Der Roboterhund läuft gleichmäßig auf dem Yoga-Ball und sein Gleichgewicht ist ziemlich gut: 
Er kann verschiedene Szenen bewältigen, egal ob es sich um einen flachen Gehweg oder einen anspruchsvollen Rasen handelt, er kann Folgendes halten: 
Sogar Als Forscher einen Yogaball traten, kippte der Roboterhund nicht um: 
Der Roboterhund konnte auch beim Entleeren von Ballons das Gleichgewicht halten: 
Die obigen Demonstrationen erfolgen alle mit einfacher Geschwindigkeit, ohne Beschleunigungsverarbeitung.
- Papieradresse: https://eureka-research.github.io/dr-eureka/assets/dreureka-paper.pdf
- Projekthomepage: https://github.com/eureka- Forschung/DrEureka
- Titel des Papiers: DrEureka: Language Model Guided Sim-To-Real Transfer
Diese Forschung wurde gemeinsam von Forschern der University of Pennsylvania, NVIDIA und der University of Texas in Austin erstellt und ist vollständig Open Source. Sie schlugen DrEureka (Domain Randomized Eureka) vor, einen neuen Algorithmus, der LLM nutzt, um Belohnungsdesign und domänenrandomisierte Parameterkonfiguration zu implementieren, wodurch gleichzeitig eine Übertragung von Simulation auf Realität erreicht werden kann. Die Studie demonstriert die Fähigkeit des DrEureka-Algorithmus, neuartige Roboteraufgaben zu lösen, beispielsweise das Balancieren eines vierbeinigen Roboters und das Gehen auf einem Yogaball, ohne dass ein iteratives manuelles Design erforderlich ist. Im Zusammenfassungsteil der Arbeit erklärten die Forscher, dass die Übertragung von in Simulationen erlernten Strategien auf die reale Welt eine vielversprechende Strategie für den groß angelegten Erwerb von Roboterfähigkeiten sei. Simulation-zu-Realität-Ansätze basieren jedoch häufig auf der manuellen Gestaltung und Abstimmung von Aufgabenbelohnungsfunktionen und physikalischen Simulationsparametern, was den Prozess langsam und arbeitsintensiv macht. In diesem Artikel wird die Verwendung großer Sprachmodelle (LLMs) untersucht, um die Simulation zu einem realistischen Design zu automatisieren und zu beschleunigen. Jim Fan, einer der Autoren des Papiers und leitender Wissenschaftler bei NVIDIA, war ebenfalls an dieser Forschung beteiligt. Zuvor gründete Nvidia unter der Leitung von Jim Fan ein KI-Labor, das sich auf verkörperte Intelligenz spezialisierte. Jim Fan sagte: „Wir haben einem Roboterhund beigebracht, auf einem Yoga-Ball zu balancieren und zu laufen. Dies wurde vollständig in der Simulation durchgeführt und dann ohne Proben und ohne Feinabstimmung in die reale Welt übertragen und direkt ausgeführt.“ Das Gehen mit dem Yogaball ist für den Roboterhund besonders schwierig, da wir die Oberfläche des Hüpfballs nicht genau simulieren können. DrEureka kann jedoch problemlos eine große Anzahl simulierter realer Konfigurationen durchsuchen und dem Roboterhund ermöglichen um den Ball auf verschiedenen Terrains zu kontrollieren oder sogar seitwärts zu gehen! Im Allgemeinen wird die Migration von der Simulation zur Realität durch Domänen-Randomisierung erreicht, was ein langwieriger Prozess ist, bei dem Robotikexperten jeden Parameter im Auge behalten und manuell anpassen müssen 4 Solche hochmodernen LLMs verfügen über eine Menge eingebauter physikalischer Intuition, einschließlich Reibung, Dämpfung, Steifigkeit, Schwerkraft usw. Mit GPT-4 kann DrEureka diese Parameter geschickt anpassen und seine Argumentation gut erklären 》
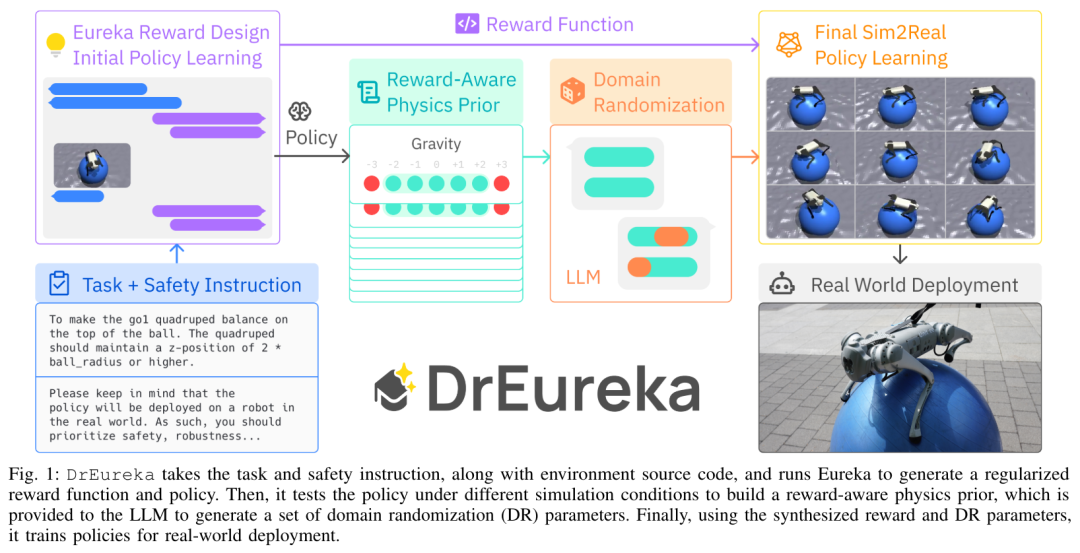
DrEureka-Prozess ist wie folgt: Er akzeptiert Aufgaben- und Sicherheitsanweisungen und Umgebungsquellcode und führt Eureka aus, um regulierte Belohnungsfunktionen und -richtlinien zu generieren. Anschließend wird die Strategie unter verschiedenen Simulationsbedingungen getestet, um einen belohnungsbewussten physischen Prior zu erstellen, der einem LLM zugeführt wird, um einen Satz von Domänen-Randomisierungsparametern (DR) zu generieren. Abschließend wird die Richtlinie mithilfe der synthetisierten Belohnungs- und DR-Parameter für die tatsächliche Bereitstellung trainiert. Eureka-Belohnungsdesign. Die Belohnungsdesignkomponente basiert aufgrund ihrer Einfachheit und Ausdruckskraft auf Eureka. In diesem Dokument werden jedoch einige Verbesserungen vorgestellt, um ihre Anwendbarkeit von der Simulation auf reale Umgebungen zu verbessern. Der Pseudocode lautet wie folgt: Belohnungsbewusste Physik vor (RAPP, belohnungsbewusste Physik vor). Sicherheitsbelohnungsfunktionen können das politische Verhalten regulieren, um Umweltentscheidungen festzulegen, reichen jedoch allein nicht aus, um einen Transfer von der Simulation in die Realität zu erreichen. Daher stellt dieses Papier einen einfachen RAPP-Mechanismus vor, um den grundlegenden Umfang von LLM einzuschränken. LLM wird für die Domain-Randomisierung verwendet. Angesichts des RAPP-Bereichs für jeden DR-Parameter weist der letzte Schritt von DrEureka LLM an, Domänen-Randomisierungskonfigurationen innerhalb der Grenzen des RAPP-Bereichs zu generieren. Siehe Abbildung 3 für den spezifischen Prozess: Diese Forschung verwendet Unitree Go1 für Experimente. Go1 ist ein kleiner vierbeiniger Roboter mit 12 Freiheitsgraden in seinen vier Beinen. In der vierbeinigen Fortbewegungsaufgabe bewertet dieser Artikel auch systematisch die Leistung von DrEureka-Richtlinien auf mehreren realen Terrains und stellt fest, dass sie robust bleiben und Richtlinien übertreffen, die mithilfe von Menschen entworfener Belohnungs- und DR-Konfigurationen trainiert wurden. Weitere Informationen finden Sie im Originalpapier. Das obige ist der detaillierte Inhalt vonMit dem „Hund' auf dem Yogaball spazieren gehen! Eureka, eines der zehn besten Projekte von NVIDIA, hat einen neuen Durchbruch geschafft. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!