的一个问题,Win10Ghost系统是一款非常实用的系统备份和还原工具,用户们要是想重装系统又不想丢失自己的数据和软件的话就可以使用到Ghost系统,下面就让本站来为用户们来仔细的介绍一下Ghostwin10最好用的系统版本下载地址分享吧。Ghostwin10最好用的系统版本下载在使用Windows操作系统的过程中,有时候我们需要对系统进行重装或者升级,但是又不想丢失自己的数据和软件,这时候就需要使用Ghost系统了。Ghost系统可以帮
 ghost安装器怎么用 小编教你安装ghost系统步骤Jan 11, 2024 pm 07:39 PM
ghost安装器怎么用 小编教你安装ghost系统步骤Jan 11, 2024 pm 07:39 PMghost系统是一种免费的安装系统,之所以受欢迎,是因为ghost系统安装后会自动激活,而且自动安装对应的硬件驱动,不仅节省时间,还给小白用户提供了便利,不过很多人不知道ghost系统镜像怎么安装,其实安装步骤很简单,下面,小编给大家分享安装ghost系统步骤。U盘装系统越来越流行,现在的启动盘功能非常强大,既可以自动安装ghost系统,也可以手动ghost安装系统,不过由于手动ghost方法比较复杂,很多人都不懂怎么安装,让用户郁闷不已,下面,小编给大家带来了安装ghost系统步骤。最近小编在
 es6数组怎么去掉重复并且重新排序May 05, 2022 pm 07:08 PM
es6数组怎么去掉重复并且重新排序May 05, 2022 pm 07:08 PM去掉重复并排序的方法:1、使用“Array.from(new Set(arr))”或者“[…new Set(arr)]”语句,去掉数组中的重复元素,返回去重后的新数组;2、利用sort()对去重数组进行排序,语法“去重数组.sort()”。
 JavaScript的Symbol类型、隐藏属性及全局注册表详解Jun 02, 2022 am 11:50 AM
JavaScript的Symbol类型、隐藏属性及全局注册表详解Jun 02, 2022 am 11:50 AM本篇文章给大家带来了关于JavaScript的相关知识,其中主要介绍了关于Symbol类型、隐藏属性及全局注册表的相关问题,包括了Symbol类型的描述、Symbol不会隐式转字符串等问题,下面一起来看一下,希望对大家有帮助。
 ghost属于常用的什么软件Feb 18, 2021 pm 05:57 PM
ghost属于常用的什么软件Feb 18, 2021 pm 05:57 PMghost属于常用的“数据备份与还原”软件。Ghost软件是美国赛门铁克公司推出的一款出色的硬盘备份还原工具,可以实现FAT16、FAT32、NTFS、OS2等多种硬盘分区格式的分区及硬盘的备份还原;俗称克隆软件。
 ghost如何还原系统Oct 17, 2023 pm 03:04 PM
ghost如何还原系统Oct 17, 2023 pm 03:04 PMghost还原系统步骤:1、 重新启动系统快速按F8进入DOS界面运行G.exe 进入GHOST界面,回车就会进入GHOST的操作界面;2.、选择菜单到 Local-Partition-From Image,选定后回车;3、提示选择需要还原的镜像文件;4、显示硬盘信息,不需要处理,直接回车;5、一般默认是还原第一个分区;6、进入GHOST 的操作界面等等。


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

Dreamweaver CS6
Visuelle Webentwicklungstools

PHPStorm Mac-Version
Das neueste (2018.2.1) professionelle, integrierte PHP-Entwicklungstool

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

